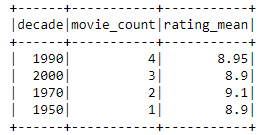Tableau has removed minimum purchase requirement from their licenses. The change has enabled Tableau to be deployed at very low cost and with exactly the number of users needed for each organisation.
In February 2021, Tableau announced that they will remove minimum user amount restrictions from their licensing. For example, earlier the Viewer license had a minimum sales volume of 100 users. The change has enabled Tableau to be deployed at very low cost and with exactly the number of users needed for each organisation.
The Tableau Creator license is intended for individuals who prepare data for their own or others’ use and publish content. With this license, user can take advantage of all Tableau’s capabilities from preparation, analysis, visualisation and publishing.
With the Tableau Explorer license, the user can create visualisations based on ready-made data models with a browser.
With the Tableau Viewer license, you can view and use published visualisations and dashboards interactively in a variety of ways based on given permissions.
At Solita, we see Tableau as a visualisation platform that gives our customers the best visibility into their data. We are the gold level partner of Tableau and through Solita you get licenses, commissioning, training, design and implementation work at a scale that suits your needs!
We will be happy to tell you more about Tableau and together we can build a solution that is the most suitable size for your organisation!
Contact:
Suvi Korhonen, Tableau Partnership Manager in Solita Finland /
Data Consultant
suvi.korhonen@solita.fi +358503096268
Tero Honko, Data Consultant
tero.honko@solita.fi
Phone +358405878359
Jenni Linna, Data Consultant / People Lead
jenni.linna@solita.fi
Phone +358440601244
Understanding your data is driving innovation and markets around the world. Leading companies leverage their data already so well that new products and services are fully built on data. Let's take a look at the hottest Azure service on the market Azure Purview. First let's see what the promise of the service is and then let's dive into the product itself.
Over the last few years, Microsoft has brought several different data solutions to the Azure platform, like Data Factory, Machine learning studio, Synapse, and now Azure Purview.
Azure Purview is a unified data governance service that helps you manage and govern your on-premises, multi-cloud, and software-as-a-service (SaaS) data. Easily create a holistic, up-to-date map of your data landscape with automated data discovery, sensitive data classification, and end-to-end data lineage. Empower data consumers to find valuable, trustworthy data. – Microsoft
Why Azure Purview?
What Azure Purview tries to solve is the data discovery and lay down the foundation for data governance. The business point is that everyone wants to know how data is connected between systems and where does the data come from. A very common issue in any organization.
Centralized place for all the metadata
Track and visualize data lineages
Search and find answers about your data
The core problem organizations have is a lack of data ownership. Cataloging data and having a full picture of how different sources are connected, will definitely provide better ownership and transparency. The solution works across on-premises, multi-cloud, and SaaS sources.
Currently, Purview can do three things:
Catalog:
Source registration, automated scanning, and classification and data discovery.
At the moment there is some limitation on what type of source you can register. The majority of Microsoft products are offered in the selection. There will be custom sources available later, this will grow very fast. (Snowflake, Oracle, Salesforce, etc.)
Business glossary and lineage and lineage visualization
This area lets you see where the data is coming from and how it is connected with different systems. For example, it is possible to connect Purview with Data Factory and Power BI, so you can see the whole lineage of how data is joined, transformed, and stored in different parts of the pipeline.
Data insights:
Catalog insights and sensitivity insights
Combining all the metadata that you have and providing analytics and classification. This is defiantly the most interesting part, where you can also label and group different parts of your data into a collection.
Getting started
The service is in preview, so don’t expect much. The ARM template can be found from here, There are not many things you can configure or change. If you want you can use the default parameters and deploy it to Europe west. Hopefully, there will be a similar Git integration like Data Factory has, till then source integrations will be done from the Azure portal.
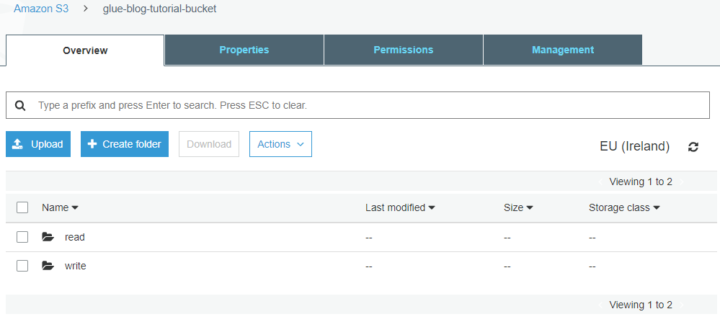
Now that we have deployed, let’s open up Azure Purview studio from Azure Portal.
Azure Purview landing page
Purview
Dive into the data and let’s see how things work. From the left side choose source, from their registry, from credentials, you can either choose to select a key vault and search for the secrets there, but as we previously did the managed identity we already have rights to access the storage account. The best thing is that you can’t type your passwords or other credentials into the portal, like in Data factory. It forces you to use a key vault. This is the beginning of an end to hardcoded credentials? Maybe, let’s hope so!
Source collection that can be created
Remember that whatever you choose as a source system, Purview requires a lot of rights. I like to call owner rights as God rights because it can select * from all tables, which is superuser rights.
Scanning
Now it gets interesting, some rules are applied by default. The list is long, so the more boxes you check the longer it will take to run your scan. This will help if you are working with sensitive data and want to make sure that you comply with the regulations. Creating a new rule, allows you to specify what you want to scan and what not.
Available sources
Remember, this isn’t a live connection. You either do a one time only scan or set a schedule. When running a scan you can do the full scan or incremental, which will search for the changes,
The assumption is that there will be some sort of an event-grid option in the future, where you can trigger scans based on data modifications.
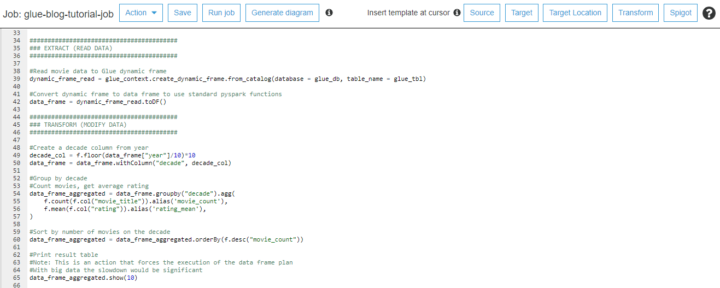
Glossary
This is the place where you create owners for the data. You can add people who have the domain understanding and who are working with the data and how it is connected to different resources. This is the thing you connect with the scanned data. What field relates to what data and what is the definition.
Browsing assets, example from Azure Sql server
Insights
I used two datasets, one is covid data and another one is credit data. The covid data didn’t automatically give any classifications, but credit data gave. Of course, you can do the classification yourself.
Asset insight
Summary
Considering the amount of data circling in different silos, this will improve data ownership and transparency. At the moment it’s not a production-ready solution but very promising.
Administration level rights that are needed will become a bottleneck for individuals who would like to connect to different sources. Even getting a connection to Power Bi requires Admin level rights.
This needs to be implemented into your data strategy and data governance model. Services like this will need planning, we at Solita have delivered more than +400 different data projects over +20 years. Ping me on Linkedin, more than happy to help your organization out!
You are looking at your data platform user adaptation rate, and it is not what you expected. Are you puzzled why aren’t people jumping on board the new, more efficient data tool and ready to leave the legacy system behind?
To know where you are at, ask yourself these questions:
When this project was started, did I spend time on getting to know my users?
Am I able to tell what is their skill level and how it matches the platform capabilities
Do I know what are the problems the users are trying to solve with their data tools?
Do I understand what motivates them?
If you don’t know the answers and have a clear picture of your potential crowd, there might be something you have left undone. No worries! Read on, as we present one tool to help you to drill into these questions.
Data development is too often based on presumptions
Back in the day, web services were often designed by developers, people writing the actual code. End-user needs were typically gathered from product specialists, sales or customer service. These people brought their presumptions of the end-users to the design. User insight driven UI design was only lifting its head.
Today, the situation is somewhat different. User insight and service design have been quite well internalized in digital service development. When designing a customer facing web service, no designer wants to lean on best guesses about the end-user’s needs. Designers want to understand and experience themselves what are the motivations and underlying needs of the user.
Data projects shouldn’t really differ from digital development but in their user approach, however, they are at the same level as web design was more than ten years back.
In data projects, what is under the hood counts often more than the surface. The projects tend to rely on assumptions on the users and to some very old organizational hearsay, instead of taking a systematic approach to user insight and service design.
The reasons for this vary. First, modern data platform development projects are a relatively new phenomena, data used to be in the hands of a smaller crowd before (typically skilled specialists from finance). Now that self-service analytics have become popular, also the users are becoming more diverse. Second, the data end-users are generally internal users. The same emphasis is not put in their user experience as for services facing an external customer. This should of course not be the case since you are also trying to convert them – to change their behavior towards being data driven in their decision-making.
This is where service design tools could really help you out. With some quite basic user insight you can make some very relevant findings and change the priorities of your project to ensure maximum adoption by the end users.
How can your data project benefit from a service design approach?
To give you some food for thought on how to benefit from service design, we have drafted you something based on our work on various data projects. This is only one example of what service design tools can do for you.
Our experience and discussions from different organizations have led us to believe that there are universal data personas that apply to most data organizations. They differ in how motivated they are to change their ways of working with data and how well they master modern data development and skills. These personas are meant to inspire you to turn your eyes upon your users.
User personas are a tool widely used in service design to make the users come alive and facilitate discussion about their needs.
So, we proudly present: The Wannabe, The Enabler, The Mastermind and The Skeptic.
THE WANNABE
The Wannabe is very excited about data and craves to learn more. Is a visionary but doesn’t really quite know how to get there. Has basic data skills but is eager to learn more and be more data driven in work.
Give this user support and in return, make them your data community builder. Let them spread their enthusiasm!
THE ENABLER
The Enabler is both capable and motivated. This user is well connected in the data community and sees the advantage of collaboration and shared ways of working brings.
Keep this user close. They are the change makers due to their position in the organization as well as their attitude. Allow them to help others to grow.
THE MASTERMIND
The Mastermind is the user who doesn’t reply to your emails or show up in your workshops. This user doesn’t really need anyone’s help with data, as they have the tools and the skills already. Not very motivated to share expertise either or get connected.
Make them need you by providing help to routine work. This user requires much effort but can result in significant value in return when you can channel their exceptional skills to serve your vision. To get to the Mastermind user, use the Enabler.
THE SKEPTIC
The Skeptic knows all the things that have been tried out in the past and also how many of these have failed. Is an organizational expert and has a long history with data but feels left out.
Use some empathy, spend time with this user and listen closely. If you tackle their problem, you have a strong spokesperson and an ally, because they know everyone and everything in the organization.
As said, sketching these user personas is just one example of using design tools to change your approach. There might be people who don’t fit these descriptions and people who act in different personas depending on the project in question. The idea is to make generalizations in order to make it possible to “jump into the users’ shoes” and make different point of views more concrete.
Make the data personas work for you
So, besides changing your approach to get to different data personas, what else can you do? How can you utilize the information the personas provide you?
First of all, you can start by mapping your services and tools to the needs, skills and expectations of the users. You might be surprised. How many of your users are skilled to use the services you provide? Five? Is this enough? What is the relevance of their work? Does their work serve a wider group of people?
Try out this matrix below for your data services. How does the potential for your services look now?
When building data platforms, you’re actually building services
It’s about time we twist our minds into thinking about people first in data projects; what is the change you wish to see in people’s behavior. To create value, your data platform needs the users as badly as your sales need customers buying their products.
So, stop thinking about data development projects technology first. Start thinking about them as a collection of services. Find out about the users and their needs and prioritize your development accordingly. In the end of the day, people performing better by making better decisions is what you’re after, not a shining data platform that sees no usage.
The data personas are a starting point for discussion. Link this post to your colleague and ask if they identify themselves. And how about you, are you the Wannabe, the Enabler, the Mastermind or the Skeptic?
Authors of this blog post are two work colleagues, who share the same interest in looking at data services from the user perspective. At least once, they have laughed out loud at the office in such volume, that it almost disturbed co-workers in the common space. They take business seriously and life lightly.
You can contact Tuuli Tyrväinen and Kirsi-Marja Kaurala via e-mail (firstname.lastname@solita.fi) for further discussion.
Agile Data Engine (ADE) is designed to work with a single target cloud data warehouse, but sometimes you need to keep some of your data in an on-premises environment for example for regulatory reasons. You might not be able to open connections to your on-premises infrastructure, but would like to keep both on-prem and cloud data warehouses managed in a single design infrastructure. Following is presented the high-level diagram of the environment in question. We are focusing on creating a system where ADE can be used to also develop an on-prem environment in addition to the main cloud data warehouse.
You have Azure Blob storage and Azure DevOps usable
Can be switched to other build and sharing locations quite easily
Reference architecture
In this blog post, we will go through a reference architecture where you have Azure as the cloud provider and SQL Server as the local database. The architecture presented here is not completely automated as it requires manual work at least in retrieving the SQL scripts from ADE. But as the on-premises system is secondary from the ADE development point of view, the number of objects should be small compared to the whole structure and developers can easily know what should be transferred to the on-prem environment.
NOTE: If you don’t want to create on-prem tables to the cloud data warehouse, keep them in a separate package that you don’t deploy.
The steps of the diagram are explained in the following chapters. The first step is in Retrieval of SQL from ADE, second and third in Correcting the data to be built to DACPAC, fourth and fifth in Building DACPAC, and lastly both sixth and seventh in Executing the DACPAC.
Retrieval of SQL from ADE
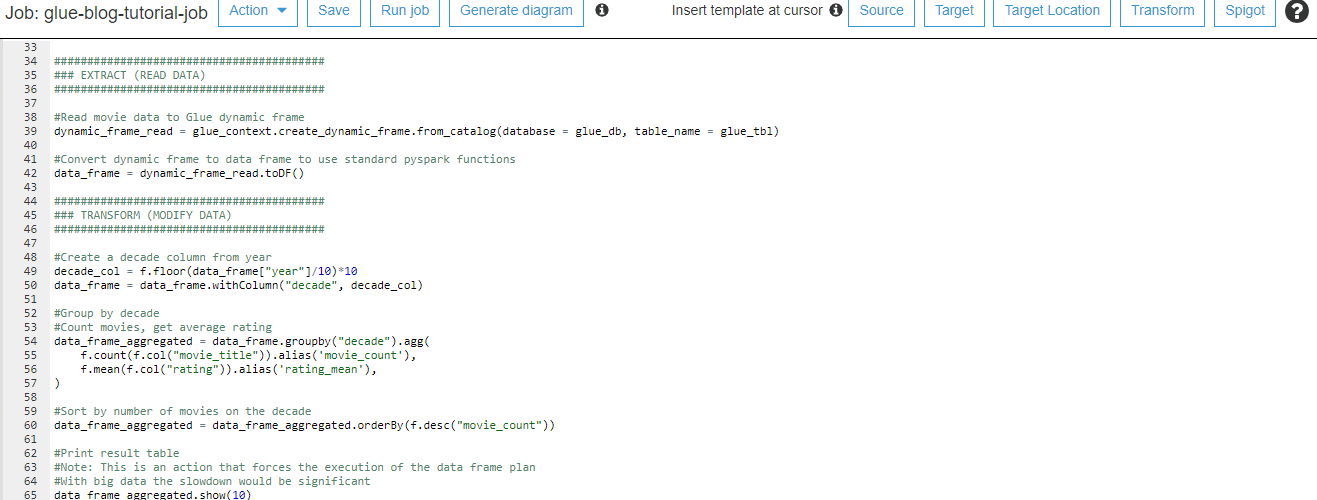
Normally ADE runs the necessary SQLs on your behalf to the target database in the correct SQL dialect. But, ADE also has a feature to export the SQL scripts in the same or different dialects for manual inspection and testing. This is possible because ADE stores metadata and creates the SQL scripts as the last step. We are using this feature to get SQL scripts in a different dialect than the cloud data warehouse. First, go to the entity page that you want to export. From the SQL export options select SQL Server and check the box to create procedure versions of the loads.
Copy the generated SQL to separate files that are named based on the table/view/load names. Keep the files in folders based on schema and type. See the following example folder structure.
ADE has a tagging functionality to help with managing large amounts of packages and entities inside the packages. Tags can be used to filter lists of both packages and entities. Tags are automatically created for words in description fields starting with a hashtag. In the hybrid situation, the tagging feature can be optionally used to mark which entities are deployed to on-prem and writing in the description field when the deploy was done.
Correcting the data to be built to DACPAC
Let’s start with a brief explanation of DACPAC. DACPAC is Microsoft data-tier application (DAC) package. It is meant to contain all database and instance objects used for an application. Database objects mean for example tables and view when the instance objects include users. In our use case, it is used to deploy database object changes to SQL Server by comparing the structure of DACPAC to the target database.
The creation of DACPAC is done by building the Visual Studio data-tier application defined by the project file and included SQL scripts. Small changes are needed to be made to SQLs generated by ADE and also to the project file for the DACPAC build to succeed with all necessary files.
SQL changes
DACPAC generation requires that all separate commands have GO commands between them. For field comments, ADE generates separate EXEC commands that need to be separated.
Project file changes
The *.sqlproj needs to be updated with new files and folders for them to be included in the DACPAC. This happens by adding under <ItemGroup> element a new <Folder Include=”<FOLDERPATH>” /> and <Build Include=”<FILEPATH>” />. In the case of SQLs being updated inside already existing files, no project file changes are needed.
Building is done in Azure DevOps using the MSBuild component. Then the required information is copied to the artifact folder for the upload step. The demo setup uses a bash script to upload to blob storage with a Shared Access Signature (SAS) token, but if possible AzureFileCopy component should be used.
NOTE: The SAS token should be stored separately from the pipeline in a secure variable, an environment variable is used for demo purposes.
There are two options for executing the DACPAC. One is for the developer to download the file from blob-storage and run it against the target database with for example Azure Data Studio (requires microsoft.schema-compare extension). This option requires that there is network connectivity to the target database for example through a VPN tunnel.
The second option is to have an execution tool in the on-prem environment like SSIS. The tool can download the blob file and execute it against the target database. It is recommended to have some kind of manual approval before running the file against the production database. In addition to normal production safety measures, the reason here is that DACPAC does not guarantee that it will do the same steps every time, instead it relies on the comparison between DACPAC and the target database.
Operations
The DDL transfer process can be used for transferring load steps as SQL Server procedures. As no on-prem connection was allowed from ADE in our use case, the load executing elements need to be found from the on-prem environment. One possibility for this is SSIS. The executor can be directed by configuration in a metadata table inside the target environment. The metatable has information on what procedures to run and when. The following sequence diagram explains at a high level the process of executing load steps.
Summary
In this blog post, we went through an example architecture of a hybrid EDW setup with the Agile Data Engine. We looked at the technical level on how to use SQL export functionality in Agile Data Engine and DACPAC to move DDL scripts from Agile Data Engine to on-prem SQL Server. The operations side depends heavily on the existing on-prem infrastructure and was, therefore, only lightly touched.
Building a resilient data capability can be a tricky task as there are vast number of viable options on how to proceed on the matter. Price and marketing materials don’t tell it all and you need to decide what is valuable for your organization when building a data platform.
Before going in to actual features and such I want to give few thoughts on cloud computing platforms and their native services and components. Is it always best to just stay platform native? All those services are “seamlessly integrated” and are easy for you to take into use. But up to which extent do those components support building a resilient data platform? You can say that depends on how you define a “data platform”.
My argument is that a data warehouse still is a focal component in enterprise wide data platform and when building one, the requirements for the platform are broader than what the platforms themselves can offer at the moment.
But let’s return to this argument later and first go through the requirements you might have for DataOps tooling. There are some basic features like version control and control over the environments as code (Infastructure as code) but let’s concentrate on the more interesting ones.
Model your data and let the computer generate the rest
The beef in classic data warehousing. Even if you call it a data platform instead of a data warehouse, build it on the cloud and use development methods that originate from software development, you still need to model your data and also integrate and harmonize it across sources. There sometimes is a misconception that if you build a data platform on the cloud and utilize some kind of data lake in it, you would not need to mind about data models.
This tends to lead to different kinds of “data swamps” which can be painful to use and the burden of creating a data model is inherited to the applications built on top of the lake.
Sure there are different schema-on-read type of services that sit on top of data lakes but they tend to have some shortcomings when compared to real analytical databases (like in access control, schema changes, handling deletes and updates, performance of the query optimizer, concurrent query limits, etc.).
To minimize the manual work related to data modelling, you only want the developers to do the required logical data modelling and derive the physical model and data loads from that model. This saves a lot of time as developers can concentrate on the big picture instead of technical details. Generation of the physical model also keeps it more consistent because there won’t be different personal ways in the implementation as developers don’t write the code by hand but it is automatically generated based to modelling and commonly shared rules.
Deploy all the things
First of all, use several separate environments. Developers need an environment where it is safe to try out things without the fear of breaking things or hampering the functionality of the production system. You also need an environment where production ready features can be tested with production-like data. And of course you need the production environment which is there only to serve the actual needs of the business. Some can cope with two and some prefer four environments but the separation of environments and automation regarding deployments are the key.
In the past, it has been a hassle to move data models and pipelines from one environment to another but it should not be like that anymore.
Continuous integration and deployment are the heart of a modern data platform. Process can be defined once and automation handles changes between environments happily ever after.
It would also be good if your development tooling supports “late building” meaning that you can do the development in a DBMS (Database Management System) agnostic way and your target environment is taken into account only in the deployment phase. This means that you are able to change the target database engine to another without too much overhead and you potentially save a lot of money in the future. To put it short, by utilizing late building, you can avoid database lock-in.
Automated orchestration
Handling workflow orchestration can be a heck of a task if done manually. When can a certain run start, what dependencies does it have and so on. DataOps way of doing orchestrations is to fully automate them. Orchestrations can be populated based on the logical data model and references and dependencies it contains.
In this approach the developer can concentrate on the data model itself and automation optimizes the workflow orchestration to fully utilize the parallel performance of the used database. If you scale the performance of your database, orchestrations can be generated again to take this into account.
The orchestrations should be populated in a way that concurrency is controlled and fully utilized so that things that can be ran parallel are ran so. When you add some step in the pipeline, changes to orchestrations should automatically be deployed. Sound like a small thing but in a large environment something that really saves time and nerves.
Assuring the quality
It’s important that you can control the data quality. At best, you could integrate the data testing in your workflows so that the quality measures are triggered every time your flow runs and possible problems are reacted to.
Data lineage can help you understand what happens with the data before it ends up in the use of end users.
It can also be a tool for the end users to better understand what the data is and where it comes from. You could also use tags for elements in your warehouse so that it’s easier to find everything that is related to for example personally identifiable information (PII).
Cloud is great but could it be more?
So about the cloud computing platforms. Many of the previously mentioned features can be found or built with native cloud platform components. But how about keeping at least the parts you heavily invest work in platform agnostic if at some point for some reason you have to make a move regarding the platform (reasons can be changes in pricing, corporate mergers & acquisitions, etc.). For big corporations it’s also more common that they utilize more than one cloud platform and common services and tooling over the clouds can be a guiding factor as well.
Data modelling especially is an integral part of data platform development but it still is not something that’s integrated in the cloud platforms themselves on a sufficient level.
In the past, data professionals have used to quite seamless developer experience with limited amount of software required to do the development. On cloud platforms this changed as you needed more services most having a bit different user experience. This has changed a bit since as cloud vendors have started to “package” the services (such like AWS Sagemaker or Azure DevOps) but we still are in the early phases of packaging that kind of tooling.
If the DataOps capabilities are something you would like to see out-of-the-box in your data platform, go check out our DataOps Platform called Agile Data Engine. It enables you to significantly reduce time to value from business perspective, minimize total cost of ownership and make your data platform future-proof.
This blog post will serve as an overview of the capabilities to give you insight on how to position Synapse Analytics to your overall data platform architecture. We won’t do a deep dive to technical implementation in this post.
Kirjoittaja:Mikko Sulonen Data Engineer
Kirjoittaja:Joni LuomalaData Architect, Azure Data Platform Tech Lead
Azure SQL capabilities have evolved a lot over the years. Azure offers everything from VMs for running your own SQL Server setup, to SQL DB Hyperscale where you are getting your extremely scalable, but still traditional, DB as a service. But what about massively parallel processing data warehousing? Data integrations? Data science? What about limitless analytics? For that, there’s Azure Synapse Analytics.
In November 2019 Microsoft announced Azure Synapse as limitless analytics service and the next evolution of SQL Data Warehouse. Only thing released in GA was re-naming of SQL DW. Other synapse features were only available in limited private preview and for most setting up Synapse Analytics meant setting up former SQL DW. Nowadays Azure Synapse Analytics is a name for the whole analytics service with former SQL DW being part of it. While writing this blog the former SQL DW (also known as Synapse SQL provisioned) is still the only thing in GA, rest of the features are in public preview and anyone can set up Synapse Analytics workspace. Yes, the naming is confusing but hang on, we will try to clear that for you.
This blog post will serve as an overview of the capabilities to give you insight on how to position Synapse Analytics to your overall data platform architecture. We won’t do a deep dive to technical implementation in this post.
Synapse Analytics Architecture
Note: At the moment of writing this blog, Synapse Analytics can refer to both “Synapse Analytics (formerly SQL DW)” and “Synapse Analytics (workspace preview)” in Azure documentation. Here we are talking about unified experience in the workspace preview.
Azure Synapse Analytics is the common naming for integrated tooling providing everything from source system integration to relational databases to data science tooling to reporting data sets. Synapse Analytics contains the following
Synapse SQL
This is the data warehouse part formerly known as Azure SQL DW.
Provides both serverless (SQL on-demand) and pre-allocated (SQL Pool) resources
Shares a common metastore with the Spark engine for seamless integration
Apache Spark
Seamlessly integrated big data engine.
Shares a common metastore with Synapse SQL
Data Flow and Integrations
Shares codebase with Azure Data Factory, so has everything you expect and more
Integrate to nearly a hundred data sources to ingest data
Orchestrate SQL Procedures and Spark Notebooks
Management and Monitoring
Familiar management and monitoring tools from Azure Data Factory are available.
Synapse Studio
Single web UI where you can create everything:
Integrate to source systems
Land data to Azure Data Lake
Explore the data using Spark notebooks
Load data to Synapse SQL using T-SQL scripts
Predict what needs predicting using Python, Scala C# or SQL in Spark
Publish data sets to Power BI
Manage and orchestrate everything with pipelines
In conclusion, Synapse Analytics refers to all of the capabilities available to you and not a single included tool. Synapse SQL, as the name suggests, is perhaps the most recognizable part with the SQL DW and T-SQL. However, Synapse Analytics also contains a serverless SQL form factor named SQL On-demand. So using T-SQL no longer requires a provisioned SQL Pool.
Synapse Analytics Unique value proposal
By unifying all of the tools mentioned above, Synapse Analytics really brings something new to the table. Using Synapse Analytics you can, without ever leaving the Synapse Studio, connect to a new on-premises data source, extract, load and transform that data to Data Lake and Synapse SQL, enrich it further with ML models, and provide it for reporting usage.
Synapse Analytics provides capabilities for each of the steps in a data pipeline: ingestion, preparing data, storing, exploring, transforming and serving the data:
Ingest
If you have previously used Azure Data Factory, you will be right at home using the data integration tools in Synapse Analytics. Synapse Analytics even shares the same codebase with Data Factory, so everything you have grown accustomed to is already there (almost everything, you can check the complete differences from https://docs.microsoft.com/en-us/azure/synapse-analytics/data-integration/concepts-data-factory-differences). You can use an Integration Runtime running inside your on-premises network to access all your data sources inside your network, or an Azure hosted one for massive scale. The list of natively supported systems is constantly growing, and you can find up-to-date information from https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-overview#supported-data-stores-and-formats. And if your source system is not on the list, you can always use a self hosted integration runtime with ODBC or JDBC drivers.
Despite their similarities, there’s currently no tooling to migrate ADF pipelines to Synapse Analytics Pipelines, and you can’t use the same Integration Runtime for both ADF and Synapse Analytics.
Another interesting preview feature is Azure Synapse Link. It allows you to run analytical workloads on top of operational data in Azure Cosmos DB near real time without affecting the operational usage. This means that application data in Cosmos DB is available for Synapse SQL and Spark using cloud native HTAP without building ETL workflows. https://docs.microsoft.com/en-us/azure/cosmos-db/configure-synapse-link
Prepare
After connecting to your data source, you can extract your data to Azure. There are numerous ways to organize the data in the data lake. Generally, you’ll probably want to have the original untouched data in a “raw” area, and processed and more refined data in another area.
With the new COPY INTO T-SQL command, you can use gzipped csv format to reduce the storage footprint. If using csvs, it is advisable to split large files into smaller ones, depending on your DWU capacity. And finally, you don’t have to worry about the 1 MB row limit and hard coded separator values as with PolyBase.
To really leverage all the possibilities of Synapse Analytics, you should use the parquet format in your data lake. In addition to being a compressed format, using parquet supports predicate pushdown in Synapse SQL and Spark. This greatly speeds up your exploratory queries to data lake from Synapse SQL or Spark, as you don’t have to read all the files from a given folder structure to get the rows you want. With parquet, the COPY INTO command automatically splits your files to speed up the processing.
Using Data Flows to clean and unify your data
Data Flows provide a no-code approach to transforming your data. As integrations, Data Flows are also already familiar from Azure Data Factory. With Data Flows, you could for example combine a few columns, delete a redundant one, calculate a working unique identifier and join the data with another flow before storing back to Data Lake as a processed file and also persisting it to SQL Pool table.
Explore data
Synapse Studio gives you multiple options to explore your data. We can graphically view the data lake structure, and easily get a SQL script or Spark Notebook to view the file contents just by right clicking a file.
With SQL On-demand, you can explore the contents of files without moving or importing them anywhere, and generate simple graphs in Synapse Studio UI to give you an idea of what you are looking at.
Synapse SQL, both on-demand and provisioned can be connected outside Synapse Studio with different clients using application protocols like ODBC, JDBC and ADO.NET.
In Apache Spark (example in Scala), using data from the SQL Pool is as easy as:
%%spark
val df = spark.read.sqlanalytics("SQLPool.schema.table")
This doesn’t require any configurations on Spark’s side, as the Spark and SQL are just two different runtimes operating on the same metadata and data sources.
Transform and enrich data
For transforming and enrichment, Synapse Analytics offers Spark Notebooks in addition to T-SQL. However, it has already been pretty easy to add Databricks notebooks as a part of your Azure Data Factory pipelines. With Synapse Analytics, again this integration is a bit more ready-made and easier.
One interesting possibility is SQL On-demand and it’s external tables. SQL On-demand doesn’t get access to SQL Pool’s tables (as you don’t even need to provision a SQL Pool or Synapse SQL to use SQL On-demand), but you can create external tables using T-SQL. External tables are stored as parquet backed files in Azure Data Lake Storage Gen 2. Compared to the current Azure General Availability offering, moving towards SQL On-demand and external tables in your transformations, offers serverless and fully scalable architecture. What’s the performance of external tables and SQL On-demand is going to be like, remains to be seen.
Serve
Synapse Analytics offers a few new interesting features for serving enriched data: SQL On-demand and Power BI Service connection.
With SQL On-demand, it is possible to create a highly scalable data pipeline all the way from source systems to transforming and storing data to serving it to Power BI, without any predetermined service level or capacity choices:
Ingest and Transform data using Data Pipelines and Data Flow. Use SQL On-demand or Data Flow as a part of your pipeline where needed
Store the results with “CETAS”, a T-SQL command CREATE EXTERNAL TABLE AS SELECT to store the results of your final SELECT statement to Azure Data Lake Storage Gen 2
Create a data set in Power BI. You can either use the files directly or use Direct Query via SQL On-demand.
Lastly, Synapse Analytics has the capability to link to Power BI Service! You can create linked services with Power BI Workspaces, view datasets and also create Power BI reports without ever leaving Synapse Studio. This greatly simplifies the process of creating reports from new data.
Do note that at the moment, you can only link to ONE Power BI Workspace. After connecting to a Power BI Workspace, you can create new Power BI reports based on published data sets without leaving Synapse Studio.
Manage and orchestrate
For orchestrating your pipelines, Synapse Analytics offers pretty much the same tooling as Azure Data Factory. You can easily combine your Data Flows, Spark Notebooks, T-SQL queries and everything to form pipelines as in Azure Data Factory. The familiar triggers are also there.
Management views also share much of the same as Azure Data Factory.
Synapse Analytics excels
Synapse Analytics strengths lie in it’s unified and yet versatile tooling.
Starting a new data platform project
Synapse Analytics offers an unified experience creating ingestion, preparation, transformations and serving your data in one place
Architecture with Data Lake
Synapse Analytics’s unified tooling makes it easier to work with and explore Data Lake
Architecture with Cosmos DB (or other future possible Synapse Link sources)
Near-real-time analytics based on operative data sources without any manual ETL processes
Explorative work on unknown data
Many tools and languages in one place
Security management in Synapse Workspace
Instead of setting up and configuring multiple separate tools with authentications and networks between them, you have only the Synapse Analytics workspace to setup
Possibility for both no-code and code approaches
A suitable approach probably exists for many developers to get started
Synapse SQL Pool as an MPP database
Synapse SQL is a powerful database in it’s own right
What we wish to see in future updates
While Synapse SQL Pool does pack a punch, it does require dba work and manual maintenance. Maybe more automation regarding this in the future?
Different indexes, partitions and distributions will have an impact on performance and storage costs
Workload management: classification, importance, isolation all need to be planned for and addressed for full scale operations
More dynamic resource scaling
Scaling Synapse SQL is an offline operation
While SQL On-demand offers some exciting possibilities, it fails to deliver any database functionalities: no access to relational tables for example as it doesn’t require a SQL Pool. There are parquet backed external tables, but their performance remains to be seen
Development in the Spark-sector as Synapse’s Spark is not on par with Databricks
For example, one notebook locks one Spark pool
Different runtime versions compared to Databricks
Implementation of version control
There’s no GIT or any other version control system support. The only way to save work is to publish, which also makes it visible to all other developers.
Managing different environments without version control system requires the use of SDK or APIs, which means a lot of work to get production ready
Getting from preview to GA
There still are instabilities and UI issues. The usual Preview shenanigans which are hopefully taken care of before moving to general availability.
Conclusion
In conclusion, Synapse Analytics’s vision is a great one: unified tool and experience to create almost everything you require in Azure to get your data from a data source to a published report. At the moment, there are some drawbacks as the whole workspace experience is still in preview, of which the lack of version control is definitely not the smallest.
At this point, we haven’t made any performance analysis and it is too early to say, if Synapse Analytics can really be a silver bullet for combining data pipelines, warehousing and analytics. In addition to performance, some key unique features are somewhat handicapped at this point: for example you can only connect to one Power BI Workspace. The vision is definitely there, and we will be anxiously waiting for future updates.
This tutorial is a hands-on tutorial for Snowflake external functions and shows how you can translate and categorize your Snowflake data using Amazon Translate and Amazon Comprehend services. This tutorial will translate Finnish product comments to English and analyze them.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
This the second part of the external functions blog post series and teaches how you can trigger Amazon services like Translate and Comprehend using Snowflake external functions. I will also explain and go through the limits of external functions in this blog post.
In the first blog post, I taught how you can set up your first Snowflake external function and trigger simple Python code inside AWS Lambda. In case external functions are a new concept for you, I suggest reading the first blog post before diving into this.
External functions limitations
Previously I left the limitations of external functions purposely out, but now when we are building something actually useful with them, you should understand the playground what you have and what are the boundaries.
Let’s start with the basics. As all the traffic is going through AWS API Gateway, you’re bound to the limitations of API Gateway. Max payload size for AWS API Gateway is 10MB and that can’t be increased. Assuming that you will call AWS Lambda through API Gateway, you will face the Lambda limits, which are maxed to 6MB per synchronous requests. Depending on the use-case or the data pipeline you’re building, there are workarounds, for example, ingesting the raw data directly through S3.
Snowflake also sets limitations; for example, the remote service at a cloud provider, in our case AWS, must callable from a proxy service. Limitations include that external functions must be scalar functions which mean single value for each input row. It doesn’t though mean that you can’t process only one row at the time. The data is sent as a JSON body which can contain multiple “rows”. Additional limitations set by Snowflake is that Snowflake optimizer can’t be used with external functions, external functions can’t be shared through Secure Data Sharing and you can’t use them in DEFAULT clause of a CREATE TABLE statement or with COPY transformations.
Things to consider
The cloud infrastructure, AWS in this case, sets also limitations or rather things to consider. How does the underlying infrastructure handle your requests? You should think how your function scales, acts on concurrency cases and how reliable it is. Doing a simple function which is called by a single developer usually functions without any issues, but you must design your function in a way that it works with multiple developers who are calling the function numerous times within hour contrasted to the single call which you made during development.
Concurrency is an even more important issue as Snowflake can parallelize external function calls. Can the function you wrote handle multiple parallel calls at once or does it crash? Another thing to understand is that with multiple parallel calls, you end up in a situation where the functions are in different states. This means that you should not write function where the result depends upon the order in which user’s rows are processed.
Error handling is also a topic which should not be forgotten. Snowflake external functions understand only HTTP 200 status code. All other status codes are considered as an error. This means that you need to build the error-handling to the function itself. External functions also have poor error messages as stated above. This means that you need to log all those “other than 200 status codes” to somewhere for later analysis.
Moneywise you’re also on the blindside. Calling out Snowflake SQL function hides all the costs what are related to the AWS services. An external function which is implemented poorly can lead to high costs.
Example data format
External functions call the resources by issuing HTTP POST request. This means that the sent data must be in a specific format to work. The returned data must also conform to a specific format. Due to these factors, the data sent and returned might look unusual. For example, we must always send integer value with the data. This value appears as a row number for the 0-based index. The actual data is converted to JSON data types, i.e.
Numbers are serialized as JSON numbers.
Booleans are serialized as JSON booleans.
Strings are serialized as JSON strings.
Variants are serialized as JSON objects.
All other supported data types are serialized as JSON strings.
It’s essential also to recognise that this means that dates, times, and timestamps are serialized as strings. Each row of data is a JSON array of one or more columns and can sent data can be compressed COMPRESSION syntax with CREATE EXTERNAL FUNCTION -SQL clause. It’s good to though understand that Amazon API Gateway automatically compresses/decompresses requests.
What are Amazon Translate and Amazon Comprehend?
As Amazon advertises, Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation. What does that truly mean? It means that AWS Translate is a fully automated service where you can transmit text data to Translate API and you get the text data translated back in the chosen language. Underneath the hood, Amazon uses its own deep learning API to do the translation. In our use case, Amazon Translate is easy to use as the Translate API can guess the source language. Normally you would force the API to translate text from French to English, but with Translate API, we can set the source language to ‘auto’ and Amazon Translate will guess that we’re sending them French text. This means that we only need minimal configuration to get Translate API to work.
Amazon Translate can even detect and translate Finnish language, which is sometimes consider a hard language to learn.
For demo purposes Translate billing is also a great fit, as you can translate 2M characters monthly in your first 12 months, which start from your first translation. After that period the bill is 15.00$ per million characters.
Amazon Comprehend is also a fully managed language processing (NLP) service that uses machine learning to find insights and relationships in a text. You can use your own models or use built-in models to recognize entities, extract key phrases, detect dominant languages, analyze syntax, or determine sentiment. Like Amazon Translate, the service is called through an API.
As Finnish is not supported language for Amazon Comprehend, the translated text is run through the Comprehend API to get insights.
Example – Translating product comments made in Finnish to English with Amazon Translate and Snowflake external functions
As we have previously learned how to create the connection between Snowflake and AWS, we can focus on this example on the Python code and external function itself which is going to trigger the Amazon Translate API. As with all Amazon services, calling Translate API is really easy. You only need to import the boto3 class and use the client session to call the translate service.
After setting up the translate, you call the service with a few mandatory parameters and you’re good to go. In this example, we are going to leverage the Python -code, which was used in the previous blog post.
Instead of doing simple addition of string to the input, we’re going to pass the input to Translate API, translate the text to English and get the result back in JSON -format for later use. You can follow the instructions in the previous example and replace the Python -code with this new code stored in my Github -account.
After changing the Python -code, we can try it right away, because the external function does not need any change and data input is done in the same way as previously. In this case, I have created a completely new external function, but it works in a similar way as previously. I have named my Lambda -function as translate and I’m calling it with my Snowflake lambda_translate_function as shown.
Calling the function is easy as we have previously seen, but when we call the Translate API directly we will the get full JSON answer which contains a lot of data which we do not need.
Because of this, we need to parse the data and only fetch the translated text.
As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
Example – Categorizing product comments with Amazon Comprehend and Snowflake external functions
Extending the previous example, we have now translated the Finnish product comment to English -language. We can extend this furthermore by doing sentiment analysis for the comment using Amazon Comprehend. This is also straight forward job and requires only you to either create a new Python function which calls the Comprehend API or modify the existing Python code for demo purposes.
To detect sentiment we use the similarly named sub-class and provide the input source language and text to analyze. You can use the same test data which was used with Translate demo and with the first blog. Comprehend will though give NEUTRAL -analysis for the test data.
Before heading to Snowflake and trying out the new Lambda -function, go to IAM -console and grant enough rights for the role that Lambda -function uses. These rights are used for demo purposes and ideally only read rights for DetectSentiment action are enough.
These are just example rights and do contain more than are needed.
Once you have updated the IAM role rights, jump into the Snowflake console and try out the function in action. As we want to stick with the previous demo data, I will translate the outcome of the previous translation. For demo purposes, I have left out the single apostrophe as those are used by Snowflake.
As you can see, getting instant analysis for the text was right. To be sure that we getting correct results, we can test out with new test data i.e. with positive product comment.
As you can, with Snowflake external functions it’s really easy to leverage Machine Learning, Natural Language Processing or AI -services together with Snowflake. External functions are new feature so this means that this service will only grow in the future. Adding Azure and Google compatibility is already on the roadmap, but in the meantime, you can start your DataOps and MLOps journey with Snowflake and Amazon.
This tutorial is a hands-on Hello World introduction and tutorial to external functions in Snowflake and shows how to trigger basic Python code inside AWS Lambda
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
External functions are new functionality published by Snowflake and already available for all accounts as a preview feature. With external functions, it is now possible to trigger for example Python, C#, Node.js code or native cloud services as part of your data pipeline using simple SQL.
I will publish two blog posts explaining what external functions are in Snowflake, show how to trigger basic Hello World Python code in AWS Lambda with the result showing in Snowflake and finally show how you can trigger Amazon services like Translate and Comprehend using external functions and enable concrete use cases for external functions.
In this first blog post, I will focus on the showing on how you can set up your first external function and trigger Python code which echoes your input result back to Snowflake.
What external functions are?
At the simplest form, external functions are scalar functions which return values based on the input. Under the hood, they are much more. Compared to traditional scalar SQL function where you are limited using SQL, external functions open up the possibility to use for example Python, C# or Go as part of your data pipelines. You can also leverage third-party services and call for example Amazon services if they support the set requirements. To pass the requirements, the external function must be able to accept JSON payload and return JSON output. The external function must also be accessed through HTTPS endpoint.
Example – How to trigger AWS Lambda -function
This example follows instructions from Snowflake site and shows you in more detail on how you can trigger Python code running on AWS Lambda using external functions like illustrated below.
To complete this example, you will need to have AWS account where you have the necessary rights to create AWS IAM (Identity and Access Management) roles, API Gateway endpoints and Lambda -functions. You will need also a Snowflake ACCOUNTADMIN -privileges or role which has CREATE INTEGRATION rights.
These instructions consist of the following chapters.
Creating a remote service (Lambda Function on AWS)
Creating an IAM role for Snowflake use
Creating a proxy service on AWS API Gateway.
Securing AWS API Gateway Proxy
Creating an API Integration in Snowflake.
Setting up trust between Snowflake and IAM role
Creating an external function in Snowflake.
Calling the external function.
These instructions are written for a person who has some AWS knowledge as the instructions will not explain the use of services. We will use the same template as the Snowflake instruction to record authentication-related information. Having already done a few external function integrations, I highly recommend using this template.
Cloud Platform (IAM) Account Id: _____________________________________________
Lambda Function Name...........: _____________________________________________
New IAM Role Name..............: _____________________________________________
Cloud Platform (IAM) Role ARN..: _____________________________________________
Proxy Service Resource Name....: _____________________________________________
Resource Invocation URL........: _____________________________________________
Method Request ARN.............: _____________________________________________
API_AWS_IAM_USER_ARN...........: _____________________________________________
API_AWS_EXTERNAL_ID............: _____________________________________________
Creating a remote service (Lambda Function on AWS)
Before we create Lambda function we will need to obtain our AWS platform id. The easiest way to do this is to open AWS console and open “Support Center” under “Support” on the far right.
This will open a new window which will show your AWS platform id.
Record this 12-digit number into template shared previously. Now we will create a basic Lambda -function for our use. From the main console search Lambda
Once you have started Lambda, create a new function called snowflake_test using Python 3.7 runtime. For the execution role, select the option where you create a new role with basic Lambda permissions.
After pressing the “Create function” button, you should be greeted with the following view where you can paste the example code. The example code will echo the input provided and add text to confirm that the Snowflake to AWS connection is working. You can consider this as a Hello World -type of example which can be leveraged later on.
Copy-paste following Python code from my Github account into Function code view. We can test the Python code with following test data which should create following end result:
After testing the Lambda function we can move into creating an IAM role which is going to be used by Snowflake.
Creating an IAM role for Snowflake use
Creating an IAM role for Snowflake use is a straight forward job. Open up the Identity and Access Management (IAM) console and select “Roles” from right and press “Create role”.
You should be greeted with a new view where you can define which kind of role you want to create. Create a role which has Another AWS account as a trusted entity. In the box for Account ID, give the same account id which was recorded earlier in the instructions.
Name the new role as snowflake_role and record the role name into the template. Record also the role ARN.
Creating a proxy service on AWS API Gateway
Create an API Gateway endpoint to be used. Snowflake will use this API endpoint to contact the Lambda -service which we created earlier. To create this, choose API Gateway service from the AWS console and select “Create API”. Call this new API snowflake_test_api and remember to select “Regional” as the endpoint type as currently, they are the only supported type.
Create a Resource for the new API. Call the resource snowflake and record the same to the template as Proxy Service Resource Name.
Create Method for the new API from the “Actions” menu, choose POST and press grey checkmark to create.
During the creation choose Lambda Function as Integration type and select “Use Lambda Proxy Integration”. Finally, choose the Lambda function created earlier.
Save your API and deploy your API to a stage.
Creating a new stage can be done at the same time as the deploy happens.
Once deployed, record the Invoke URL from POST.
Now were done creating the API Gateway. Next step is to secure the API Gateway that only your Snowflake account can access it.
Securing AWS API Gateway Proxy
In the API Gateway console, go to your API method and choose Method Request.
Inside Method Request, choose “AWS_IAM” as the Authorization mode.
Record the Method Request ARN to the template to be used later on. You can get the value underneath the Method Request.
Once done, go to Resource Policy and deploy the following policy from my Github account. You can also copy the policy from the Snowflake -example. In AWS Principal, replace the <12-digit number> and <external_function_role> with your AWS platform id and with IAM role created earlier. In AWS Resource, replace the resource with the Method Request ARN recorded earlier. Save the policy once done and deploy the API again.
Creating an API Integration in Snowflake
Next steps will happen on the Snowflake console, so open up that with your user who has the necessary rights to create the integration.
With necessary rights type in following SQL where <cloud_platform_role_ARN> is the ARN of the IAM role created previously and api_allowed_prefixes is the resource invocation URL.
CREATE OR REPLACE API INTEGRATION snowflake_test_api
api_provider = aws_api_gateway
api_aws_role_arn = ‘<cloud_platform_role_ARN>’
enabled = true
api_allowed_prefixes = (‘https://’)
;
The end result should like something like this
When done, obtain API_AWS_IAM_USER_ARN and API_AWS_EXTERNAL_ID values by describing the API.
Setting up trust between Snowflake and the IAM role
Next steps are done in the AWS console using the values obtained from Snowflake.
In the IAM console, choose the previously created role and select “Edit trust relationships” from “Trust relationships” -tab.
In Edit Trust Relationships modify the Statement.Principal.AWS field and replace the value (not the key) with the API_AWS_IAM_USER_ARN that you saved earlier.
In the Statement.Condition field Paste “StringEquals”: { “sts:ExternalId”: “xxx” } between curly brackets. Replace the xxx with API_AWS_EXTERNAL_ID. The final result should look something like this.
Update the policy when done and go back to the Snowflake console.
Creating an external function in Snowflake
In Snowflake create the external function as follows. The <api_integration name> is the same we created previously in the Snowflake console. The <invocation_url> is the resource invocation URL saved before. Include also the resource name this time.
CREATE EXTERNAL FUNCTION my_external_function(n INTEGER, v VARCHAR)
RETURNS VARIANT
API_INTEGRATION = <api_integration_name>
AS ‘<invocation_url>’
;
End result should like something like this
Calling the external function
You can now finally that the connection is working, by selecting the function with an integer value and any given string. The output should be as shown in the image. As you can see, this example is really basic and shows only that the connection is working.
If you face in errors during the execution, check the troubleshooting page at Snowflake for possible solutions. I can say from experience that you must follow the instructions really carefully and remember to deploy the API at AWS often to reflect your changes.
This blog post has now covered the basics of external functions e.g. how you can trigger basic Python code running inside AWS Lambda. Next time I will show how you can build something concrete using the same tools and Amazon services.
Are we there yet?
External functions are currently a Preview Feature and are open to all accounts, but they support currently only services behind Amazon AWS API Gateway.
This blog is a commentary to the AWS Well-Architected – Analytics Lens document and will be highlighting things that I disagree with or strongly agree.
AWS Well-Architected Framework is a set of questions and practices for creating good architectures. This May, AWS released Analytics Lens for AWS Well-Architected Framework, which focuses in analytical projects. This Lens is closest to my area of expertise and therefore it is good time to write blog about it. As for my background, I am usually working in Nordic projects which generally has less data and smaller team sizes than the projects that AWS architects base most of their viewpoints in the document on.
This blog is a commentary to the Analytics Lens document and will be highlighting things that I disagree with or strongly agree. Many of the disagreements are related to AWS having quite large projects as a reference versus in relatively small projects that are common in the Nordics. For example, AWS is selling Glue in many cases where it is too heavy for the data amount and even Lambda function could do the necessary transformations with much smaller costs. On the other hand, in the document there are many good points with which I agree, such as using columnar formats in S3.
First there will be small introduction to AWS Well-Architected Framework and Analytics Lense, but after that headers will follow the structure of the original Analytics Lens document. But the blog should be understandable without prior knowledge of Well-Architected Framework. Some experience with AWS services and analytical concepts like data lakes would be good to have.
AWS Well-Architected Framework
Let’s start with explaining what AWS Well-Architected Framework itself is. It is a distilled version of the combined knowledge of AWS Architects on what should be taken into account when creating well architected systems. In practice, the framework is a collection of non-AWS specific questions and AWS best practices that can answer to those questions. The questions are grouped into five different pillars: Operational Excellence, Security, Reliability, Performance Efficiency and Cost Optimization.
Analytics Lens
Analytics lens is a focused look into the generic well-architected frameworks questions and best practices for data projects. The document consists of two parts: First half is about different use cases and best practices on how to solve them. Second half is about the questions to focus on especially in analytics cases. Not all topics will be discussed in this blog as I will be picking some of the most important parts in my opinion and commenting on them. Headers Definition – Catalog and Search Layer and Scenarios are from the first half and the Pillars are from the second half.
The document is intended for people with technology roles and I concur with that, but it doesn’t require much technical AWS knowledge. The proposed technologies are explained at least on the high level in the document.
Overall, I agree with the material in the document, but I will be critically commenting from smaller projects point of view. With smaller projects, I mean projects where largest tables are hundreds of millions, but not billions. And team size responsible for everything is four persons and not multiple teams with more people in each.
For the rest of the blog before Recap and Closing remark, the headers will be following the original Analytics Lens documents headers.
Definitions – Catalog and Search Layer
AWS Glue is marketed as being “…easy for customers to prepare and load their data…” and it does have wizard for creating jobs and it manages Spark-clusters for you. But, if you try to do anything more complex than mapping fields to different names, you need to change the Spark-code, which might not be easy for all developers. Also, if you have network routing requirements for connecting to the source database or have limited S3 access, then you need to define which network Glue is running and need to remember security group ingress for other cluster nodes.
Scenarios
Data Lake
Data Lake is defined as a centralized repository for storing all structured and unstructured data at any scale.
From this scenario, I want to highlight that there needs to be a process of cataloging and securing the data. But with naming conventions you can already do this to some extent. Which ties into a part that I don’t agree with which is that data providers are only provided location (S3 bucket) and everything else is decided by the provider. By providing a bit more guidelines, you are making the data lake teams work much easier and this can also help in consuming the data. And it should not take much extra work from the provider side when this practise is decided in the beginning.
Batch Data Processing
In Batch Data Processing scenario, only EMR, Glue and Batch are mentioned. Why not Fargate? EMR and Batch first launch EC2 instances. In Batch Docker containers are then run on top of the instances and EMR creates a compute cluster. Glue is serverless in that sense, but it also has quite long startup time and cost. The startup time should be decreasing in the near future, but I haven’t heard about that they would decrease cost or the minimum billable time, which is now ten minutes. Fargate launches relatively fast and the cost isn’t very high when used for batch processing. The caveat here is of course what is the complexity of the compute logic and amount of data. It feels like AWS architects have again gone with the large dataset option only.
AWS Step Functions are marketed as visual workflows when in truth it has only the visual representation of the workflow written as YAML. For many technical people this might be better than drag-and-drop UI, but I don’t like it being marketed as a visual tool when in truth it has only the visualization of the end result.
Streaming Ingest and Stream Processing
Authors rise a good point that you should plan a robust infrastructure that can adapt to changes on the volume of data coming through the stream. Unfortunately, Kinesis doesn’t provide this yet out-of-box and you need to create it yourself with Application Auto Scaling or something else. On the other hand, Firehose does provide this functionality with limitations in other areas.
Kinesis Data Streams not having resource based policies for cross-account sharing is written as a positive thing. And, to an extent it is, as you can’t by mistake grant access to the stream. But, if you want to send data to the stream, this means that the sender needs to have a user in the target account or having a role switching rights. The latter doesn’t always work with third party tools, which are waiting for access credentials.
This is a good place for an example of a case where missing the small details in pricing can lead to ten times the estimated cost. The Kinesis Producer Library (KPL) is very useful as it combines records you are planning to send to the maximum record size. With Kinesis itself it isn’t so much of an issue unless you are having issues with record limits per shard, but Firehose is another issue. Firehose is billed in 5KB steps rounded up. Hence, if each record is 1KB in size, you are paying five times the amount that you estimated from the daily data amounts. KPL fixes this as each record is filled as full as possible. But if you are using Firehose transformations, then you need to have intermediate Kinesis before Firehose as only then Firehose understands that a single Kinesis record has multiple records to be transformed.
Kinesis Client Library (KCL) should be used for two reasons. It can parse the data combined with KPL and it takes care of the shard location. Just remember that KCL will create a DynamoDB table to keep track of shard location. The cost is quite minimum and the IAM access isn’t very large, but something to keep in mind.
The Kinesis aggregation library are also available separately: https://github.com/awslabs/kinesis-aggregation. KPL is not available in all environments (Java wrapper for C++ executable), so aggregation library is necessary for example when using Lambda functions.
Multitenant architecture
The lens correctly says that users should have only just enough privileges to access their data and not the other tenants. But this is easier said than done in true multitenant mode because writing good IAM policies is not the easiest thing to do. And, generally the promise of public cloud to analysts and other users has been the freedom of doing what they want without many guardrails. Also, the billing can be a hassle especially if there are costly data transfers. Therefore, I generally recommend separate accounts for different teams. The baseline is then that no access is given and all teams are responsible for their own costs. Of course, there can and should be shared resources, for example audit backups, but those are maintained with completely different teams and don’t have access to the source accounts.
Operational Excellence Pillar
ANALYTICS_OPS 05: How are you evolving your data and analytics workload while minimizing the impact of change?
AWS Secrets Manager mentioned again as a place to store credentials and other secrets. After the service was launched, there hasn’t been much mentions that Parameter Store can also store secrets encrypted by KMS and having the same security level as with Secrets Manager. There are probably two main reasons: one is positive from customer point of view and the other is more about getting more money to AWS. The positive one is that Secrets Manager has a lot more features than Parameter Store especially when using with RDS. The AWS billing side is that Parameter Store is free except KMS invocations where Secrets Manager costs per secrets and API calls. But it seems that the pricing has lowered quite a bit, it is only 40 cents per secret per month.
Security Pillar
ANALYTICS_SEC 2: How do you authorize access to the analytics services within your organization?
I like the terminology of “fine-grained” and “coarse-grained” approach to user segmentation. “Fine-grained” links to the fully shared multitenant architecture where all resources are shared and access control is made in quite low level. The “course-grained” is used in silo multitenant architecture, where almost everything is done in accounts owned by the team and access needs to be granted by cross-account roles or resource policies. AWS prefers the course-grained version for organization with large number of users, but for me this should also be taken into account when working with small autonomous teams, even if the user amount itself isn’t very large. You can lose a lot of time when trying to setup the correct fine-grained accesses and even then might have missed something and created a security hole, or the requirements have changed and you need to make changes.
ANALYTICS_SEC 5: How are you securing data in transit?
Just a small highlight that generally data is SSL/TLS encrypted when you are using AWS services, but Redshift is an anomaly here. You need to separate define SSL in jdbc configuration and if possible also block non SSL-traffic.
ANALYTICS_SEC 6: How are you protecting sensitive data within your organization?
S3 object tagging is told to be a good way of marking what is sensitive data. After that you can write IAM policies with conditions to limit access. You also should look into disabling tagging access, because otherwise users could grant additional access to themselves.
I disagree with this idea for multiple reasons, but lets start on positive note on what I agree with. Tagging makes it possible to define fine-grained access policies and also generally have more metadata on what the data is like. But in many cases this can hide information, increase questions on why S3 commands failed, increase maintenance requirements and introduce security fails. I would like to have the data sensitivity be part of the S3 path. For example store-db/generic/post-number, store-db/company/products, store-db/PII/customers. This way the sensitivity information can be easily found and IAM access can be given using prefixes and wildcards. Of course this approach requires that you have a robust pipeline so that you can trust that data goes into correct prefixes and in addition check the stored data also from time to time. Having data in correct prefixes might need modifications of the raw data, and in that case raw data should be treated as being the highest level of sensitivity possible.
Why would AWS then want to market the S3 object tagging? One reason is probably what I also said about fine grained access, but another is that they have introduced Macie service couple of years back which does the tagging for you. This takes away some of the cons I raised, but of course it increases costs to you as a user and I don’t have experience how well it finds Nordic Personally Identifiable Information(PII).
Performance Efficiency Pillar
Very good point here of using business and application requirements to define performance and cost optimization goals. AWS gives lots of possibilities on how to store data, but unfortunately customers don’t always know what the requirements are and architecting the best solution is difficult.
In on-prem world you generally had one place to store data and when it was nearing its limits, old data was just deleted (or more disk space added). Now that you can have very cheap storage in Glazier, customers think that everything should be saved, even though there should still exist a systematic data life-cycle thinking, at least from legal point of view (GDPR etc).
ANALYTICS_PERF 01: How do you select file formats and compression to store your data?
A very large thumbs up for columnar formats if you are using or having even a slight feeling that you might want to use Athena, Spectrum or for example Snowflake external tables. Columnar formats aren’t really required if you are just dumping the data in S3 before loading it into a data warehouse. But even in this case you should compress your data and split it in an optimal way for the target database.
Cost Optimization Pillar
ANALYTICS_COST 04: What is your data lifecycle plan?
This ties smoothly with my comments of the performance pillar. Lifecycle should be taken into account early in the project, because from business perspective it might take some time to get the information. Technical usage pattern is of course another option, but you might not have visibility to that for some time, because users are not using your system in a normal way yet. I haven’t tested S3 analytics, but it shows like a good possibility for finding out the usage patterns. Other ways could be S3 logs or cloudtrail if they are enabled.
ANALYTICS_COST 07: How are you managing data transfer costs in your analytics application?
This is an area that is often overlooked. Most who work in AWS know that data transfer cost into AWS is free and costs when transferred out. Which makes perfect sense in AWS plan to get customers to migrate both data and compute to their cloud. Between regions transfer cost also makes quite a lot of sense because the data goes to a remote location.
But at least I feel that not everyone knows that there are data transfer costs between availability zones. The cost is a lot smaller than between regions or internet, but it can still pile up. Generally best practice is to have resources split into multiple AZs for high availability (HA). The cost isn’t really that high that you shouldn’t split across AZs if you have HA requirements, but if the architecture isn’t really HA and some parts are only in one AZ, then the situation is different. For example, you want to pay only for one database, but thought to put Lambda network configuration to launch in any AZ. In this situation if the AZ where the database is down, the system wouldn’t work in any case and now you also pay extra for the lambdas requesting information from other AZs during normal process.
ANALYTICS_COST 08: What is your cost allocation strategy for resources consumed by your analytics application?
We are again back in the question of how to setup multi-tenant architectures. Two different styles are introduced in the document: siloed and shared. In siloed style, each team (for me also environment) have separate accounts and in shared everyone is in the same account. In both cases, there can be some supporting accounts separate from the development. When using shared architectures, allocating cost center tags to resources is quite necessary. But even that won’t be enough, if you want to truly share resources and their costs. In this case for example a RDS database isn’t just for the one cost center. And then you need to have additional metrics for calculating how much of the database everyone has used.
On the other hand, if you are using a siloed architecture with AWS Organizations then you have clear view on how much each team and environment has been using resources. AWS highlights that there is added complexity of managing users and resources, but I don’t really buy it. To me, the downside is the underusage of the resources, but that should be able to be minimized with good metrics and using services instead of EC2 machines with custom installations.
Recap
The Analytics Lens is quite informative piece of document and I agree with most of the points. What I don’t agree, generally fall into three categories: 1. Written only with larger organizations in mind, 2. large supporting teams or 3. trying to just sell more AWS services. None of them are inherently bad and you should always take this kind of best practises documentation with a grain of salt. As you should also take mine. I am only one person even though my viewpoint has been affected by my customer projects, colleagues and AWS own material.
I hope that this was an informative look at Analytics Lense and can detour into other important aspects of data intensive applications in AWS. My recommendation is to read the document yourself and come to your own conclusions.
Closing words
In AWS Summit EMEA, Werner Vogel (Amazon.com CTO) mentioned the Well-Architected Framework in his keynote. He emphasized that they want customers to build the best systems they can in AWS and Well-Architected Framework is one tool to help this.
I also strongly recommend that you do Well-Architected review to your solutions and workloads with or without Analytics Lens recommendations. You can do it yourself or ask for a more experienced third party to facilitate. Solita is one of AWS Well-Architected Partners, so we are at your service also in this area. If you have any questions about this, send me a message.
Snowflake and Salesforce going live with their strategic partnership, Salesforce connectors coming to Snowflake, external functions, data masking support. New Web UI's going live. The list goes on. Read the following article for a curated list of new features released on Snowflake Summit 2020 a.k.a. virtual "Say Hello To The Data Cloud" -event.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
Trying to go through for all the announcements for a product can be sometimes overwhelming. It takes time as you need to go through for all the individual press announcements. To ease the pain, I’ve gathered a curated list of new Snowflake features released at the second annual Snowflake Summit or as it was this year branded as “Say Hello To The Data Cloud” -event due to the event being virtual. Snowflake Summit will be held in 2021 at Caesars Forum, Las Vegas at June 7-10th.
So let’s begin.
Snowflake released new features which can be split down into to following categories: Salesforce partnership, Core Database features and UI features. I’ll list the features by categories and give a more precise description of the features released (if possible).
Salesforce strategic partnership
Most significant news this year was the announced Salesforce partnership. Snowflake CEO Frank Slootman announced together with Salesforce COO and President Bret Taylor the partnership which has been under the works for a while. The first results of this partnerships are the better integration between Salesforce and Snowflake.
Salesforce connectors
The first two visibles feature from Salesforce partnership are now released Einstein Analytics connectors will enable you to use Snowflake data directly at Einstein Analytics and the Einstein Analytics Outbound Connector for Snowflake for loading data into Snowflake.
Core Database functions
External functions
This function is going to unlock so much potential when used with DataOps tools (for example Agile Data Engine). At first sight, external functions might sound that they just add something to existing functions functionality. In reality, external functions enable you to trigger anything in Azure, AWS or Google Cloud if it’s reachable through their API Gateways. To be more precise, you can, for example, create function into Snowflake which will trigger Power BI dataset refresh through Azure API Gateway. This will mean that you can create a data pipeline which will refresh your Power BI reports right after your publish tables have been refreshed using only SQL and DataOps tool or in Snowflake – streams and tasks.
More information: https://docs.snowflake.com/en/sql-reference/external-functions.html
Search optimization service
You could call search optimization service as Snowflake’s answer to indexes. Basically you can define table-by-table basis when you want to Snowflake to pre-compute table information to used and enable faster queries for smaller dataset with smaller warehouses. More information: https://docs.snowflake.com/en/user-guide/search-optimization-service.html
Support for SQL in stored procedures
As the title says, support for SQL procedures is finally coming. JavaScript has been the chosen language for Snowflake stored procedures, but honestly, we’ve been missing SQL.
Geospatial support
As the title says, Geospatial support is now coming to Snowflake. More information: https://docs.snowflake.com/en/sql-reference/data-types-geospatial.html
Richer resource monitoring alerts to Slack and Teams
Resource Monitoring is getting richer and more useful as you can create richer resource monitoring rules and you can finally direct those alerts to Slack and Teams natively.
Programming language extensibility
You can use in the future your chosen language in the user-defined functions. The first language to be supported is going to be Java and Python support is coming. Snowflake is going also to support popular coding paradigms, in this case, Snowflake is going to support data frames with Python.
Dynamic data masking support
Data masking is nothing unusual, but finally, Snowflake has built-in support for data masking internally and with tokenization through external functions. You can now mask columns which include for example social security numbers and you can trust that to numbers are hidden from admins as well. In the age of GDPR – the possibility reduce the footprint of personal data within your databases has become a vital asset in your data toolset.
UI features
New UI’s going live and also new admin view
The Numeracy acquisition was released at March 2019 https://www.snowflake.com/blog/numeracy-investing-in-our-query-ui/ and on last year Summit we got a glimpse of the new UI and it’s now been rolled out to Snowflake customers. New Query UI will enhance the user experience with predictive typing and live data charts. The Admin UI will, for example, give more insights about Snowflake credits costs. Sadly, we will not yet get the possibility to see how much pre-bought credits have been used.
Data Marketplace
Snowflake Data Marketplace which was announced last year is now live. You can now make your data available for other to consume and data consumers can use that data as part of their data pipelines as they would use normal SQL tables. More information: https://www.snowflake.com/data-marketplace/
Hopefully, this list helps you to get a grasp on things to come on Snowflake landscape.
More information by Christian Kleinerman:
https://www.snowflake.com/blog/snowflakes-product-innovations-for-2020/
MLOps refers to the concept of automating the lifecycle of machine learning models from data preparation and model building to production deployment and maintenance. MLOps is not only some machine learning platform or technology, but instead it requires an entire change in the mindset of developing machine learning models towards best practises of software development. In this blog post we introduce this concept and its benefits for anyone having or planning to have machine learning models running in production.
Operationalizing data platforms, DataOps, has been among the hottest topics during the past few years. Recently, also MLOps has become one of the hottest topics in the field of data science and machine learning. Building operational data platforms has made data available for analytics purposes and enabled development of machine learning models in a completely new scale. While development of machine learning models has expanded, the processes of maintaining and managing the models have not followed in the same pace. This is where the concept of MLOps becomes relevant.
What is MLOps?
Machine learning operations, or MLOps, is a similar concept as DevOps (or DataOps), but specifically tailored to needs of data science and more specifically machine learning. DevOps was introduced to software development over a decade ago. DevOps practices aim to improve application delivery by combining the entire life cycle of the application – development, testing and delivery – to one process, instead of having a separate development team handing over the developed solution for the operations team to deploy. The definite benefits of DevOps are shorter development cycles, increased deployment velocity, and dependable releases.
Similarly as DevOps aims to improve application delivery, MLOps aims to productionalize machine learning models in a simple and automated way.
As for any software service running in production, automating the build and deployment of ML models is equally important. Additionally, machine learning models benefit from versioning and monitoring, and the ability to retrain and deploy new versions of the model, not only to be more reliable when data is updated but also from the transparency and AI ethics perspective.
Why do you need MLOps?
Data scientists’ work is research and development, and requires essentially skills from statistics and mathematics, as well as programming. It is iterative work of building and training to generate various models. Many teams have data scientists who can build state-of-the-art models, but their process for building and deploying those models can be entirely manual. It might happen locally, on a personal laptop with copies of data and the end product might be a csv file or powerpoint slides. These types of experiments don’t usually create much business value if they never go live to production. And that’s where data scientists in many cases struggle the most, since engineering and operations skills are not often data scientists’ core competences.
In the best case scenario in this type of development the model ends up in production by a data scientist handing over the trained model artifacts to the ops team to deploy, whereas the ops team might lack knowledge on how to best integrate machine learning models into their existing systems. After deployment, the model’s predictions and actions might not be tracked, and model performance degradation and other model behavioral drifts can not be detected. In the best case scenario your data scientist monitors model performance manually and manually retrains the model with new data, with always a manual handover again in deployment.
The described process might work for a short time when you only have a few models and a few data scientists, but it is not scalable in the long term. The disconnection between development and operations is what DevOps originally was developed to solve, and the lack of monitoring and re-deployment is where MLOps comes in.
How can MLOps help?
Instead of going back-and-forth between the data scientists and operations team, by integrating MLOps into the development process one could enable quicker cycles of deployment and optimization of algorithms, without always requiring a huge effort when adding new algorithms to production or updating existing ones.
MLOps can be divided into multiple practices: automated infrastructure building, versioning important parts of data science experiments and models, deployments (packaging, continuous integration and continuous delivery), security and monitoring.
Versioning
In software development projects it is typical that source code, its configurations and also infrastructure code are versioned. Tracking and controlling changes to the code enables roll-backs to previous versions in case of failures and helps developers to understand the evolution of the solution. In data science projects source code and infrastructure are important to version as well, but in addition to them, there are other parts that need to be versioned, too.
Typically a data scientist runs training jobs multiple times with different setups. For example hyperparameters and used features may vary between different runs and they affect the accuracy of the model. If the information about training data, hyperparameters, model itself and model accuracy with different combinations are not saved anywhere it might be hard to compare the models and choose the best one to deploy to production.
Templates and shared libraries
Data scientists might lack knowledge on infrastructure development or networking, but if there is a ready template and framework, they only need to adapt the steps of a process. Templating and using shared libraries frees time from data scientists so they can focus on their core expertise.
Existing templates and shared libraries that abstract underlying infrastructure, platforms and databases, will speed up building new machine learning models but will also help in on-boarding any new data scientists.
Project templates can automate the creation of infrastructure that is needed for running the preprocessing or training code. When for example building infrastructure is automated with Infrastructure as a code, it is easier to build different environments and be sure they’re similar. This usually means also infrastructure security practices are automated and they don’t vary from project to project.
Templates can also have scripts for packaging and deploying code. When the libraries used are mostly the same in different projects, those scripts very rarely need to be changed and data scientists don’t have to write them separately for every project.
Shared libraries mean less duplicate code and smaller chance of bugs in repeating tasks. They can also hide details about the database and platform from data scientists, when they can use ready made functions for, for instance, reading from and writing to database or saving the model. Versioning can be written into shared libraries and functions as well, which means it’s not up to the data scientist to remember which things need to be versioned.
Deployment pipeline
When deploying either a more traditional software solution or ML solution, the steps in the process are highly repetitive, but also error-prone. An automated deployment pipeline in CI/CD service can take care of packaging the code, running automated tests and deployment of the package to a selected environment. This will not only reduce the risk of errors in deployment but also free time from the deployment tasks to actual development work.
Tests are needed in deployment of machine learning models as in any software, including typical unit and integration tests of the system. In addition to those, you need to validate data and the model, and evaluate the quality of the trained model. Adding the necessary validation creates a bit more complexity and requires automation of steps that are manually done before deployment by data scientists to train and validate new models. You might need to deploy a multi-step pipeline to automatically retrain and deploy models, depending on your solution.
Monitoring
After the model is deployed to production some people might think it remains functional and decays like any traditional software system. In fact, machine learning models can decay in more ways than traditional software systems. In addition to monitoring the performance of the system, the performance of models themselves needs to be monitored as well. Because machine learning models make assumptions of real-world based on the data used for training the models, when the surrounding world changes, accuracy of the model may decrease. This is especially true for the models that try to model human behavior. Decreasing model accuracy means that the model needs to be retrained to reflect the surrounding world better and with monitoring the retraining is not done too seldom or often. By tracking summary statistics of your data and monitoring the performance of your model, you can send notifications or roll back when values deviate from the expectations made in the time of last model training.
Applying MLOps
Bringing MLOps thinking to the machine learning model development enables you to actually get your models to production if you are not there yet, makes your deployment cycles faster and more reliable, reduces manual effort and errors, and frees time from your data scientists from tasks that are not their core competences to actual model development work. Cloud providers (such as AWS, Azure or GCP) are especially good places to start implementing MLOps in small steps, with ready made software components you can use. Moreover, all the CPU / GPU that is needed for model training with pay as you go model.
If the maturity of your AI journey is still in early phase (PoCs don’t need heavy processes like this), robust development framework and pipeline infra might not be the highest priority. However, any effort invested in automating the development process from the early phase will pay back later and reduce the machine learning technical debt in the long run. Start small and change the way you develop ML models towards MLOps by at least moving the development work on top of version control, and automating the steps for retraining and deployment.
DevOps was born as a reaction to systematic organization needed around rapidly expanding software development, and now the same problems are faced in the field of machine learning. Take the needed steps towards MLOps, like done successfully with DevOps before.
When they develop predictive models for business, Data Scientists often feel pressure to create results within a very short time span. These feelings may indicate a larger problem with risk management.
With uncertainty, the natural thing is to divest, i.e. not invest large sums in an uncertain endeavour. But AI risks are not easily disposed of in small projects either.
This might leave organizations perplexed as to what to do. On one hand, there is the call to embrace AI. On the other, the risks are real.
As a rule of thumb, a longer time perspective won’t hurt. Predictive modeling and automation are long-running investments. As such, they should be subject to risk assessment and scrutiny. There should be management for their entire life span.
Because of AI solutions’ partly speculative nature, their risk of failure is relatively high. A recent study underlined this, suggesting that roughly four out of five AI projects fail in the real world.
A predictive model has its particular strengths and weaknesses. But it has some recurring costs too, both implicit and explicit. Some of these costs may fall immediately to the supporting organization. And some of them might even fall outside of it.
The following (otherwise unrelated) tweet from a couple of days back pinpoints these risks neatly.
Leaving aside the social discourse, I very much agree on observations about organizations. There is a certain mindset about DS magically fixing business perspectives and organizational shortcomings. In my personal opinion, this is naïve at best. It is not an overstatement to call it dangerous in some cases.
The use of automation requires a certain robustness from surrounding structures.
AI as part of larger systems
In classical control theory, systems are designed around the principle of stability. A continuously working system, like a production line, is regulated with the help of measured and desired outputs. The problem is to make processes optimal by making them smooth, and get a good output per used resource ratio out of it.
Often, AI is a part of a larger production machinery. The whole process may involve human beings and other machine actors as well. Recent examples of AI victory make a lot of sense when seen in this kind of framing.
If we look at a famous example, Google AlphaGo’s victory over human players was supported by human maintained tournament protocols, servers, and arrangements. Not to speak of news media that helped to sculpt the event when it took place.
The AI’s job was relatively simple as comes to inputs and outputs: receive a board position and suggest the next move. Also how that AI learned to play Go in the first place was a result of multiple years of engineering. Its training was enabled by human work, and its progress was assessed by humans along the way.
The case of adverse outcomes
If we look at organizations, there are always hidden costs when adapting new procedures and processes. Predictive model performance, on the other hand, is largely measured by the number of explicit mistakes that it makes. These kinds of explicit mistakes may capture part of the cost of an automated solution. But fail rate is hardly a comprehensive measure in a complex setting.
Just like in a game some moves may be very costly as regards winning, some mistakes may be very costly to an organization.
One recent observation within the field has been about implicit “ghost” work that goes into keeping up AI appearances: fixing and hiding AI based errors, even fixing AI decisions in the first place before they have time to cause harm.
Now traditional production lines have fallback mechanisms. For example for turning the line off in a case of emergency. Emergency protocols are in place because unexpected events may occur in the real world. This is a very healthy mindset for any AI development also. We should embrace it fully. An organization should take these things into account when planning and assessing a new solution.
No matter how good preliminary results a solution should show, it will start failing sooner or later when something unexpected happens. And it will not fix itself. Its use will probably also create unexpected side effects even when it is doing a superb job.
Target audience are data practitioners looking for a method to practice DataOps with a simple method even in restricted environments. A walk-through of the code is detailed in the appendix.
The linked code repository contains a minimal setup to automatize infrastructure and code deployment simultaneously from Azure DevOps Git Repositories to Databricks.
TL;DR:
Import the repo into a fresh Azure DevOps Project,
get a secret access token from your Databricks Workspace,
paste the token and the Databricks URL into a Azure DevOps Library’s variable group named “databricks_cli”,
Create and run two pipelines referencing the YAML in the repo’s pipelines/ directory.
Any Databricks compatible (Python, Scala, R) code pushed to the remote repository’s workspace/ directory will be copied to the Databricks workspace with an interactive cluster waiting to execute it.
Background
Azure DevOps and Databricks have one thing in common – providing industry standard technology and offering them as an intuitive, managed platform:
Databricks for running Apache Spark
DevOps for Git repos and build pipelines
Both platforms have much more to offer then what is used in this minimal integration example. DevOps offers wiki, bug-, task- and issue tracking, canban, scrum and workflow functionality among others.
Databricks is a fully managed and optimized Apache Spark PaaS. It can natively execute Scala, Python, PySpark, R, SparkR, SQL and Bash code; some cluster types have Tensorflow installed and configured (inclusive GPU drivers). Integration of the H2O machine learning platform is quite straight forward. In essence Databricks is a highly performant general purpose data science and engineering platform which tackles virtually any challenge in the Big Data universe.
Both have free tiers and a pay-as-you-go pricing model.
Databricks provides infrastructure as code. A few lines of JSON consistently deploy an optimized Apache Spark runtime.
After several projects and the increasing need to build and prototype in a managed and reproducible way the DevOps-Databricks combination became very appreciated: It enables quick and responsive interactive runtimes and provides best industry practice for software development and data engineering. Deployment into (scheduled), performant, resilient production environments is possible without changes to the platform and without any need for refactoring.
The core of the integration uses Databricks infrastructure-as-code (IaC) capability together with DevOps pipelines functionality to deploy any kind of code.
the Databricks CLI facilitates programmatic access to Databricks and
the managed Build Agents in DevOps deploy both infrastructure and analytic code.
Azure pipelines deploy both the infrastructure code and the notebook code from the repository to the Databricks workspace. This enables version control of both the runtime and the code in one compact, responsive repository.
All pieces of the integration are hosted in a single, compact repository which make all parts of a data and modeling pipeline fully reproducible.
Prerequisites
Log into Azure DevOps and Databricks Workspace. There are free tiers for both of them. Setup details are explained extensively in the canonical quick start sections of either service:
For the integration Databricks can be hosted in either the Azure or AWS cloud.
1. Import the Repository
To use this demo as a starting point for a new project, prepare a Azure DevOps project:
create a new project (with an empty repository by default)
select the repository tab and choose “Import a repository”
paste the URL of this demo into the Clone URL field: https://dev.azure.com/reinhardseifert/DatabricksDevOps/_git/DatabricksDevOps
wait for the import to complete
clone the newly imported repository to your local computer to start deploying your own code into the workspace directory
Then create two Azure pipelines which create the runtime and sync any code updates into it (see below).
2. Create Databricks Secret Token
Log into the Databricks Workspace and under User settings (icon in the top right corner) and select “Generate New Token”. Choose a descriptive name (“DevOps Build Agent Key”) and copy the token to a notebook or clipboard. The token is displayed just once – directly after creation; you can create as many tokens as you wish.
Databricks > User Settings > Create New Token
3. Add the token to the Azure DevOps Library
The Databricks Secret Token has to be added to a Variable Group named “databricks_cli”. Variable groups are created under Pipelines > Library. Note that the name of the variable group is referenced in both pipeline definitions (/pipelines/build-cluster.yml and /pipelines/build-workspace.yml). Two variables have to be defined: 1. databricks_host and 2. databricks_token
The variable names are referenced in the .yml file – changing them in the DevOps library requires also changing them correspondingly in the .yml files. When clicking the lock icon after defining the variable it is treated as a secret and not visible after that action in the DevOps project. Neither in the Library nor in the Build servers (even when accidentially echo-ing them. But of course writing them to the Databricks environment would potentially expose them. This is a security concern when collaborating with non-trusted parties on a Project.
Pipelines > Library > Add Variable Group
Azure DevOps
Generally the Azure DevOps portal offers as minimal functionality a git repository to maintain code and pipelines to deploy the code from the repository into runtimes.
Azure Repositories
The Azure repo contains the full logic of the integration:
the actual (Python) code to run,
the JSON specification of the Spark-cluster which will run the code,
shell build scripts which are executed in the pipeline/ build server,
the YAML configuration which define the pipelines.
The complete CI/CD pipeline is contained in a single Git repository in a very compact fashion. Following Databricks’ terminology the Python code (1) is located in the workspace/ directory. The runtime specification .json (2), build scripts .sh (3) and the pipeline configuration .yml (4) are located in the pipelines/ directory according to the Azure DevOps paradigm.
Azure Pipelines
The Pipelines menu provides the following functionality:
Pipelines (aka build pipelines),
Environments (needed to group Azure resources – not used here),
Releases (aka release pipelines – not used here)
Library (containing the variable groups)
The build pipelines exclusively used in this demo project are managed under the “Pipelines > Pipelines” menu tab – not really intuitive.
Azure Build Pipelines
The pipeline’s build agents are configured via YAML files (e.g. build-cluster.yml). In this case they install the Databricks CLI on the build machine and then execute CLI commands to create runtimes and move code notebooks to the runtime. The Databricks cluster is configured by a single JSON file (see config.cluster.json).
This minimal integration requires creation of two pipelines:
cluster creation – referencing pipelines/build-cluster.yml and
select the imported repository from the drop-down menu
select Existing Azure Pipeline YAML file
select the YAML file from the drop-down menu
Run the pipeline for the first time – or just save it and run it later.
At this point the Databricks secret access token mentioned in the prerequisite paragraph need to be present in a “databricks_cli” variable group. Otherwise the pipeline run will fail and warn; in this case just create the token (in Databricks) and the variable group (in DevOps) and re-run the pipeline.
After creating the pipelines and saving them (or running them initially), the default pipeline names reference the source repository name which triggers them. For easier monitoring the pipelines should be renamed according to their function, like “create-cluster” and “sync-workspace” in this case.
Summary
This concludes the integration of analytic code from an Azure DevOps repository into a hosted Databricks runtime.
Any change to the config.cluster.json deletes the existing cluster and creates a new one according to the specifications in the JSON file.
Any change to workspace/ will copy the notebook file(s) (R, Python, Scala) to the Databricks workspace for execution on the cluster.
The Databricks workspace in this example was hosted on Azure. Only minor changes are required to use an AWS hosted workspace. On all cloud platforms the host URL and security token is specific for the chosen instance and region. The cloud specific parameter is the node_type_id in the cluster configuration .json file.
Using this skeleton repo as a starting point, it is immediately possible to run interactive workloads on a performant Apacke Spark cloud cluster – instead of “cooking” the local laptop with analytic code – transparently maintained on a professional DevOps platform.
Appendix
Following, a detailed walk-through of the .yml pipeline configurations, .sh build scripts and .json configuration files.
In general, the YAML instructs the build server to 1. start up when a certain file is changed (trigger), 2. copy the contents of the repository to the build server and 3. execute a selection of shell scripts (tasks) from the repository
Pipeline: Create cluster
This is a detailed walk through for the build-cluster.yml pipeline. The .yml files have a hierachical structure and the full hierarchy of the DevOps build pipeline is included although stages could be omitted.
Trigger
The first section of the pipeline YAML specifies the trigger. Any changes to the specified branch of the linked repo will automatically run of the Build Agent.
Without the paths: section, any change to the master branch will run the pipeline. The cluster is rebuild when the configuration changes or the selection of installed Python- or R-libraries changes.
Stages
The stage can be omitted (for a single stage pipeline) and the pool, variables and jobs directly defined. Then the stage would be implicit. It is possible to add testing steps to the pipeline and build fully automated CI/CD pipelines accross environments within on .yml file.
Selects the type of virtual machine to start when the trigger files are changed. At the time of writing ubuntu_latest will start a Ubuntu 18.04 LTS image.
Variables
variables:-group: databricks_cli
This section references the variable group created in the Prerequisite section. The secret token is transfered to the build server and authorizes the API calls from the server to the Databricks workspace.
Jobs, Steps and Tasks
A job is a sequence of steps which are executed on the build server (pool). In this pipeline only task steps are used (see the docs for all step operations).
The first step is selecting the Python version for all following Python command on the build server; the Databricks CLI is written in Python and installed via Pip in the following task.
Task: Install and configure the Databricks CLI
- task: ShellScript@2
inputs:
scriptPath: pipelines/databricks-cli-config.sh
args: "\$(databricks_host) \$(databricks\_token)"
displayName: "Install and configure the Databricks CLI"
Note that the path is relative to the root of the repo. The secret access token and host URL from the DevOps library are copied into environment variables which can be passed to the script in the args section.
The shell script executes the installation of the Databricks CLI and writes the neccessary CLI configuration on the build server.
Task: “Delete previous cluster version (if existing)”
This task will remove any cluster with the name provided in the args: section. This allows for updating the cluster when the configuration file is changed. When no such cluster is present the script will fail. Usually the pipeline will break at this point but here continueOnError is true, so the pipeline will continue when creating a cluster for the first time.
-task: ShellScript@2inputs:scriptPath: pipelines/databricks-cluster-delete.shargs:"HelloCluster"continueOnError:"true"displayName:"Delete previous cluster version (if existing)"
The shell script called by this task is a wrapper around the Databricks CLI. First it queries for the cluster-id of any cluster with the name passed.
CLUSTER_ID=$(databricks clusters list --output json |jq -r --arg N "$CLUSTER_NAME"'.clusters[] | select(.cluster_name == $N) | .cluster_id')
It is possible to create multiple clusters with the same name. In case there are multiple all of them are deleted.
forID in $CLUSTER_IDdoecho"Deleting $ID"databricks clusters permanent-delete --cluster-id $IDdone
Task: Create new cluster
-task: ShellScript@2inputs:scriptPath: pipelines/databricks-cluster-create.shargs:"HelloCluster"displayName:"Create new cluster"
The build script reads the config.cluster.json and adds the cluster name passed from the pipeline .yml
Now the configuration .json file can be passed to the Databricks CLI. The complete Apache Spark infrastructure is configured in the json. CLUSTER_NAME will be replaced with the name passed from the .yml.
Updating the runtime to another version requires only modifying the spark_version parameter with any supported runtime.
A Spark cluster consists of one driver node and a number of worker nodes and can be scaled horizontally by adding nodes (num_workers) or vertically by choosing larger node types. The node types are cloud provider specific. The Standard_DS3_v2 node type id references the minimal Azure node.
The autotermination feature shuts the cluster down when not in use. Costs are billed per second up time per processing unit.
Any reconfigurations triggers the pipeline and rebuilds the cluster.
The cluster create call returns the cluster-id of the newly created instance. Since the last step of this pipeline installs additional Python and R libraries (via Pip and CRAN respectively) it is necessary to wait for the cluster to be in pending state.
STATE=$(databricks clusters list --output json |jq -r --arg I "$CLUSTER_ID"'.clusters[] | select(.cluster_id == $I) | .state')echo"Wait for cluster to be PENDING"while [["$STATE"!="PENDING" ]]doSTATE=$(databricks clusters list --output json |jq -r --arg I "$CLUSTER_ID"'.clusters[] | select(.cluster_name == $I) | .state')done
Task: Install Python and R dependencies on the cluster
The final step is to add additional Python and R packages to the cluster. There are many ways to install packges in Databricks. This is just one way to do it.
-task: ShellScript@2inputs:scriptPath: pipelines/databricks-library-install.shargs:"HelloCluster"displayName:"Install Python and R dependencies"
Again the shell script wraps the Databricks CLI, here the library install command. The cluster name (“DemoCluster” in this example) has to be passed again.
All CLI calls to Databricks need the cluster-id to delete, create and manupulate instances. So first fetch it with a cluster list call:
CLUSTER_ID=$(databricks clusters list --output json |jq -r --arg N "$CLUSTER_NAME"'.clusters[] | select(.cluster_name == $N) | .cluster_id')
Then install the packages – one call to library install per package:
For additional Python or R package add a line in this build script – this will trigger the pipeline and the cluster is rebuild.
Pipeline: Import workspace
This is a detailed walk through for the build-workspace.yml pipeline. The first part of the pipeline is identical to the build-cluster.yml pipeline. The trigger include differs, since this pipeline is triggered by code pushes to the workspace/ directory. The choice of the build server (pool), the variable reference to the databricks_cli variable group for the Databricks access tokens and the Python version task are identical, also installing and configuring the Databricks CLI with the same build script as above.
The only build task is importing all files in the workspace/ directory to the Databricks Workspace. The args passes a sub-directory name for the /Shared/ folder in Databricks ( /Shared/HelloWorkspace/ in the example).
-task: ShellScript@2inputs:scriptPath: pipelines/databricks-workspace-import.shargs:"HelloWorkspace"displayName:"Import updated notebooks to workspace to dev"
The specified directory is first deleted. When the directory does not exist, the CLI prints and error in JSON format, but does not break the pipeline. The args: parameter is passed to the $SUBDIR variable in the build script.
Remember that the repo is copied into the pipeline build agent/server and the working directory of the pipeline agent points to the location of the .yml file which defines the pipeline.
Snowflake extends the idea of traditional relational database by having the possibility to store and handle semi-structured data types. As shown in this post, semi-structured data types have effects on query performance and results of numerical operations.
On top of the traditional relational data, Snowflake also has support for semi-structured data with flexible schema. This can be utilized with for example following data formats: JSON and XML. Inside Snowflake, these are stored as either variant, array or object data types. Let us take a closer look what these mean.
Variant is a tagged universal type that can hold up to 16 MB of any data type supported by Snowflake. Variants are stored as columns in relational tables. Array is a list-like indexed data type that consists of variant values. Object, on the other hand, is a data type that consist of key-value pairs, where key is a not-null string and value is variant type data.
Snowflake provides guidelines on handling semi-structured data on their documentation. As a baseline, they recommend to store semi-structured data as variant data type, if usage for data is unsure. However, it is stated that when the usage is known, recommendation is to perform test cases to find solution with the best performance. Let us take a look what kind of differences might occur.
Test setup
For testing purposes, we create three different tables:
Table with 500 million rows
Table with variant column having 500 million values
Table with array column having 500 million values
The traditional table includes user identifier, which is a random field between values 1 and 5 million and amount field, which is integer value between values 1 and 500 million. Variant and array tables are both grouped tables. These are created with the traditional table as their source. Schema has user identifier and variant or array typed value field, which has aggregated list of the values for certain user identity. The tables are created with following queries:
CREATE TABLE T_500M (
user_id INT,
amount INT);INSERT INTO T_500M
SELECT UNIFORM (1, 5000000, random())
, UNIFORM (1, 500000000, random())
FROM TABLE ( GENERATOR ( ROWCOUNT => 50000000 ));CREATE TABLE T_500M_VARIANT AS
SELECT user_id,
, CAST(ARRAY_AGG(amount) AS VARIANT) AS variant_field
FROM T_500M
GROUP BY user_id;CREATE TABLE T_500M_ARRAY AS
SELECT user_id
, ARRAY_AGG(amount) AS array_field
FROM T_500M
GROUP BY user_id;
Evaluating performance
Storing values as variant or array might seem like a good idea, if we want to aggregate sums on amount field for every user identity. As a query result, we want to show user identifier, count number of occurrences for that user and aggregated sum for the amount field. We can achieve it for each table with following queries:
SELECT user_id
, COUNT(*) AS value_count
, SUM(amount) AS sum
FROM T_500MGROUP BY user_id;SELECT user_id , COUNT(flat_variant.value) AS value_count , SUM(flat_variant.value::INTEGER) AS sumFROM T_500M_VARIANT , lateral flatten(INPUT => variant_field) flat_variantGROUP BY user_id;SELECT user_id , COUNT(flat_array.value) AS value_count , SUM(flat_array.value::INTEGER) AS sum
FROM T_500M_ARRAY , lateral flatten(INPUT => array_field) flat_arrayGROUP BY user_id;
Select-clause takes 15.6 seconds for the traditional relational table, 22.1 seconds with variant table and 21.9 seconds with array table. The difference is significant with the queries being over 40 % slower for semi-structured tables.
Another thing to consider with semi-structured formats is that queries on semi-structured data will not use result cache. We can notice this by running the queries again. The traditional table query takes only 0.2 seconds thanks to Snowflake’s persisted query results, but the queries to other tables take the same circa 22 seconds as earlier to complete.
The tested difference in our query time between structured data table and table with semi-structured data type exists, but it is still acceptable in some cases, where loading semi-structured data is a lot easier to variant or array columns. However, it needs to be noted, as stated in Snowflake documentation, query performance for data types that are not native for JSON are even worse for tables using variant or array. Shown test included only native JSON data types, but including for example datetime as variant would make the difference even bigger.
Explicit data type conversion
It is important to pay attention to the data types when accessing array or variant data. Consider the following example, where we query total sum of the amount-field with following select-statement on the variant table:
SELECT COUNT (*) AS row_count , SUM(flat_variant.value) AS sum_without_cast , SUM(flat_variant.value)::INTEGER AS cast_after_sum , SUM(flat_variant.value::INTEGER) AS cast_before_sumFROM T_500M_VARIANT , lateral flatten(INPUT => variant_field) flat_variant;
For query results, we get three different sums: No specified casting: 1.24998423949572e+17 Casting before sum: 124998423949572384 Casting after sum: 124998423949572368
The same sum amounts are received when running the above query for the array table. Difference comes from Snowflake’s calculations, where variant and array are handled using JavaScript. JavaScript language uses Float as data type for numeric values. As shown in the earlier blog post using floating-point numeric data types, may lead to imprecise values. Even though the table only has fixed-point numeric values, using variant or array converts them to floating points unless determined explicitly when querying data.
Conclusion
Possibility to store semi-structured data in relational tables on Snowflake comes in handy for many business needs that do not have traditional relational source data. It enables loading semi-structured data straight to Snowflake and parsing data onwards from there. Even though this is possible, it should be tested per use case whether it is the best solution.
When evaluating query performance we noticed that querying tables with semi-structured data types, the select-clauses resulted in being 40 % slower compared to similar table with structured data types. This is with JavaScript native data types, while non-native types will result in even bigger difference for execution time. Semi-structured data types can’t utilize result cache, so re-running the queries will take similar time as the initial one.
Best practice is converting data types explicitly, when accessing variant or arrays. Snowflake engine uses JavaScript to handle these data types, so as was shown, numeric values may suffer from rounding.
In June 2018, AWS Lambda added Amazon Simple Queue Service (SQS) to supported event sources, removing a lot of heavy lifting of running a polling service or creating extra SQS to SNS mappings. In a recent project we utilized this functionality and configured our data pipelines to use AWS Lambda functions for processing the incoming data items and SQS queues for buffering them. The built-in functionality of SQS and Lambda provided us serverless, scalable and fault-tolerant basis, but while running the solution we also learned some important lessons. In this blog post I will discuss the issue of valid messages ending up in dead-letter queues (DLQ) and correctly configuring your DLQ to catch only erroneous messages from your source SQS queue.
In brief, Amazon SQS is a lightweight, fully managed message queueing service, that enables decoupling and scaling microservices, distributed systems and serverless applications. With SQS, it is easy to send, store, and receive messages between software components, without losing messages.
AWS Lambda is a fully managed, automatically scaling service that lets you run code in multiple different languages in a serverless manner, without having to provision any servers. You can configure a Lambda function to execute on response to various events or orchestrate the invocations. Your code runs in parallel and processes each invocation individually, scaling with the size of the workload.
When you configure an SQS queue as an event source for your Lambda, Lambda functions are automatically triggered when messages arrive to the SQS queue. The Lambda service automatically scales up and down based on the number of inflight messages in the queue. The polling, reading and removing of messages from the queue will be thus automatically handled by the built-in functionality. Successfully processed messages will be removed and the failed ones will be returned to the queue or forwarded to the DLQ, without needing to explicitly configure these steps inside your Lambda function code.
Problems with valid messages ending up in DLQ
In the recent project we needed to process data that would be coming in daily as well as in larger batches with historical data loadings through the same data processing pipeline. In order to handle changing data loads, SQS decouples the source system from processing and balances the load for both use cases. We used SQS for queueing metadata of new data files and Lambda function for processing the messages and passing on metadata to next steps in the pipeline. When testing our solution with pushing thousands of messages rapidly to the queue, we observed many of the messages ending up in a dead-letter queue, even though they were not erroneous.
From the CloudWatch metrics, we found no execution errors during the given period, but instead there was a peak in the Lambda throttling metric. We had configured a DLQ to catch erroneous messages, but ended up having completely valid and unprocessed messages in the DLQ. How does this happen? To understand this, let’s dive deeper into how Lambda functions are triggered and scaled when they have SQS configured as the event source.
Lambda scales automatically with the number of messages arriving to SQS – up to a limit
Let’s first introduce briefly the parameters of SQS and Lambda that are relevant to this problem.
SQS
ReceiveMessageWaitTimeSeconds: Time that the poller waits for new messages before returning a response. Your messages might be arriving to the SQS queue unevenly, sometimes in bursts and sometimes there might be no messages arriving at all. The default value is 0, which equals constant polling of messages. If the queue is empty and your solution allows some lag time, it might be beneficial not to poll the queue all the time and return empty responses. Instead of polling for messages constantly, you can specify a wait time between 1 and 20 seconds.
VisibilityTimeout: The length of time during which a message will be invisible to consumers after the message is read from the queue. When a poller reads a message from the SQS queue, that message still stays in the queue but becomes invisible for the period of VisibilityTimeout. During this time the read message will be unavailable for any other poller trying to read the same message and gives the initial component time to process and delete the message from the queue.
maxReceiveCount: Defines the number of times a message can be delivered back to being visible in the source queue before moving it to the DLQ. If the processing of the message is successful, the consumer will delete it from the queue. When ever an error occurs in processing of a message and it cannot be deleted from the queue, the message will become visible again in the queue with an increased ReceiveCount. When the ReceiveCount for a message exceeds the maxReceiveCount for a queue, message is moved to a dead-letter queue.
Lambda
Reserved concurrency limit: The number of executions of the Lambda function that can run simultaneously. There is an account specific limit how many executions of Lambda functions can run simultaneously (by default 1,000) and it is shared between all your Lambda functions. By reserving part of it for one function, other functions running at the same time can’t prevent your function from scaling.
BatchSize:The maximum number of messages that Lambda retrieves from the SQS queue in a single batch. Batchsize is related to the Lambda event source mapping, which defines what triggers the Lambda functions. In this case they are triggered from SQS.
In the Figure 1 below, it is illustrated how Lambda actually scales when messages arrive in bursts to the SQS queue. Lambda uses long polling to poll messages in the queue, which means that it does not poll the queue all the time but instead on an interval between 1 to 20 seconds, depending on what you have configured to be your queue’s ReceiveMessageWaitTimeSeconds. Lambda service’s internal poller reads messages as batches from the queue and invokes the Lambda function synchronously with an event that contains a batch of messages. The number of messages in a batch is defined by the BatchSize that is configured in the Lambda event source mapping.
When messages start arriving to the queue, Lambda reads first up to 5 batches and invokes a function for each. If there are messages still available, the number of processes reading the batches are increased by up to 60 more instances per minute (Figure 2), until it reaches the 1) reserved concurrency limit configured for the Lambda function in question or 2) the account’s limit of total concurrent Lambda executions (by default 1,000), whichever is lower (N in the figure).
By setting up a reserved concurrency limit for your Lambda, you guarantee that it will get part of the account’s Lambda resources at any time, but at the same time you also limit your function from scaling over that limit, even though there would be Lambda resources available for your account to use. When that limit is reached and there are still messages available in the queue, one might assume that those messages will stay visible in the queue, waiting until there’s free Lambda capacity available to handle those messages. Instead, the internal poller still tries to invoke new Lambda functions for all the new messages and therefore causes throttling of the Lambda invokes (figure 2). Why are some messages ending up in DLQ then?
Let’s look at how the workflow goes for an individual message batch if it succeeds or fails (figure 3). First, the Lambda internal poller reads a message batch from the queue and those messages stay in the queue but become invisible for the length of the configured VisibilityTimeout. Then it invokes a function synchronously, meaning that it will wait for a response that indicates a successful processing or an error, that can be caused by e.g. function code error, function timeout or throttling. In the case of a successful processing, the message batch is deleted from the queue. In the case of failure, however, the message becomes visible again.
The SQS queue is not aware of what happens beyond the event source mapping, if the invocations are failed or throttled. It keeps the messages in the queue invisible, until they get either deleted or turned back to visible after the length of VisibilityTimeout has passed. Effectually this means that throttled messages are treated as any other failed messages, so their ReceiveCount is increased every time they are made visible in the queue. If there is a huge burst of messages coming in, some of the messages might get throttled, retried, throttled again, and retried again, until they reach the limit of maxReceiveCount and then moved to the DLQ.
The automatic scaling and concurrency achieved with SQS and Lambda sounds promising, but unfortunately like all AWS services, this combination has its limits as well. Throttling of valid messages can be avoided with the following considerations:
Be careful when configuring a reserved concurrency to your Lambda function: the smaller the concurrency, the greater the chance that the messages get throttled. AWS suggests the reserved concurrency for a Lambda function to be 5 or greater.
Set the maxReceiveCount big enough in your SQS queue’s properties, so that the throttled messages will eventually get processed after the burst of messages. AWS suggest you set it to 5 or greater.
By increasing message VisibilityTimeout of the source queue, you can give more time for your Lambda to retry the messages in the case of message bursts. AWS suggests this to be set to at least 6 times the timeout you configure to your Lambda function.
Of course, tuning these parameters is an act of balancing with what best suits the purpose of your application.
Configuring DLQ to your SQS and Lambda combination
If you don’t configure a DLQ, you will lose all the erroneous (or valid and throttled) messages. If you are familiar with the topic this seems obvious, but it’s worth stating since it is quite important. What is confusing now in this combo, is that you can configure a dead-letter queue to both SQS and Lambda. The AWS documentation states:
“Make sure that you configure the dead-letter queue on the source queue, not on the Lambda function. The dead-letter queue that you configure on a function is used for the function’s asynchronous invocation queue, not for event source queues.“
To understand this one needs to dive into the difference between synchronous and asynchronous invocation of Lambda functions.
When you invoke a function synchronously Lambda runs the function and waits for a response from it. The function code returns the response, and Lambda returns you this response with some additional data, including e.g. the function version. In the case of asynchronous invocation, however, Lambda sends the invocation event to an internal queue. If the event is successfully sent to the internal queue, Lambda returns success response without waiting for any response from the function execution, unlike in synchronous invocation. Lambda manages the internal queue and attempts to retry failed events automatically with its own logic. If the execution of the function is failing after retries as well, the event is sent to the DLQ configured to the Lambda function. With event source mapping to SQS, Lambda is invoked synchronously, therefore there are no retries like in asynchronous invocation and the DLQ on Lambda is useless.
Recently, AWS launched Lambda Destinations, that makes it possible to route asynchronous function results to a destination resource that can be either SQS, SNS, another Lambda function or EventBridge. With DLQs you can handle asynchronous failure situations and catch the failing events, but with Destinations you can actually get more detailed information on function execution in both success and failure, such as code exception stack traces. Although, Destinations and DLQs can be used together and at the same time, AWS suggests Destinations should be considered a more preferred solution.
Conclusions
The described problems are all stated and deductible from the AWS documentation, but still not completely obvious. With carefully tuning the parameters of our SQS queue, mainly by increasing the maxReceiveCount and VisibilityTimeOut, we were able to overcome the problems with Lambda functions throttling. With configuring the DLQ to the source SQS queue instead of configuring it to Lambda, we were able to catch erroneous or throttled messages. Although adding a DLQ to your source SQS does not solve anything by itself, but you also need to handle the failing messages in some way. We configured a Lambda function also to the DLQ to write the erroneous messages to DynamoDB. This way we have a log of the unhandled messages in DynamoDB and the messages can be resubmitted or investigated further from there.
Of course, there are always several kinds of architectural options to solve these kind of problems in AWS environment. Amazon Kinesis, for example, is a real-time stream processing service, but designed to ingest large volumes of continuous streaming data. Our data, however, comes in uneven bursts, and SQS acts better for that scenario as a message broker and decoupling mechanism. One just needs to be careful with setting up the parameters correctly, as well as be sure that the actions intended for the Lambda function will execute within Lambda limits (including 15 minutes timeout and 3,008 MB maximum memory allocation). The built-in logic with Lambda and SQS enabled the minimal infrastructure to manage and monitor as well as high concurrency capabilities within the given limits.
Fixed-point numerical data types should be the default choice when designing Snowflake relational tables. Using floating-point data types has multiple downsides, which are important to understand. The effect of choosing different numerical data type can be easily tested.
Snowflake numeric data types can be split in two main categories: fixed-point numbers and floating-point numbers. In this blog post we are going to look at what these mean from Snowflake database design point of view, and especially should you use floating type when dealing with numeric data?
Fixed-point numbers are exact numeric values, which include data types such as number, integer and decimal. For these data types, developer can determine precision (allowed number of digits in column) and scale (number of digits right of the decimal point). In Snowflake, all fixed-point numeric data types are actually type decimal with precision 38 and scale 0, if not specified differently. Typical use cases for fixed-point data types are natural numbers and exact decimal values, such as monetary figures, where they need to be stored precisely.
On the other side of the spectrum are floating-point numbers, which are approximate representations of numeric values. In Snowflake, floating-point columns can be created with key-words float, double, double precision or real. However, as the Snowflake documentationstates, all of these data types are actually stored as double and they do not have difference in precision, but displayed as floats. Floating-point data types are mainly used in mathematics and science to simplify the calculations with scientific notation. Storing numbers with major differences in magnitude is their advantage in databases too, because zeros trailing or following the decimal sign does not consume memory as it does for decimal format. In traditional computing, floats are considered faster for computation, but is that really the case in modern database design?
Floating-point precision
First, let us explore inserting data on Snowflake into table with float as numeric data type. We create a table and insert 500 million rows of generated dummy data to the table with following query:
CREATE TABLE T_FLOAT_500M ( id INT, float_field FLOAT );INSERT INTO T_FLOAT_500M SELECT SEQ8() , UNIFORM(1, 500000000, RANDOM())::FLOAT FROM TABLE ( GENERATOR ( ROWCOUNT => 500000000 ) );
To see the effect of using float as the data type for big numeric values, we can run the following query:
SELECT SUM(float_field) AS NO_CONVERSION, SUM(float_field::INT) AS CONVERT_VALUES_SEPARATELY , SUM(float_field)::INT AS CONVERT_SUM_VALUEFROM T_FLOAT_500M;
Sum without the conversion produces us a rounded number with scientific notation: 1.24997318579082e+17 Separately converted values sum produces result: 124997318579081654 Conversion made after the calculation produces sum value: 124997318579081664
From the sum results, we will notice the accuracy problem related to storing numeric values as floats as the sum results differ from each other. When dealing with large or extremely accurate numeric values, floats may cause differentiation in results due to their nature of being approximate representations. Same effect can be seen when using WHERE clauses as the approximate representations may not work as designed with conditions that point to exact numeric values.
Storage size of float
Next, we create a similar table as earlier, but with the second field being type integer and populate it without converting random figures to floats.
CREATE TABLE T_INT_500M ( id INT, int_field INT);INSERT INTO T_INT_500M SELECT SEQ8() , UNIFORM(1, 500000000, RANDOM())::INT FROM TABLE ( GENERATOR ( ROWCOUNT => 500000000 ) );SHOW TABLES LIKE '%_500M';
Looking at the Snowflake table statistics, we will notice integer table is smaller (3.37 GB) compared to the float table (5.50 GB). The difference in table sizes is significant with the float table being 63 % bigger. This can be explained by Snowflake reserving 64 bits of memory for every float value. Integer values on the other hand are stored in compressed format and take only the necessary amount of memory.
This difference is seen also on SELECT queries, where querying all rows with X-Small warehouse takes only 85 seconds for integer type table compared to the 160 seconds with the float type table. Difference is once again major.
Summary
Floats still have their use cases with numbers that have majorly different magnitudes. But from the presented test cases, we can draw a conclusion that using floating-point data types will lead to bigger storage sizes and longer query times, which result as an increase to data warehousing costs. Another thing to consider is the possibility of imprecise values, when dealing with extremely accurate data. Whenever possible, it is recommended not to use float as a type for numeric data without a specific reason. Especially precise and whole numbers are not meant to be stored as floats and should be given appropriate data types.
At re:Invent one can only admire the amount of new innovations that AWS publishes. There were 339 announcements before the event even started. I had change to attend some sessions at this years re:Invent to get better understanding of Amazons innovation culture.
It all starts with the customer and finally ends in one. At Amazon everything stems from the company’s mission; “To be earth’s most customer-centric company”. Start by identifying what the customer needs and innovate solutions from there. Jeff Bezos has stated in letter to shareholders that “customers are always beautifully, wonderfully dissatisfied”. It is the same thing that Henry Ford said many years ago, customers do not know what they want. Amazon is not trying to build faster horse, but something that will delight customers needs. Amazon is after minimum lovable product (MLP).
Innovation needs structure and at Amazon innovation organises around four concepts that interconnect. They are culture, mechanism, architecture and organisation. Culture builds around 14 leadership principles and these are the core of innovation. Principles are guidelines to help people bring the best out of them, they challenge everyone to be curious, take responsibility, challenge status quo, move fast and think long term. Amazon uses data and makes calculated risk, but speed matters so they have some guidelines to help this. Some decision can be considered one-way door as others two-way. Decision can be seen as two-way door if it can be reversed, then risk is lower, and one should move with speed. It is also interesting to hear, that Amazon pushes leaders to make decision when they have only around 70% of needed data.
Amazon does 198 million deployments a year
Architecture of Amazon allows rapid development. Amazon architecture went from one monolith to micro services and this allowed them to move from quarterly change cycle to 198 million deployments a year. The transformation from monolith to micro service was based on idea of Conway’s law that states “organisations which design systems … are constrained to produce designs which are copies of the communication structures of these organisations.” Amazon mapped the communication structured of their organisation and came up with two-pizza-teams (American pizza) that are made up of 4-8 people. These decentralised teams have freedom and responsibility and are able to fail fast. I had change to talk to many AWS employees and to my surprise they all had same feeling about working for Amazon. To them it felt like working for a startup. This is somewhat amazing when we are talking about company with 750 000 employees.
Mechanism to innovate is the backwards working process. Backwards process is a very cumbersome process that starts with identifying customer and customer need. To understand customer, there are five questions. Who is the customer, what is the problem or opportunity, what is the benefit, how to quantify this, what does the experience look like? Customer is always a person. Once the customer and the need have been clearly understood and validated with data, one can start brainstorming boundless, big and bold ideas. After this it is time to draft fictional press release, internal and external FAQ’s and finally visual of the customer experience. This press release is a way to democratise the idea, so that all people would have similar opportunity to share their idea. All meetings around the idea start by all members reading the paper and iterating over it. All this is done by the team created around the idea, before a single line of code is written. This is heavy process, but its purpose is to make sure that what you build is for customers need.
It was said that out of press release drafted by Andy Jassy, iterated 45 times, came AWS. Also, Amazon prime was built from press release. There have of course been mistakes, such as Amazon Fire phone, lessons learned, and that was base to produce Alexa. There is no magic in this, just hard work. To build something for the customer, one has to start with the customer.
Machine learning continues to grow on AWS and they are putting serious effort on paving the way for customers’ machine learning development journey on AWS cloud. The Andy Jassy keynote in AWS Re:Invent was a fiesta for data scientists with the newly launched Amazon SageMaker features, including Experiments, Debugger, Model Monitor, AutoPilot and Studio.
AWS really aims to make the whole development life cycle of machine learning models as simple as possible for data scientists. With the newly launched features, they are addressing common, effort demanding problems: monitoring your data validity from your model’s perspective and monitoring your model performance (Model Monitor), experimenting multiple machine learning approaches in parallel for your problem (Experiments), enable cost efficiency of heavy model training with automatic rules (Debugger) and following these processes in a visual interface (Studio). These processes can even be orchestrated for you with AutoPilot, that unlike many services is not a black box machine learning solution but provides all the generated code for you. Announced features also included a SSO integrated login to SageMaker Studio and SageMaker Notebooks, a possibility to share notebooks with one click to other data scientists including the needed runtime dependencies and libraries (preview).
Compare and try out different models with SageMaker Experiments
Building a model is an iterative process of trials with different hyperparameters and how they affect the performance of the model. SageMaker Experiments aim to simplify this process. With Experiments, one can create trial runs with different parameters and compare those. It provides information about the hyperparameters and performance for each trial run, regardless of whether a data scientist has run training multiple times, has used automated hyperparameter tuning or has used AutoPilot. It is especially helpful in the case of automating some steps or the whole process, because the amount of training jobs run is typically much higher than with traditional approach.
Experiments makes it easy to compare trials, see what kind of hyperparameters was used and monitor the performance of the models, without having to set up the versioning manually. It makes it easy to choose and deploy the best model to production, but you can also always come back and look at the artifacts of your model when facing problems in production. It also provides more transparency for example to automated hyperparameter tuning and also for new SageMaker AutoPilot. Additionally, SageMaker Experiments has Experiments SDK so it is possible call the API with Python to get the best model programmatically and deploy endpoint for it.
Track issues in model training with SageMaker Debugger
During the training process of your model, many issues may occur that might prevent your model from correctly finishing or learning patterns. You might have, for example, initialized parameters inappropriately or used un efficient hyperparameters during the training process. SageMaker Debugger aims to help tracking issues related to your model training (unlike the name indicates, SageMaker Debugger does not debug your code semantics).
When you enable debugger in your training job, it starts to save the internal model state into S3 bucket during the training process. A state consists of for example weights for neural network, accuracies and losses, output of each layer and optimization parameters. These debug outputs will be analyzed against a collection of rules while the training job is executed. When you enable Debugger while running your training job in SageMaker, will start two jobs: a training job, and a debug processing job (powered by Amazon SageMaker Processing Jobs), which will run in parallel and analyze state data to check if the rule conditions are met. If you have, for example, an expensive and time consuming training job, you can set up a debugger rule and configure a CloudWatch alarm to it that kills the job once your rules trigger, e.g. loss has converged enough.
For now, the debugging framework of saving internal model states supports only TensorFlow, Keras, Apache MXNet, PyTorch and XGBoost. You can also configure your own rules that analyse model states during the training, or some preconfigured ones such as loss not changing or exploding/vanishing gradients. You can use the debug feature visually through the SageMaker Studio or alternatively through SDK and configure everything to it yourself.
Keep your model up-to-date with SageMaker Model Monitor
Drifts in data might have big impact on your model performance in production, if your training data and validation data start to have different statistical properties. Detecting those drifts requires efforts, like setting up jobs that calculate statistical properties of your data and also updating those, so that your model does not get outdated. SageMaker Model Monitor aims to solve this problem by tracking the statistics of incoming data and aims to ensure that machine learning models age well.
The Model Monitor forms a baseline from the training data used for creating a model. Baseline information includes statistics of the data and basic information like name and datatype of features in data. Baseline is formed automatically, but automatically generated baseline can be changed if needed. Model Monitor then continuously collects input data from deployed endpoint and puts it into a S3 bucket. Data scientists can then create own rules or use ready-made validations for the data and schedule validation jobs. They can also configure alarms if there are deviations from the baseline. These alarms and validations can indicate that the model deployed is actually outdated and should be re-trained.
SageMaker Model Monitor makes monitoring the model quality very easy but at the same time data scientists have the control and they can customize the rules, scheduling and alarms. The monitoring is attached to an endpoint deployed with SageMaker, so if inference is implemented in some other way, Model Monitor cannot be used. SageMaker endpoints are always on, so they can be expensive solution for cases when predictions are not needed continuously.
Start from scratch with SageMaker AutoPilot
SageMaker AutoPilot is an autoML solution for SageMaker. SageMaker has had automatic hyperparameter tuning already earlier, but in addition to that, AutoPilot takes care of preprocessing data and selecting appropriate algorithm for the problem. This saves a lot of time of preprocessing the data and enables building models even if you’re not sure which algorithm to use. AutoPilot supports linear learner, factorization machines, KNN and XGBboost at first, but other algorithms will be added later.
Running an AutoPilot job is as easy as just specifying a csv-file and response variable present in the file. AWS considers that models trained by SageMaker AutoPilot are white box models instead of black box, because it provides generated source code for training the model and with Experiments it is easy to view the trials AutoPilot has run.
SageMaker AutoPilot automates machine learning model development completely. It is yet to be seen if it improves the models, but it is a good sign that it provides information about the process. Unfortunately, the description of the process can only be viewed in SageMaker Studio (only available in Ohio at the moment). Supported algorithms are currently quite limited as well, so the AutoPilot might not provide the best performance possible for some problems. In practice running AutoPilot jobs takes a long time, so the costs of using AutoPilot might be quite high. That time is of course saved from data scientist’s working time. One possibility is, for example, when approaching a completely new data set and problem, one might start by launching AutoPilot and get a few models and all the codes as template. That could serve as a kick start to iterating your problem by starting from tuning the generated code and continuing development from there, saving time from initial setup.
SageMaker Studio – IDE for data science development
The launched SageMaker Studio (available in Ohio) is a fully integrated development environment (IDE) for ML, built on top of Jupyter lab. It pulls together the ML workflow steps in a visual interface, with it’s goal being to simplify the iterative nature of ML development. In Studio one can move between steps, compare results and adjust inputs and parameters. It also simplifies the comparison of models and runs side by side in one visual interface.
Studio seems to nicely tie the newly launched features (Experiments, Debugger, Model Monitor and Autopilot) into a single web page user interface. While these new features are all usable through SDKs, using them through the visual interface will be more insightful for a data scientist.
Conclusion
These new features enable more organized development of machine learning models, moving from notebooks to controlled monitoring and deployment and transparent workflows. Of course several actions enabled by these features could be implemented elsewhere (e.g. training job debugging, or data quality control with some scheduled smoke tests), but it requires again more coding and setting up infrastructure. The whole public cloud journey of AWS has been aiming to simplify development and take load away by providing reusable components and libraries, and these launches go well with that agenda.
AWS Redshift is the world’s most popular data warehouse, but has faced some tough competition from the market. AWS Redshift has the compute and storage coupled, meaning that with the specific amount of instance you get set of storage that sometimes can be limiting. At the Andy Jassy keynote AWS released a new managed storage model for Redshift that allows you to scale the compute decoupled from the storage.
The storage model uses SSDs and S3 for the storage behind the scenes and is utilising architectural improvements of the infrastructure. This allows to users to keep the hot data in SSD and also query historical data stored in S3 seamlessly from Redshift. On top of this, you only pay for the SSD you use. It also comes with a new Nitro based compute instances. In Ireland RA3 instance has price of $15.578 per node/hour, but you get 48 vCPUs and 384 GB of memory and up to 64 TB of storage. You can cluster these up to 128 instances. AWS promises to give 3x the performance of any other cloud data warehouse service and Redshift Dense Storage (DS2) users are promised to get twice the performance and twice the storage at the same cost. RA3 is available now in Europe in EU (Frankfurt), EU (Ireland), and EU (London).
Related to the decoupling of the compute and storage, AWS released AWS AQUA. Advanced Query Accelerator promises 10 times better query performance. AQUA sits on top of S3 and is Redshift compatible. For this feature we have to wait for mid 2020 to get hands on.
While AWS Redshift is the world’s most popular data warehouse, it is not practical to load all kind of data there. Sometimes data lakes are more suitable places for data, especially for unstructured data. Amazon S3 is the most popular choice for cloud data lakes. New Redshift features help to tie structured and unstructured data together to enable even better and more comprehensive insight.
With Federated Query feature (preview), it is now possible to query data in Amazon RDS PostgreSQL, and Amazon Aurora PostgreSQL from a Redshift cluster. The queried data can then be combined with data in the Redshift cluster, and Amazon S3. Federated queries allows data ingestion into Redshift, without any other ETL tool, by extracting data from above-mentioned data sources, transforming it on the fly, and loading data into Redshift. Data can also be uploaded from Redshift to S3 in Apache Parquet format using Data Lake Export feature. With this feature you are able to build some nice lifecycle features into your design.
“One should use the best tool for the job”, reminded Andy Jassy at the keynote. With long awaited decoupling of storage and compute and big improvements to the core, Redshifts took a huge leap forward. It is extremely interesting to start designing new solutions with these features.
Team Solita participated in Baltic Seabird Hackathon in Gothenburg last week. Based on the huge material and data set available, we decided to introduce pose detection as a method to understand seabird behavior and interactions. The results were promising, yet leave still room to improve.
Some weeks ago we decided to participate in the Baltic Seabird Hackathon in Gothenburg. Hackathon was organised by AI INNOVATION of Sweden, Baltic Seabird Project, WWF, SLU and Chalmers University of Technology. In practise we spent few weeks preparing ourselves, going through the massive dataset and creating some models to work with the data. Finally we travelled to Gothenburg and spent 2 days there to finalise our models, presented the results and of course just spent time with other teams and networked with nice people. In this post we will dive a bit deeper on the process of creating the prediction model for pose detection and the results we were able to create.
Initially we didn’t know that much about seagulls, but during the couple weeks we got to learn wonderful details about the birds, their living habits and social interaction. I bet you didn’t know that the oldest birds are over 45 years old! During the hackathon days in Gothenburg we had many seabird experts available to discuss and ask more challenging questions about the birds. In addition we were given some machine learning and technical experts to support the work in the provided data factory platform. We decided to work in AWS sandbox environment, because it was more natural choice for us.
Our team was selected to have cross-functional expertise in design, data, data science and software development and to be able to work in multi-site setup. During the hackathon we had 3 members working in Gothenburg and 2 members working remotely from Sweden and Finland.
So what did we try and achieve?
Material available
For the hackathon we received some 2000 annotated images and 100+ hours of video from the 2 different camera locations in the Stora Karlsö island. Cameras were installed first time in 2019 so all this material was quite new. The videos were from the beginning of May when the first birds arrive to the same ledge as they do every year and coveraged the life of the birds until beginning of August when most of them had left already.
The images and videos were in Full HD resolution i.e. 1920×1080, which gives really good starting point. The angle of the cameras was above and most of the videos and images looked like the example below. Annotated birds were the ones on the top ledge. There were also videos and images from night time, which made it a bit more harder to predict.
Our idea and approach
Initial ideas from the seabird experts were related to identifying different events in the video clips. They were interested to find out automatically when egg was laid, when birds were leaving and coming back from fishing trips and doing other activities.
We thought that implementing these requirements would be quite straightforward with the big annotation set and thus decided to try something else and took a little different approach. Also because of personal interests we wanted to investigate what pose detection of the birds could provide to the scientists.
First some groundwork – Object detection
Before being able to detect the poses of the birds one needs to identify where the birds are and what kind of birds there are. We were provided with over 2000 annotated images containing annotations for adult birds, chicks and eggs. The amount of annotated chicks and eggs was far less than adult birds and therefore we decided to focus on adult birds. With the eggs there were also issue with the ledge color being similar to the egg color and thus making it much harder to separate eggs from the ledge.
We decided to use ImageAI (https://github.com/OlafenwaMoses/ImageAI) Python library for object detection. It has been built simplicity in mind and therefore it was fast and easy to take into use given the existing annotation set. All we had to do was to transform the existing annotations into PascalVOC format. After all initial setup we trained the model with about 200 images, because we didn’t want to spent too much time in the object detection phase. There is a good tutorial available how to do it with your custom annotation set: https://github.com/OlafenwaMoses/ImageAI/blob/master/imageai/Detection/Custom/CUSTOMDETECTIONTRAINING.md
Even with very lightweight training we were able to get easily over 95% precision for the detections. This was enough for our original approach to focus on poses rather than the activities. Otherwise we probably had continued to develop the object detection model further to identify different activities happening on the ledge as some of the other teams decided to proceed.
Based on these bounding boxes we were able to create 640×640 clips of each bird. We utilised FFMPEG to crop the video clips.
Now we got some action – Pose detection
For years now there has been research and models on detecting human poses from images and videos. Based on these concepts Jake Graving and Daniel Chae have developed DeepPoseKit (https://github.com/jgraving/DeepPoseKit) for detecting poses for animals. They have also focused on making the pose detection much faster than in previous libraries. DeepPoseKit is written in Python and uses in the background TensorFlow and Keras. You can read the paper about the DeepPoseKit here: https://elifesciences.org/articles/47994
The process for utilising DeepPoseKit has 4 main steps:
Create annotation set. This will define the resolution and color of the images used as basis for the model. Also the skeleton (joints and their connections to each other) needs to be defined in csv as a parent-child hierarchy. For the resolution it is probably easiest if the annotation set resolution matches close to what you expect to get from the videos. That way you don’t need to adjust the frames during the prediction phase. For the color scale you should at least consider whether the model works more reliable in gray scale or in RGB color space.
Annotate the images in annotation set. This is the brutal work and requires you to go through the images one by one and marking all skeleton keypoints. The GUI DeepPoseKit provides is pretty simple to use.
Train the model. This definitely takes some time even with GPU. There is also support for augmented data, so you can really improve the model during the training.
Create predictions based on the model.
You can later increase the size of the annotated set and add more images to the set. Also the training can be continued based on existing model and thus the library is pretty flexible.
Because the development of DeepPoseKit is still in the early phases there are at least 2 considerable constraints to remember:
Library can only detect individual poses and if you have multiple animals in the same frames, you need some additional steps to separate the animals
DeepPoseKit only supports image resolutions that can be repeatedly divided by 2 (e.g. 320×320, 640×640)
Because of these limitations and considering our source material, we came up with following process:
So we decided to create separate clips for each identified bird and run pose detection for these clips and then in the end combine the individual pose detection predictions to the original video.
For the skeleton we ambitiously decided to model 16 keypoints. This turned out to be quite a task, but we managed to do it. In the end we also created a simplified version of the skeleton and the annotations including only 3 keypoints (beck, head and tail). The original skeleton included eyes, different parts of the wings and legs.
This is how the annotations for complex skeleton look like:
The simplified skeleton model has only 3 keypoints:
With these 2 annotation sets we were able to create 2 models (simple with 3 keypoints and complex with 16 keypoints).
To train the model we pretty much followed the sample script provided by the developers of DeepPoseKit (https://github.com/jgraving/DeepPoseKit/blob/master/examples/step3_train_model.ipynb). Due to limited time available we did not have time to work so much with the augmented data, which could have improved the accuracy of the models. Running a epoch with 45 steps took with AWS p3.2xlarge instance (1 GPU) about 5-6 minutes for the complex model. We managed to run around 45 epochs in total given a final validation loss around 25. Because the development is never a such straightforward process, we had to start the training of the model from scratch few times during the hackathon.
The results
When the model was about ready, we run the detections for few different videos we had available. Once again we followed the example in DeepPoseKit library (https://github.com/jgraving/DeepPoseKit/blob/master/examples/step4b_predict_new_data.ipynb). Basically we ran through the individual clips and frame by frame create the skeleton prediction. After we had this data together, we transformed the prediction coordinates resolution (640×640) to match the original video resolution (1920×1080). In addition to the original script we fine-tuned the graphs a bit and included for example order number for each skeleton. In the end we had a csv file containing for each identified object for each frame in the video for each identified skeleton keypoint the keypoint coordinates and confidence percentage. We added also the radius and degrees between keypoints and the distance of connected keypoints. Radius could be later used to analyse for example in which direction the bird is moving its head. In practice for one identified bird this generated 160 rows of data per second. Below is a sample dataset generated.
The results looked more promising when we had more simple setup in the area of the camera. Below is an example of 2 birds’ poses visualised with the complex model and the results seems quite ok. The predictions follow pretty well the movement of a bird.
The challenges are more obvious when we add more birds to the frame:
The problem is clear if you look at one of the identified bird and it’s generated 640×640 clip. Because the birds are so close to each other, one frame contains multiple birds and the model starts to mix parts of the birds together.
The video above also shows that the bird on the right upper corner is not correctly modeled when the bird expands its wings. This is just an indication that the annotation set does not include enough various poses of the birds and thus the model doesn’t learn those poses.
Instead if we take the more simple model in use in the busy video, it behaves a bit better. Still it is far from being optimal.
So at this point we were puzzling how to improve the model precision and started to look for additional methods.
Shape detection to the help?
One of the options that came to our mind was to try leave only the identified bird visible in the 640×640 frames. The core of the idea was that when only individual bird would be visible in the frame then the pose detection would not mess up with other birds. Another team had partly used this method to rule out all the birds in the distance (upper part of the image). Due to the shape of the birds nothing standard such as vignette filter would work out of the box.
So we headed out to look for better alternatives and found out Mask RCNN (https://github.com/matterport/Mask_RCNN). It has a bit similar approach to the pose detection that you first have to annotate a lot of pictures and then train the model. Due to the limited time available we had to try using Mask RCNN just with 20 annotated images.
After very quick training it seemed as the model had really low validation loss. But unfortunately the results were not that good. As you can see from the video below only parts of the birds very identified by the shape detection (shapes marked as blue).
So we think this is a relevant idea, but unfortunately we didn’t have time to verify this idea.
Another idea we had was to detect some kind of pattern that would help identify the birds that are a couple. We played around with the idea that by estimating the density map of each individual bird we could identify the couples that have a high density map. If the birds are tracked then the birds that have a high density output would be classified as a couple. This would end up in a lot of possibilities for the scientists to track the couples and do research on their patterns. For this task first thing we have to do is to put a single marker on each individual bird. So instead of tagging the bird as a whole, we instead tag the head of the bird which is a single point. Image the background as black and the top of the head of each individual bird is marked with the color. The Deep learning architectures used for this were UNET and FCRN(Fully Convolutional Regressional Networks). These are the common architectures used when estimating density maps. We got the idea from this blogpost(https://towardsdatascience.com/objects-counting-by-estimating-a-density-map-with-convolutional-neural-networks-c01086f3b3ec) and how it is used to estimate the density maps which is then used to count the number of objects. We ended up using this to identify both the couples and the number of penguins. Sadly the time was not enough to see some reasonable results. But the idea was very much appreciated by the judges and could be something that they could think about and move forward with.
Another idea would be to use some kind of tagging of the birds. That would work as long as the birds remain on the ledge, but in general it might be a bit challenging as the videos are very long and the birds move around the ledge to some extent.
What next?
Well with the provided results we won the 3rd price in the hackathon. According to the jury biggest achievements were related to the pose detection and the possibilities it opens up for science. It seems that there is not much research done for the social interactions of seagulls and our pose detection model could help on that.
It was clear for all of us that we want to donate the money and have now decided to give it as a scholarship for a student who will take the models and work them further for the benefit of seabird science. Will be interesting to see what the models can tell us about the life of the baltic seabirds, their social interaction and in general socioeconimics of Baltic Sea.
On behalf our Team Solita (Mari Harju, Jani Turunen, Kimmo Kantojärvi, Zeeshan Dar and Layla Husain),
Power BI provides easy and readily available tools for report creation and distribution. However, distributing reports outside Power BI Service and to users without Power BI Pro account is limited. Say you have a Power BI report monitoring your Snowflake account usage (https://data.solita.fi/visualize-snowflake-warehouse-cost-using-power-bi/), and you’d like to share that to the development and maintenance team. You don’t want to purchase Power BI Pro licenses and you don’t want to open the report to the whole world. Instead you simply want to show your PBI report on a web page / in your intranet, where users can securely access it – and here’s where Power BI Embedded and Azure Web Apps come in handy!
In this blog post we’ll set up an environment with a Web App, and use a service principal (whose identity we’ll retrieve from Azure Key Vault) to access Power BI Service to retrieve a report for Embedding. All the work will result in a template that is easy to copy for new web applications to embed new reports. We’ll also take a look at some handy modifications to our Web App template for retrieving a desired report page and hiding navigation elements. You don’t need to be familiar with .NET, we’ll be doing only slight modifications to an existing Microsoft template!
Environment
Target environment is presented in the picture below. The goal is to setup the environment in a way that it is easily reusable: for example adding a few more web applications with other reports embedded in them shouldn’t be too much of a trouble.
Power BI Embedded and Web App environment
App Service Plan
Azure App Service Plan provides a pool of resources for App Services running inside the Plan. You can view it a bit like a server farm in old on-premises systems. The main decisions to make are your App Service Plan location (West Europe, US East, etc…) and the amount and level of resources available inside that Plan: number and size of instances, pricing tier. Start small when developing and scale up as required. As always, refer to Azure documentation for up-to-date information on different service levels: https://docs.microsoft.com/en-us/azure/app-service/overview-hosting-plans
App Service
Azure App Service provides infrastructure for a single application inside an App Service Plan. Each App Service receives a URL pointing to that particular App Service: for example https://ourprojectsnowflakemonitoring.azurewebsites.net. Our embedded report is a web application running in App Service. We’ll be using App Service managed identity to identify our application to Azure Key Vault. And lastly we can use App Service network configurations to restrict access to our application.
Web application
A web application running in Azure App Service can be written in a number of languages. We’ll be using a template provided by Microsoft from https://github.com/microsoft/PowerBI-Developer-Samples/tree/master/App%20Owns%20Data. We’ll modify the template so that we can retrieve configurations from Azure Key Vault, namely our Service Principal information. We will also use application settings so we can easily copy our web app for new embedded reports.
Azure Key Vault
Key Vault provides a secure place for accessing and storing secrets. In this example, we’ll be storing our Service Principal credentials there, and allowing access to our App Service.
Service Principal
Service Principal can be seen as a technical account in Azure AD. It offers a way to authenticate as a service, not as a user. Using Service Principals to authenticate your applications to Power BI Service is a more scalable way: say you have multiple workspaces and multiple applications using the reports: creating, managing and authorising multiple service principals is simpler than multiple “Master Users”. For much more detailed documentation, please refer to https://docs.microsoft.com/en-us/power-bi/developer/embed-service-principal.
Power BI Embedded
Power BI Embedded provides Power BI capacity outside Power BI Service. We can setup workspaces to use the Embedded capacity and provide the reports to outside users via web apps. Power BI Embedded comes in three capacities: A for capacity in Azure, EM for volume licensing, and P for Premium licence. Unless you already have volume licensing or Premium capacity, you would most probably want to use A capacity bought from Azure.
Power BI Service, Workspace and Report
The Embedded report resides as usual in Power BI Service in a Workspace that is assigned to use Embedded capacity. As we are using Service Principal, our Workspace needs to be V2, and we need to allow Service Principals to use it.
Environment setup
Terraform
I’m used to creating my environments using Terraform (https://www.terraform.io/). There’s a lot of blog posts out there discussing why you should or shouldn’t use Terraform in Azure. I personally like the easy readability and reusability of it.
Using Terraform in Azure and setting up a CI/CD pipeline from Azure DevOps is a topic for another blog post. Here, we’ll focus more on setting up our environment and the different configurations we require. So don’t worry right now about the Terraform syntax, let’s focus more on the output.
We are creating an App Service Plan sized D1 and Shared tier. This is suitable for development and testing.
Then we add an App Service to previously created App Service Plan. We set the App Service to get a “System Assigned” identity. Using SystemAssigned identity, our newly created web app receives an Azure AD identity which we then authorize to access Azure Key Vault to retrieve Service Principal Secrets. This way we don’t have to authorize anything else (for example another service principal) besides the application itself to retrieve the secret.
We also set an app_settings block. These are application configurations, which will override the configurations set in code. These will become handy later on.
Creating a key vault is pretty straight forward. What is special here is that we grant “get” and “list” permissions to the system assigned identity of our App Service: the tenant_id and object_id are dynamically referencing the corresponding outputs of the system assigned identity. No need to hardcode anything.
Remember to restrict access to your web app if required. For example, restrict access to only your offices’ and vpn’s IPs.
Service Principal
Next, we need a service principal. Service principal is a technical account which accesses Power BI Service and REST APIs. It doesn’t require any licenses and it can’t login via app.powerbi.com. More info about Service Principal in Power BI Embedded context can be found from https://docs.microsoft.com/en-us/power-bi/developer/embed-service-principal.
Here the actual values are retrieved from another place. We don’t want to store sensitive information in plaintext in Terraform.
Power BI Service and Workspace
Setting up a Power BI Embedded can be a bit of a hassle and documentation is spread around. A more complete guide is a topic of it’s own blog post, so here’s a short summary of what needs to be done:
Create Power BI Embedded capacity in Azure. That means A-tier capacity (P-tier is for Premium, and EM for volume licensing). Note that Embedded capacity should be in the same region as your Power BI Service is. Don’t forget to add capacity admin.
Add Embedded capacity to your Power BI Service
Assign a Workspace V2 to Embedded capacity. As we are using Service Principals, we need to use a Workspaces V2.
Allow Service Principals in Tenant settings
Allow service principals in the Workspace with your Reports you want to Embed.
Power BI Report for Embedding
Now that everything else is ready we still need the actual report and the web page to display and embed the report. The embedded report resides as usual in Power BI Service, published in our Workspace V2 added to Embedded capacity.
Open your report, and publish it to the correct workspace. Note that you will need a Power BI Pro license to do so.
After publishing, the parameters we require for embedding are Report and Workspace Id. These you can retrieve from your published report. Open your report and look at the url:
Here the part after “groups/” is your workspace ID. The part after “reports/” is your report ID.
You might remember we had an app settings block in our web app:
Now we have empty web app capacity which has access to Azure Key Vault to retrieve Service Principal ID and secret in order to access our Power BI. All that is left is the web application itself.
Web App
Our web app will be a simple web page which shows the report from Power BI. We’ll be using the template with no further authentication. The template is called “app owns data”. It is advisable to restrict web app access to your office IPs for example.
Download a copy of the project, and open up the PowerBIEmbedded_AppOwnsData.sln in Visual Studio. The template requires some modifications:
Reference the Key Vault for secrets
Use the Key Vault as a source for configurations
Besides Key Vault, we’ll also use application settings (set before, report ID and workspace ID) as a source for configurations. This happens automatically, and doesn’t require any modifications.
Setup Azure Key Vault
Let’s add our Key Vault as a connected service:
Select the Key Vault we just created. Note, you might need to add access rights to yourself depending on your setup!
Use Key Vault as a source for configurations
Update and add NuGet packages:
You’ll want to update the already existing packages. We also need to add one NuGet package in order for us to use Azure Key Vault as a config source. Add NuGet package:
Now we want to modify our configurations. Open the web.config file. At the start of the file, add configBuilders section (modify “yourkeyvaultname” to match your keyvault). Also add configBuilders=”AzureKeyVault” to appSettings block.
For local debugging, you can add workspaceId and reportId. However, the app_settings values we previously set for web application in Azure will override anything you set in here.
<!-- Fill Tenant ID in authorityUrl--> <add key="authorityUrl" value="https://login.microsoftonline.com/common/f4nnnnn-nnnn-nnnn-nnnn-nnnnnnnnnnnn" />
You need to add empty key-value pairs for every Key Vault secret you want to import! Let’s say our ServicePrincipal secret is called “servicePrincipalClientSecret”. To import it, we need to add the following line in app settings:
The actual values are fetched from Azure Key Vault.
Use configuration values in our application
Check what configuration values map to what values in application: Modify Services/EmbedService.cs In our example, we need to configure ApplicationSecret to point to servicePrincipalClientSecret, and ApplicationId to point to servicePrincipalClientId. This is at the very start of the file:
A web page should open. Click on Embed report, and it should open a report for you!
And that’s it! You’ve successfully set-up a Web App, which connects to a Key Vault using a managed identity, to get client secrets, and then uses those secrets to identify as a Service Principal to Embed a Power BI report to your web page! That was a mouthful; in other words, you are using application specific secrets the correct way and not some hard-coded human-impersonating Power BI account.
Publish our Web App
All that is left is to publish our web app:
Let’s use our previously created web app:
Click OK and then publish, and you are good to go! You might want restrict access to your web app only to your office and vpn IPs.
Some modifications
Disable filter and navigation panes from report
Say you are showing your report in a non-interactive way (a TV screen for example). You might want hide redundant filter and navigation panes from the view:
Modify Views/Home/EmbedReport.cshtml. Find the following:
You have a nice report showing on your TV with navigations and filters disabled. Nice. Now you’d like to show different pages from that report based on a URL.
Modify Controllers/HomeController.cs
Add ReportPage to EmbedReport:
public async Task<ActionResult> EmbedReport(string username, string roles, int ReportPage = 0)
The zero in ReportPage means that by default we’ll open the first page.
Modify Views/Home/EmbedReport.cshtml.
Change the end of the file from:
// Embed the report and display it within the div container. var report = powerbi.embed(reportContainer, config);
To
// Get a reference to the embedded report HTML element var reportContainer = $('#embedContainer')[0]; // call load() instead of embed() to load the report while delaying the rendering process var report = powerbi.load(embedContainer, config); // when loaded event occurs, set current page then call render() report.on("loaded", function () { // console.log("loaded event executing"); // call to get Pages collection report.getPages().then( function (pages) { // inspect pages in browser console //console.log(pages); // display specific page in report var startPage = pages[@ViewBag.ReportPage]; config.pageName = startPage.name; // Call report.render() to display report report.render(config); }); });
Now you can set the report page in the URL. Use ReportPage=<page_number_starting_from_0> as the parameter: For example “EmbedReport?ReportPage=1” would take you to the second page.
Further customization:
Embed container size and other style related: Content/style/style.css
It is possible to require users to authenticate to your Azure AD: this option is called “users’ own data” and the template is found from the same GitHub repo as our app own data example.
Publishing a new report
Now that we have a working template, publishing a new web app pointing to a new report is extremely fast and easy.
Get your new report’s report ID. Use the same workspace, or remember to add the service principal to the new Power BI workspace.
Create a new web application in Azure. It’s just copying in your Terraform: Update the reportId and workspaceId, add key vault access policy. Here we are creating a new web app called “Solita-blog-datapipeline-monitor”.
Copy our web application solution.
Open the new copy, and publish it to the new web app in Azure.
You now know what kind of environment you need to securely use Web App, Power BI Service and Power BI Embedded in Azure. You know how to do some modifications to your web app or at least where to look for more information. And after the first application, publishing a new one is just a simple matter of creating a new copy with two new parameter values.
After working with Power BI Embedded for a while I’ve grown to appreciate it’s capabilities. This was just about embedding a complete report from Power BI Service, and I’m looking forward to do some more complex work combining web applications with Power BI Embedded!
Introducing an approach to reroute web traffic through a virtual machine in the cloud. This was a personal competence development project for which Solita allows their employees to spend some working hours.
While I was on a business trip in Sweden I had some lazy time to watch a documentary from a video streaming service. Unfortunately the web service was available only in Finland, so I had to come up with other ways to spend my evening. The obvious choice was to try whether it would be theoretically possible to hack my location to watch such programs abroad.
To stay on the brighter side of the law, I decided to only validate approach in the conceptual level. I never tried the hack in the actual service, and you should neither.
And yes, there are tons of software products to make this easier. Rather, my goal was to learn new skills and sharpen my developer competence. The focus was more in the functionality rather than in the cyber security.
Disclaimer. Use this article on for legally valid business purposes such as rerouting traffic in your own web service. Always read the rules of the web services that you are using.
Choosing the cloud provider for the proxy server
I needed a virtual server located physically in Finland. Initially I planned to use Google Cloud virtual machines as Google has a data center in Finnish soil. Microsoft Azure and Amazon Web Services do not have data centers in Finland.
Well, the first attempt failed quickly, because Google Cloud did not assign the IP address of the proxy server to Finland. So I switched the focus on creating a general purpose http proxy server on AWS to fake the location for web services.
Next comes the instructions to replicate my approach. The examples are primarily for Windows users.
Creating a virtual server to AWS for http proxy
Create an AWS account if you don’t have one. Login to AWS console from the browser.
From services select EC2. Select the preferred region from the top right corner. I usually choose Ireland because it has one of the the most comprehensive service selections in Europe. By this choice the traffic would be rerouted through Ireland.
Click Launch instance.
Select Ubuntu 18.04 LTS as the image for the EC2 instance.
Click next until you are prompted to create an SSH key. Name the key as you wish, download it and launch the instance.
Go back to EC2 instance view and note the IP address. In my case it was 18.203.111.131. It is safe to publish the info here, as the virtual machine is already destroyed.
Connect to AWS EC2 instance and create a tunnel
You need to have PuTTY Key Generator and PuTTY installed. The key file was downloaded in pem format from AWS. Convert the pem file to ppk using PuTTY Key Generator. Load the pem file and click Save private key.
Normally you would never want to show the private key to anyone. The key and the EC2 instance for this tutorial have already been destroyed.
Go to PuTTY and give the username and IP address of the remote machine for PuTTY. For AWS EC2 Ubuntu instance the default user is ubuntu.
Go to Connection > SSH > Auth and browse the ppk file that you just saved.
Create a tunnel that will route all traffic in your local machine port 8080 to port 3128 of the remote EC2 Ubuntu instance. 3128 is the default port for the squid proxy tool in Linux that we will install soon.
Click Open from the bottom of PuTTY. The terminal window appears.
Install squid in the virtual machine to make it an http proxy server
Install squid to the remote Ubuntu machine.
sudo apt update
sudo apt install squid
Find the line from the squid configuration file where the http access has been denied by default.
Simultaneously press CTRL and – to enter the line number to find the correct line.
Change the value to:
http_access allow localhost
Press CTRL and x to save. Choose y to confirm. Hit Enter to overwrite.
Finally restart the squid service.
sudo service squid restart
The proxy server is now successfully configured.
Configure Google Chrome browser for http proxy
Go to Google Chrome settings in your laptop. Find the settings having keyword proxy.
Click Open proxy settings. The browser opens Windows settings for the Internet Properties. Click LAN settings.
Route all traffic through your local machine’s (127.0.0.1) port 8080. That port again was tunneled to AWS EC2 port 3128 where the squid proxy server is running on top of the Ubuntu operating system.
Click Ok to see the magic happening.
Checking if the http proxy server works in the browser
I went to a page which detects the client’s IP address and shows the geographical location. The web service thinks I’m in Ireland where the AWS data center is located.
Once I switch off the browser proxy from Chrome/Windows my IP address points to my actual location. At the moment of writing I was in Gothenburg, Sweden.
PySpark looks like regular python code. In reality the distributed nature of the execution requires the whole new way of thinking to optimize the PySpark code.
Here comes the first source of potential confusion: despite their similar names, PySpark DataFrames and pandas DataFrames behave very differently. It is also easy to confuse them in your code. You might want to use suffix like _pDF for pandas DataFrames and _sDF for Spark DataFrames.
The pandas DataFrame object stores all the data represented by the data frame within the memory space of the Python interpreter. All of the data is easily and immediately accessible. The operations on the data are executed immediately when the code is executed, line by line. It is easy to print intermediate results to debug the code.
However, these advantages are offset by the fact that you are limited by the local computer’s memory and processing power constraints – you can only handle data which fits into the local memory. But since the operations are done in memory, with a basic data processing task you do not need to wait more than a few minutes at maximum.
PySpark DataFrames and their execution logic
The PySpark DataFrame object is an interface to Spark’s DataFrame API and a Spark DataFrame within a Spark application. The data in the DataFrame is very likely to be somewhere else than the computer running the Python interpreter – e.g. on a remote Spark cluster running in the cloud.
There are two distinct kinds of operations on Spark DataFrames: transformations and actions. Transformations describe operations on the data, e.g. filtering a column by value, joining two DataFrames by key columns, or sorting data. Actions are operations which take DataFrame(s) as input and output something else. Some examples from action would be showing the contents of a DataFrame or writing a DataFrame to a file system.
The key point to understand how Spark works is that transformations are lazy. Executing a Python command which describes a transformation of a PySpark DataFrame to another does not actually require calculations to take place. Ordering by a column and calculating aggregate values, returning another PySpark DataFrame would be such transformation. Rather, the operation is added to the graph describing what Spark should eventually do.
When an action is requested – e.g. return the contents of this Spark DataFrame as a Pandas DataFrame – Spark looks at the processing graph and then optimizes the tasks which needs to be done. This is the job of the Catalyst optimizer, and it enables Spark to optimize the operations to very high degree.
Also, the actual computation tasks run on the Spark cluster, meaning that you can have huge amounts of memory and processing cores available for the actual computation, even without resorting to the top-of-the-line virtual machines offered by cloud providers.
Consider caching to speed up PySpark
However, the highly optimized and parallelized execution comes at a cost: it is not as easy to see what is going on at each step. Looking at the data after some transformations means that you have to gather the data, or its subset, to a single computer. This is an action, so Spark has to determine the computation graph, optimize it, and execute it.
If your dataset is large, this may take quite some time. This is especially true if caching is not enabled and Spark has to start by reading the input data from a remote source – such as a database cluster or cloud object storage like S3.
You can alleviate this by caching the DataFrame at some suitable point. Caching causes the DataFrame partitions to be retained on the executors and not be removed from memory or disk unless there is a pressing need. In practice this means that the cached version of the DataFrame is available quickly for further calculations. However, playing around with the data is still not as easy or quick as with pandas DataFrames.
Use small scripts and multiple environments in PySpark
As a rule of thumb, one PySpark script should perform just one well defined task. This is due to the fact that any action triggers the transformation plan execution from the beginning. Managing and debugging becomes a pain if the code has lots of actions.
The normal flow is to read the data, transform the data and write the data. Often the write stage is the only place where you need to execute an action. Instead of debugging in the middle of the code, you can review the output of the whole PySpark job.
With large amounts of data this approach would be slow. You would have to wait a long time to see the results after each job.
My suggestion is to create environments that have different sizes of data. In the environment with little data you test the business logic and syntax. The test cycle is rapid as there’s no need process gigabytes of data. Running the PySpark script with the full dataset reveals the performance problems.
This goes well together with the traditional dev, test, prod environment split.
Favor DataFrame over RDD with structured data
RDD (Resilient Distributed Dataset) can be any set of items. For example, a shopping list.
["apple", "milk", "bread"]
RDD is the low-level data representation in Spark, and in earlier versions of Spark it was also the only way to access and manipulate data. However, the DataFrame API was introduced as an abstraction on top of the RDD API. As a rule of thumb, unless you are doing something very involved (and you really know what you are doing!), stick with the DataFrame API.
DataFrame is a tabular structure: a collection of Columns, each of which has a well defined data type. If you have a description and amount for each item in the shopping list, then a DataFrame would do better.
This is also a very intuitive representation for structured data, something that can be found from a database table. PySpark DataFrames have their own methods for data manipulation just like pandas DataFrames have.
Avoid User Defined Functions in PySpark
As a beginner I thought PySpark DataFrames would integrate seamlessly to Python. That’s why I chose to use UDFs (User Defined Functions) to transform the data.
A UDF is simply a Python function which has been registered to Spark using PySpark’s spark.udf.register method.
With the small sample dataset it was relatively easy to get started with UDF functions. When running the PySpark script with more data, spark popped an OutOfMemory error.
Investigating the issue revealed that the code could not be optimized when using UDFs. To Spark’s Catalyst optimizer, the UDF is a black box. This means that Spark may have to read in all of the input data, even though the data actually used by the UDF comes from a small fragments in the input I.e. doing data filtering at the data read step near the data, i.e. predicate pushdown, cannot be used.
Additionally, there is a performance penalty: on the Spark executors, where the actual computations take place, data has to be converted (serialized) in the Spark JVM to a format Python can read, a Python interpreter spun up, the data deserialized in the Python interpreter, the UDF executed, and the result serialized and deserialized again to the Spark JVM. All of this takes significant amounts of time!
The recommendation is to stay in native PySpark dataframe functions whenever possible, since they are translated directly to native Scala functions running on Spark.
If you absolutely, positively need to do something with UDFs in PySpark, consider using the pandas vectorized UDFs introduced in Spark 2.3 – the UDFs are still a black box to the optimizer, but at least the performance penalty of moving data between JVM and Python interpreter is lot smaller.
Number of partitions and partition size in PySpark
In order to process data in a parallel fashion on multiple compute nodes, Spark splits data into partitions, smaller data chunks. A DataFrame of 1,000,000 rows could be partitioned to 10 partitions having 100,000 rows each. Additionally, the computation jobs Spark runs are split into tasks, each task acting on a single data partition. Spark cluster has a driver that distributes the tasks to multiple executors. This means that the datasets can be much larger than fits into the memory of a single computer – as long as the partitions fit into the memory of the computers running the executors.
In one of the projects our team encountered an out-of-memory error that we spent a long time figuring out. Finally we found out that the problem was a result of too large partitions. The data in a partition could simply not fit to the memory of a single executor node.
Too few partitions also make the execution inefficient. Some of the executor cores idle while others are working on a full steam, if there are not as many partitions as there are available cores (or, technically, available slots)
However, having a large amount of small partitions is not optimal either – shuffling the data in the small partitions is inefficient. Also reading and writing to disk (not to mention a network destination) in small chunks potentially increases the total execution time.
The Spark programming guiderecommends 128 MB partition size as the default. For 128 GB of data this would mean 1000 partitions. Without going too deep in the details, consider partitioning as a crucial part of the optimization toolbox. If your partitions are too large or too small, you can use the coalesce() and repartition() methods of DataFrame to instruct Spark to modify the partition distribution. The number of partitions in a DataFrame sDF can be checked with sDF.rdd.getNumPartitions().
Summary – PySpark basics and optimization
PySpark offers a versatile interface for using powerful Spark clusters, but it requires a completely different way of thinking and being aware of the differences of local and distributed execution models. The functionality offered by the core PySpark interface can be extended by creating User-Defined Functions (UDFs), but as a tradeoff the performance is not as good as for native PySpark functions due to lesser degree of optimization. Partitioning the data correctly and with a reasonable partition size is crucial for efficient execution – and as always, good planning is the key to success.
In this blog post, I'll demonstrate how you can create a Power BI report to visualize monthly Snowflake virtual warehouse costs in euros and make Snowflake costs visible even for those not having access to Snowflake console.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
At the core of Snowflake are the virtual warehouses which enable unlimited scalability for computing. Data load, integration and visualization tools can have their own virtual warehouses. You can even provide a dedicated virtual warehouse for a business analyst who wants to query the raw data by himself.
You although want to ensure that Snowflake costs won’t skyrocket due to misuse of computational power what Snowflake provides so easily and the easiest way to do this is to visualize the virtual warehouse credit costs in Power BI (or similar tool) using Snowflake’s internal data dictionary and share the dashboard for relevant parties not having access to Snowflake console.
If you open any Snowflake database, you see that Snowflake databases come with INFORMATION_SCHEMA-schema included. INFORMATION_SCHEMA is Snowflake’s own data dictionary of all the stuff which are inside the database.
LOAD_HISTORY-view, for example, contains information of all files which are loaded into Snowflake. Do you want to know who has logged into Snowflake recently and what queries he or she has done? Just visit LOGIN_HISTORYand QUERY_HISTORY-views. Insides of INFORMATION_SCHEMA have been illustrated greatly in Kent Graziano’s “Using Snowflake Information Schema” so I won’t go more into details.
Our use case is to visualize the credit cost of virtual warehouses in Euros and for this, we will need:
1) Snowflake user who has access either to ACCOUNT_USAGE -schema or desired INFORMATION_SCHEMA’s.
2) PowerBI or similar BI -tool to visualize the warehouse credit usage
Finding correct schema and values which we need.
As we want to visualize credit usage of warehouses, we want to use WAREHOUSE_METERING_HISTORY-view. The view is located at two places, inside ACCOUNT_USAGE -schema and INFORMATION_SCHEMA inside every database (as information of historical and current usage of data are shared inside the account inside every INFORMATION_SCHEMA). This time we’re going to use ACCOUNT_USAGE -schema. The values which interest us are START_TIME, WAREHOUSE_NAME and CREDITS_USED.
Creating Power BI data sources
Power BI supports Snowflake, but before you can access Snowflake data, you need to download Snowflake ODBC -driver. Once you have the setup running, create a new data source using the “Get Data” -button. In my case, I have chosen “DV_WAREHOUSE_METERING_HISTORY_S” -table which is same as the WAREHOUSE_METERING_HISTORY -table, but is loaded weekly to provide historical data beyond one year.
The cost of warehouses are stored inside WAREHOUSE_METERING_HISTORY -table in CREDITS_USED column, but the Snowflake credits need to be converted into dollars and euro’s and grouped accordingly.
Add two new columns to the data set. Use the Modeling -tab and the “New Column” -button. Name first column as Dollar and one more column “Dollar” to the data and give it current value for dollar in euros. Currently one dollar is valued at 0,89 euros, so will give that value. In the future we can modify this value to be updated constantly, but for getting a best estimate for costs, a fixed value works fine.
Remember to give enough decimals for column so that Power BI won’t round up the value into one.
Create second column and give it name “Euro”. For this column, use following calculation. This calculation will count the sum the used credits and multiply the with the value of dollar. Outcome is the used credits in euros.
1 EURO = CALCULATE(SUM([CREDITS_USED])*CALCULATE(SUM(DV_WAREHOUSE_METERING_HISTORY_S[Dollar])))
Creating Power BI report
Once you have data sources ready, doing the final report is really easy. Add START_TIME (on month level) to AXIS, WAREHOUSE_NAME to LEGEND and finally EURO as value.
For this visualization, I have chosen a clustered column chart. You can add SUM of EURO to the dashboard to give it a final touch. I have also added a note that this does not include storage costs. The final result should look something like below.
Hopefully this short guidance will help you to visualize your Snowflake costs and ease the task of proofing that Snowflake is really cheap if you use it correctly.
This AWS Glue tutorial is a hands-on introduction to create a data transformation script with Spark and Python. Basic Glue concepts such as database, table, crawler and job will be introduced.
Glue can read data either from database or S3 bucket. For this tutorial I created an S3 bucket called glue-blog-tutorial-bucket. You have to come up with another name on your AWS account.
Create two folders from S3 console called read and write.
The S3 bucket has two folders. In AWS a folder is actually just a prefix for the file name.
The data for this Python and Spark tutorial in Glue contains just 10 rows of data. Source: IMDB.
Crawl the data source to the data catalog
Glue has a concept of crawler. A crawler sniffs metadata from the data source such as file format, column names, column data types and row count. The metadata makes it easy for others to find the needed datasets. The Glue catalog enables easy access to the data sources from the data transformation scripts.
The crawler will catalog all files in the specified S3 bucket and prefix. All the files should have the same schema.
In Glue crawler terminology the file format is known as a classifier. The crawler identifies the most common classifiers automatically including CSV, json and parquet. It would be possible to create a custom classifiers where the schema is defined in grok patterns which are close relatives of regular expressions.
Our sample file is in the CSV format and will be recognized automatically.
Instructions to create a Glue crawler:
In the left panel of the Glue management console click Crawlers.
Click the blue Add crawler button.
Give the crawler a name such as glue-blog-tutorial-crawler.
In Add a data store menu choose S3 and select the bucket you created. Drill down to select the read folder.
In Choose an IAM role create new. Name the role to for example glue-blog-tutorial-iam-role.
In Configure the crawler’s output add a database called glue-blog-tutorial-db.
Summary of the AWS Glue crawler configuration.
When you are back in the list of all crawlers, tick the crawler that you created. Click Run crawler.
Note: If your CSV data needs to be quoted, read this.
The crawled metadata in Glue tables
Once the data has been crawled, the crawler creates a metadata table from it. You find the results from the Tables section of the Glue console. The database that you created during the crawler setup is just an arbitrary way of grouping the tables.
Metadata for the Glue table.
Glue tables don’t contain the data but only the instructions how to access the data.
Note: For large CSV datasets the row count seems to be just an estimation.
AWS Glue jobs for data transformations
From the Glue console left panel go to Jobs and click blue Add job button.
Follow these instructions to create the Glue job:
Name the job as glue-blog-tutorial-job.
Choose the same IAM role that you created for the crawler. It can read and write to the S3 bucket.
Type: Spark.
Glue version: Spark 2.4, Python 3.
This job runs: A new script to be authored by you.
Security configuration, script libraries, and job parameters
Maximum capacity: 2. This is the minimum and costs about 0.15$ per run.
Job timeout: 10. Prevents the job to run longer than expected.
Click Next and then Save job and edit the script.
Editing the Glue script to transform the data with Python and Spark
Copythis code from Github to the Glue script editor.
Remember to change the bucket name for the s3_write_path variable.
Save the code in the editor and click Run job.
The Glue editor to modify the python flavored Spark code.
The detailed explanations are commented in the code. Here is the high level description:
Read the movie data from S3
Get movie count and rating average for each decade
Write aggregated data back to S3
The execution time with 2 Data Processing Units (DPU) was around 40 seconds. Relatively long duration is explained by the start-up overhead.
The data transformation script creates summarized movie data. For example 1990 decade had 4 movies in the IMDB top 10 with the average score of 8.95.
You can download the result file from the write folder of your S3 bucket. Another way to investigate the job would be to take a look at the CloudWatch logs.
The data is stored back to S3 as a CSV in the “write” prefix. The number of partitions equals the number of the output files.
Speeding up Spark development with Glue dev endpoint
Developing Glue transformation scripts is slow, if you just run a job after another. Provisioning the computation cluster takes minutes and you don’t want to wait after each change.
Glue has a dev endpoint functionality where you launch a temporary environment that is constantly available. For development and testing it’s both faster and cheaper.
Dev endpoint provides the processing power, but a notebook server is needed to write your code. Easiest way to get started is to create a new SageMaker notebook by clicking Notebooks under the Dev endpoint in the left panel.
About Glue performance
In the code example we did read the data first to Glue’s DynamicFrame and then converted that to native PySpark DataFrame. This method makes it possible to take advantage of Glue catalog but at the same time use native PySpark functions.
However, our team has noticed Glue performance to be extremely poor when converting from DynamicFrame to DataFrame. This applies especially when you have one large file instead of multiple smaller ones. If the execution time and data reading becomes the bottleneck, consider using native PySpark read function to fetch the data from S3.
Summary about the Glue tutorial with Python and Spark
Getting started with Glue jobs can take some time with all the menus and options. Hopefully this tutorial gave some idea what is the role of database, table, job and crawler.
The focus of this tutorial was in a single script, but Glue also provides tools to manage larger group of jobs. You can schedule jobs with triggers or orchestrate relationships between triggers, jobs and crawlers with workflows.
Learning the Glue console is one thing, but the actual logic lies in the Spark scripts. Tuning the code impacts significantly to the execution performance. That will be the topic of the next blog post.
AWS Glue is a serverless ETL tool in cloud. In brief ETL means extracting data from a source system, transforming it for analysis and other applications and then loading back to data warehouse for example.
In this blog post I will introduce the basic idea behind AWS Glue and present potential use cases.
The emphasis is in the big data processing. You can read more about Glue catalogs here and data catalogs in general here.
Why to use AWS Glue?
Replacing Hadoop. Hadoop can be expensive and a pain to configure. AWS Glue is simple. Some say that Glue is expensive, but it depends where you compare. Because of on demand pricing you only pay for what you use. This fact might make AWS Glue significantly cheaper than a fixed size on-premise Hadoop cluster.
AWS Lambda can not be used. A wise man said, use lambda functions in AWS whenever possible. Lambdas are simple, scalable and cost efficient. They can also be triggered by events. For big data lambda functions are not suitable because of the 3 GB memory limitation and 15 minute timeout. AWS Glue is specifically built to process large datasets.
Apply DataOps practices. Drag and drop ETL tools are easy for users, but from the DataOps perspective code based development is a superior approach. With AWS Glue both code and configuration can be stored in version control. The data development becomes similar to any other software development. For example the data transformation scripts written by scala or python are not limited to AWS cloud. Environment setup is easy to automate and parameterize when the code is scripted.
An example use case for AWS Glue
Now a practical example about how AWS Glue would work in practice.
A production machine in a factory produces multiple data files daily. Each file is a size of 10 GB. The server in the factory pushes the files to AWS S3 once a day.
The factory data is needed to predict machine breakdowns. For that, the raw data should be pre-processed for the data science team.
Lambda is not an option for the pre-processing because of the memory and timeout limitation. Glue seems to be reasonable option when work hours and costs are compared to alternative tools.
The simplest way of get started with the ETL process is to create a new Glue job and write code to the editor. The script can be either in scala or python programming language.
Extract. The script first reads all the files from the specified S3 bucket to a single data frame. You can think a data frame as a table in Excel. The reading can be just a one-liner.
Transform. This is the most of the code. Let’s say that the original data had 100 records per second. The data science team wants the data to be aggregated per each 1 minute with a specific logic. This could be just tens of code lines if the logic is simple.
Load. Write data back to another S3 bucket for the data science team. It’s possible that a single line of code will do.
The code runs on top of the spark framework which is configured automatically in Glue. Thanks to spark, data will be divided to small chunks and processed in parallel on multiple machines simultaneously.
What makes AWS Glue serverless?
Serverless means you don’t have machines to configure. AWS provisions and allocates the resources automatically.
The processing power is adjusted by the number of data processing units (DPU). You can do additional configuration, but it’s likely that a proof of concept works out of the box.
In an on-premise environment you would have to make a decision about the computation cluster size. A big cluster is expensive but fast. A small cluster would be cheaper but slow to run.
With AWS Glue your bill is the result the following equation:
[ETL job price] = [Processing time] * [Number of DPUs]
The on demand pricing means that the increase in processing power does not compromise with the price of the ETL job. At least in theory, as too many DPUs might cause overhead in processing time.
When is AWS Glue a wrong choice?
This is not an advertisement, so let’s give some critique for Glue as well.
Lots of small ETL jobs. Glue has a minimum billing of 10 minutes and 2 DPUs. With the price of 0.44$ per DPU hour, the minimum cost for a run becomes around 0.15$. The starting price makes Glue unappealing alternative to process small amount of data often.
Specific networking requirements. If you spin up a standard EC2 virtual machine, an IP address will be attached to it. The serverless nature of Glue means you have to put more effort on network planning in some cases. One such scenario would be whitelisting a Glue job in a firewall to extract data from an external system.
Summary about AWS Glue
The most common argument against Glue is “It’s expensive”. True, in a sense that the first few test runs can already cost a few dollars. In a nutshell, Glue is cost efficient for infrequent big data workloads.
In the big picture AWS Glue saves a lot of time and unnecessary hardware engineering. The costs should be compared against alternative options such as on-premise Hadoop cluster or development hours required for a custom solution.
As Glue pricing model is predictable, the business cases are straightforward to calculate. It might be enough to test just the critical parts of the ETL pipeline to become confident about the performance and costs.
I feel that optimizing the code for distributed computing has been more of a challenge than the Glue service itself. The next blog post will focus on how data developers get started with Glue using python and spark.
Snowflake coming to Google Cloud, Data Replication, Snowflake Organizations, external tables, Data Pipelines, Data Exchange. The list goes on. Read following article for a curated list of new features released on Snowflake Summit keynote at San Francisco.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
Trying to go through for all the announcements for a product can be sometimes overwhelming. It takes time as you need to go through for all the individual press announcements. To ease the pain, I’ve gathered a curated list of new Snowflake features released at the first annual Snowflake Summit at sunny California at Hotel Hilton.
So let’s begin.
Snowflake released new features which can be broken down into to following categories: Core Data Warehouse, Data Pipelines, Global Snowflake and Secure Data Sharing. I’ll list the features and give a more precise description of the feature (if possible).
Core Data Warehouse
Core Data Warehouse features are the bread and butter of Snowflake. Everybody is already familiar with Snowflake features such as virtual warehouses, separation of storage and compute so Snowflake didn’t release any announcements on those. They though said that they are working on decreasing concurrency latency and making large ad-hoc queries to work even better. In larger scale this means that the boundaries of operational databases and operational data platforms are narrowing down.
On the security side, Snowflake told that they are working with multiple vendors on enabling identity passing from BI -tools to Snowflake. Basically this means that your user id which you use to log on to for example to Tableau, is passed straight to Snowflake. This will enable even better row-level security and secure views possibilities. As of today, Snowflake reminded, that Snowflake already supports OAuth 2.0 as an authentication method.
Under the hood, JavaScript Stored Procedures support was reminded and the possibility of Geospatial capability was spoken (nothing released, rather teased).
Guys and gals at Snowflake are also keen on providing a richer experience for the end users. They told that they had gathered information from the end users, to provide better worksheets, Worksheet 3.0 so to speak. The end result of that was that during the investigation phase they encountered company called Numeracy and eventually decided to make their first acquisition as Numeracy was working on creating even better UI for Snowflake. Now the features of Numeracy UI are being ported into Snowflake UI. Numecary UI provides better editor suggestions, visualizations and provides worksheet sharing. On text this doesn’t sound anything new, but my colleague took a video of the new UI and it is awesome.
Data Pipelines
Data Pipelines is a new feature coming into Snowflake. Basically Snowflake has now the capability to auto-ingest data coming into the cloud storage layer and the possibility to do a data transformation for the data based on user-defined tasks. This means that you no longer need any external scheduler to trigger the small ELT or scheduled jobs.
This is possible due to the following new features:
– Auto-Ingest
– Streams and Tasks
During the Data Pipelines presentation a Snowflake Connector for the Kafka was also announced.
Under the Data Pipelines headline, the concept of Snowflake as a Data Lake was introduced more in detail because Snowflake will now support external tables and SQL over external tables, which means that you don’t need to load the data into Snowflake to get the insight of the data (and data structure). To make things interesting, Snowflake will now also support materialized views on external tables.
As a surprise effect, all the features which were were listed above are available today in public preview.
Global Snowflake
Under the title of Global Snowflake the new regions were introduced. AWS got Canada Central, US-Central (Ohio) and Japan. For Azure, new regions will open in US-West-2, Canada Central, Government and Singapore.
The most anticipated release was the release of Google Cloud version of Snowflake, which will be on preview at Q3 at 2019. Google Cloud supported stages are though possible already, as noted earlier.
Snowflake Organizations was published as a new way to control your Snowflake instances within a large corporation. Now you have the possibility to deploy Snowflake instances in your chosen cloud and region through Snowflake UI and you can act as organization admin. Organizations will provide a dashboard of warehouse and storage costs of all your accounts. So, if your company has multiple Snowflake accounts, this the new way to go.
Finally, Database Replication was announced. Database replication offers the possibility to replicate your data, per database level, to another Snowflake account regardless whether the account is Azure, AWS or Google Cloud. It doesn’t even matter on which region you’re planning to replicate your data as database replication supports cross-region replications.
Database replication is a point-and-click version of the traditional Oracle Data Guard or Microsoft SQL Server AlwaysOn Cluster where you define database which you want to replicate to a different location for business continuity purposes or just to provide read-only data nearer to the end users. The difference to the Oracle and Microsoft versions is that Snowflake implementation works out-of-the-box without any hassle. Database replication also supports failover and failback for client application end user point, meaning that if you have Tableau Server connected to Snowflake and you do a failover the database, Tableau Server will reconnect to the new location.
Secure Data Sharing
On Secure Data Sharing field, Snowflake introduced their concept of a data marketplace, called Data Exchange. Basically, Data Exchange is a marketplace for data that can be used through Snowflake Data Sharing. You can buy data shares (for example consumer travel data, weather data etc.) through Data Exchange and use them straight away in your SQL queries.
There are two options for this, Standard and Personalized. Standard -data is your normal data set, available for everybody. Personalized -data requires authentication between you and the data provider, but it will grant you the possibility to ingest your own data (if possible) straight from the provider using Data Sharing -functionality.
If that’s not all, Snowflake even advertised in mid-sentence, a simpler way to deploy Tableau into AWS and configure it to use Snowflake, now in 30 minutes.
Hopefully, this list helps you to get a grasp on things to come on Snowflake landscape. I will update this list if new features will be launched tomorrow or Thursday.
In this following blog-post, I will tell you how to create asynchronous replication from Microsoft Active Directory to Snowflake Cloud Data Warehouse so you can use your existing AD users and groups (including nested groups) to manage Snowflake.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
I’ve been using Snowflake for a few years now and although Snowflake is an excellent product, it lacks the possibility to use existing directories (Microsoft Active Directory, OpenLDAP, Google) for managing Snowflake users and roles. It doesn’t though mean that it’s impossible.
As of today, you can already create federated authentication against Okta, ADFS, or another (i.e. custom) SAML 2.0-compliant Identity Provider (IdP) which enables users to do a single sign-on into Snowflake using their (for example) Azure Active Directory information. We’ll come back to this later on, as federated authentication is a key piece for using AD accounts with Snowflake.
In this following blog-post, I will tell you how to use and sync Microsoft Active Directory -users and groups into Snowflake and what components are needed for this. Let’s start by going through the needs.
You’ll need following for making the synchronization possible:
1) Rights to modify Snowflake account parameters and create new users
2) Microsoft Azure -subscription for enabling AzureAD Single Sign-On to Snowflake
3) Windows Server connected to Active Directory and snowsql installed
4) This script which sync’s users from AD. Huge thanks to James Weakley.
We will create following linking between Snowflake, Azure and Microsoft Active Directory.
Idea is to create a similar structure within Active Directory as you want to have inside Snowflake. Users and groups are provisioned and synced into Snowflake using Powershell -script running inside Window Server joined into AD. Single Sign-On authentication happens against AzureAD. So, let’s start configuring.
Enabling Single Sign-On
Steps can be created in any order, but you can start by enabling single sign-on as a first step. Having single sign-on enabled, you can already start using AD accounts as long as you create the needed accounts manually. Enabling single sign-on is already documented really well by Microsoft in the following site. https://docs.microsoft.com/en-us/azure/active-directory/saas-apps/snowflake-tutorial so I won’t go through all steps. Shortly, the idea is to configure AzureAD as IdP for Snowflake and eventually configure the same in Snowflake as detailed below.
USE ROLE ACCOUNTADMIN ;
ALTER ACCOUNT SET SAML_IDENTITY_PROVIDER = '{
"certificate": "longhash",
"ssoUrl": "https://login.microsoftonline.com/hashedtext/saml2",
"type" : "ADFS",
"label" : "AzureAD"
}';
Set the login page (this the page what you see, when you log on to Snowflake) to have new button what user’s can now to log using their Active Directory account.
ALTER ACCOUNT SET SSL_LOGIN_PAGE = TRUE ;
Finally alter any desired test users to have LOGIN_NAME similar as their AD account information. This will map do the actual mapping. You may also remove the users.
ALTER USER mika.heino@solita.fi SET LOGIN_NAME = 'mika.heino@solita.fi' DISPLAY_NAME = 'Mika Heino, Solita '
Creating Snowflake service account for script use
Once you have single sing-on working and tested, we can move to automating the user and group (role) provisioning. For this, we need a separate Snowflake service account as we don’t want to run stuff with personal accounts.
Creating roles and users in Snowflake requires SECURITYADMIN role. You can either create a service account with securityadmin granted, or you can create your own security admin role for service account with the required rights. Either way is ok, as long as it’s documented properly.
For example create following user: CREATE USER S_AUTOMATION_AD_SYNC PASSWORD = 'example_password' COMMENT = 'Service Account, Used to sync Active Directory users and roles' LOGIN_NAME = 'S_AUTOMATION_AD_SYNC' DEFAULT_ROLE = "SERVICE_ACCOUNTS_SECURITYADMIN" DEFAULT_WAREHOUSE = 'WH_ADE_DEV' DEFAULT_NAMESPACE = 'PUBLIC' MUST_CHANGE_PASSWORD = FALSE ;
GRANT ROLE "SERVICE_ACCOUNTS_SECURITYADMIN" TO USER S_AUTOMATION_AD_SYNC ;
GRANT ROLE "SECURITYADMIN" TO ROLE "SERVICE_ACCOUNTS_SECURITYADMIN";
Creating OU and Snowflake role structure
Choose or create a new Organizational Unit (OU) for Snowflake users. This will be the container for roles that you can use to grant rights inside Snowflake. Although this is the most straightforward phase in the whole process, use time to consider the roles (groups) to have and use. Consider at least the following structure:
1) Limited role for persons to have ACCOUNTADMIN -rights. Keep the number of people here a limited as this role can do anything inside Snowflake -account.
2) DV_ADMIN/DEVELOPER -role. Ideally, this role will have the rights to do anything inside one or more databases and meant for the persons creating the data models and loads i.e. in Solita the persons doing the Data Vault.
3) DATA SCIENTIST -role. Ideally, this role would have the rights to read anything from all the schemas inside the database having all the business data and rights to create anything inside separate development -database.
4) ANALYST -role. This role is meant for the business users and should have read rights to Publish -schema or ideally only to dimension and facts tables having business rules applied.
Same structure inside Active Directory.
Once you have the general structure ready, create it inside Active Directory, note the OU -structure and move to next step.
Scheduling the script
Scheduling the PowerShell – script is really straight forward. You use can the trusted Task Scheduler (ideally this would be running for example inside Azure Function, but this is the first version) for scheduling. You need to have a Windows Server joined into Active Directory, snowsql -installed and necessary firewall openings done. You’ll need to provide a few details for the script. Following is an example of the details for the script.
The script will retrieve all security groups and all the users from the OU you define, check whether they exist in Snowflake and create any missing users without any password to enforce AD authentication. For each security group immediately within the OU, a role in Snowflake is matched or created and all Snowflake users are granted it. The process goes also the other way, as users who have subsequently been removed from the AD group will be revoked from the corresponding role. Detailed documentation can be found in the GitHub -projects README -file.
Following is an example from script and it will create missing roles and grant roles to correct persons. In this example script you can also see a user being removed. In Snowflake the user removal is disable and revoke of his/hers roles, but no user account deletion.
As you can see from the script, you can map the role names using prefixes so that AD role snowflake-role-ADMIN is mapped to ADROLE_ADMIN. This will also help you on creating the roles in Active Directory, as you can use the existing company naming standards.
** Retrieving list of current snowflake users
Total current Snowflake SSO users: 30
**Retrieving AD security groups in OU OU=Snowflake,OU=Solutions,DC=FI,DC=Solita,DC=int
. AD Group : snowflake-role-ADMIN
. Snowflake Role : ADROLE_ADMIN
Fetching users immediately in group whose accounts aren't disabled
Fetching users nested in non-snowflake groups under group , whose accounts aren't disabled
Fetching nested role group
. AD Group : snowflake-role-DEVELOPER
. Snowflake Role : ADROLE_DEVELOPER
Fetching users immediately in group whose accounts aren't disabled
Fetching users nested in non-snowflake groups under group , whose accounts aren't disabled
Fetching nested role group
. AD Group : snowflake-role-Scientist
. Snowflake Role : ADROLE_SCIENTIST
Fetching users immediately in group whose accounts aren't disabled
Fetching users nested in non-snowflake groups under group , whose accounts aren't disabled
Fetching nested role group
. AD Group : snowflake-role-Analyst
. Snowflake Role : ADROLE_ANALYST
Fetching users immediately in group whose accounts aren't disabled
Fetching users nested in non-snowflake groups under group , whose accounts aren't disabled
Fetching nested role group
Disabling 1 users as they have no roles mapped in AD
**Retrieving list of current snowflake roles
Checking membership of current roles
Checking role ADROLE_ADMIN exists in Snowflake
Role does not exist, creating
Checking role ADROLE_DEVELOPER exists in Snowflake
Checking role ADROLE_SCIENTIST exists in Snowflake
Checking role ADROLE_ANALYST exists in Snowflake
Role does not exist, creating
. Checking role ADROLE_ADMIN has the appropriate users
missing grantees: Mika.Heino@solita.fi
superfluous grantees:
. Checking role ADROLE_DEVELOPER has the appropriate users
missing grantees:
superfluous grantees:
. Checking role ADROLE_SCIENTIST has the appropriate users
missing grantees:
superfluous grantees:
. Checking role ADROLE_ANALYST has the appropriate users
missing grantees: pappa@solita.fi seppo@solita.fi
superfluous grantees:
. Checking role ADROLE_ADMIN has the appropriate roles
missing grantees:
superfluous grantees:
. Checking role ADROLE_DEVELOPER has the appropriate roles
missing grantees:
superfluous grantees:
. Checking role ADROLE_SCIENTIST has the appropriate roles
missing grantees:
superfluous grantees:
. Checking role ADROLE_ANALYST has the appropriate roles
missing grantees:
superfluous grantees:
Without the -WhatIf flag, the script will execute the following SQL Statement:
BEGIN TRANSACTION;
ALTER USER \"teppo@solita.fi\" SET DISABLED=TRUE;
CREATE ROLE \"ADROLE_ADMIN\";
CREATE ROLE \"ADROLE_ANALYST\";
GRANT ROLE \"ADROLE_ADMIN\" TO USER \"mika.heino@solita.fi\";
GRANT ROLE \"ADROLE_ANALYST\" TO USER \"pappa@solita.fi\";
GRANT ROLE \"ADROLE_ANALYST\" TO USER \"seppo@solita.fi\";
REVOKE ROLE \"ADROLE_ANALYST\" FROM USER \"teppo@solita.fi\";
COMMIT;
Final words
I encourage you to test this script a couple of times before leaving it to run by itself. I also want to highlight that all though I’ve been using the script in production for a while, it comes without any support at all and it is a community-developed script, not an official Snowflake offering.
Also I recommend that you leave few Snowflake accounts with ACCOUNTADMIN rights as using AD accounts do not have any password and you might get yourself locked out in situations where SSO -authentication does not work. Keep in my though, that in general practice you should not have large amounts of users with ACCOUNTADMIN -rights as those accounts have highest rights on Snowflake.

 In February 2021, Tableau announced that they will remove minimum user amount restrictions from their licensing. For example, earlier the Viewer license had a minimum sales volume of 100 users. The change has enabled Tableau to be deployed at very low cost and with exactly the number of users needed for each organisation.
In February 2021, Tableau announced that they will remove minimum user amount restrictions from their licensing. For example, earlier the Viewer license had a minimum sales volume of 100 users. The change has enabled Tableau to be deployed at very low cost and with exactly the number of users needed for each organisation.


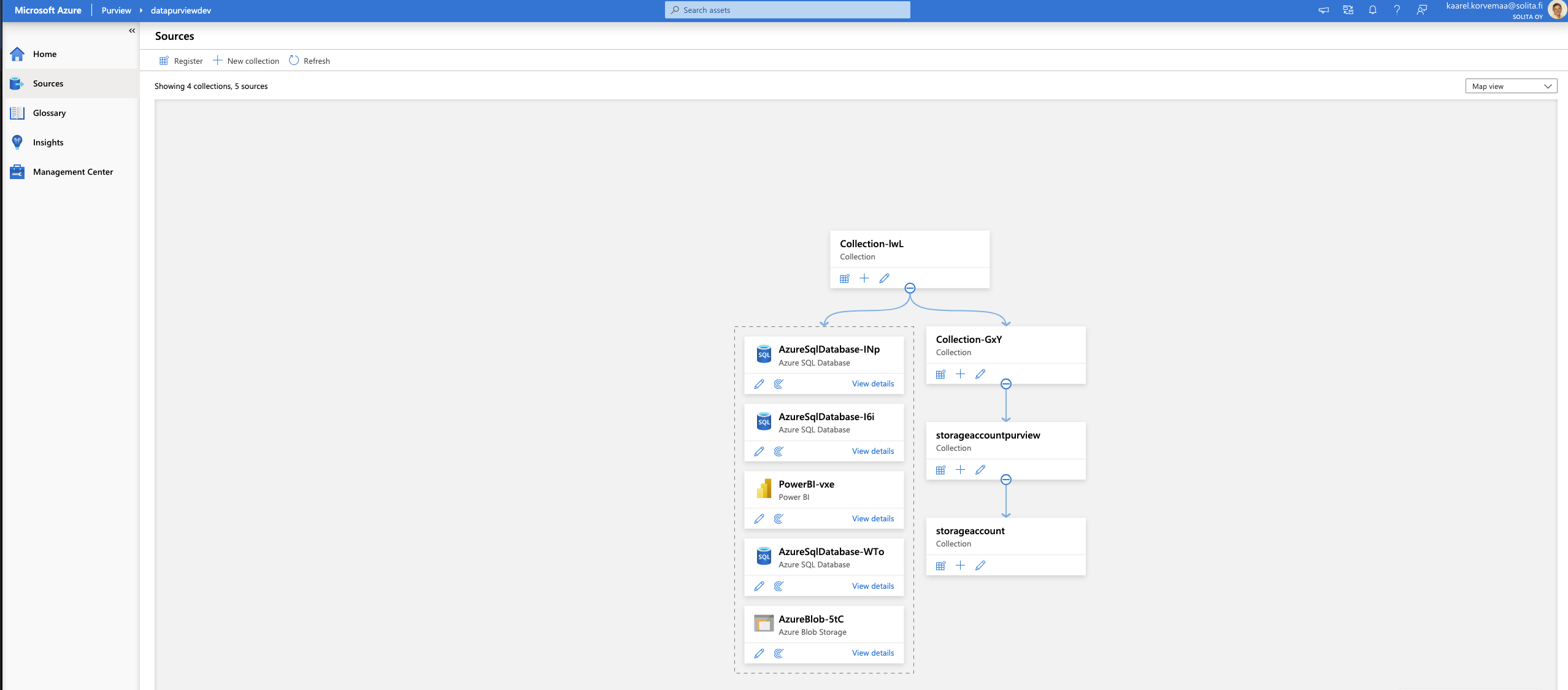

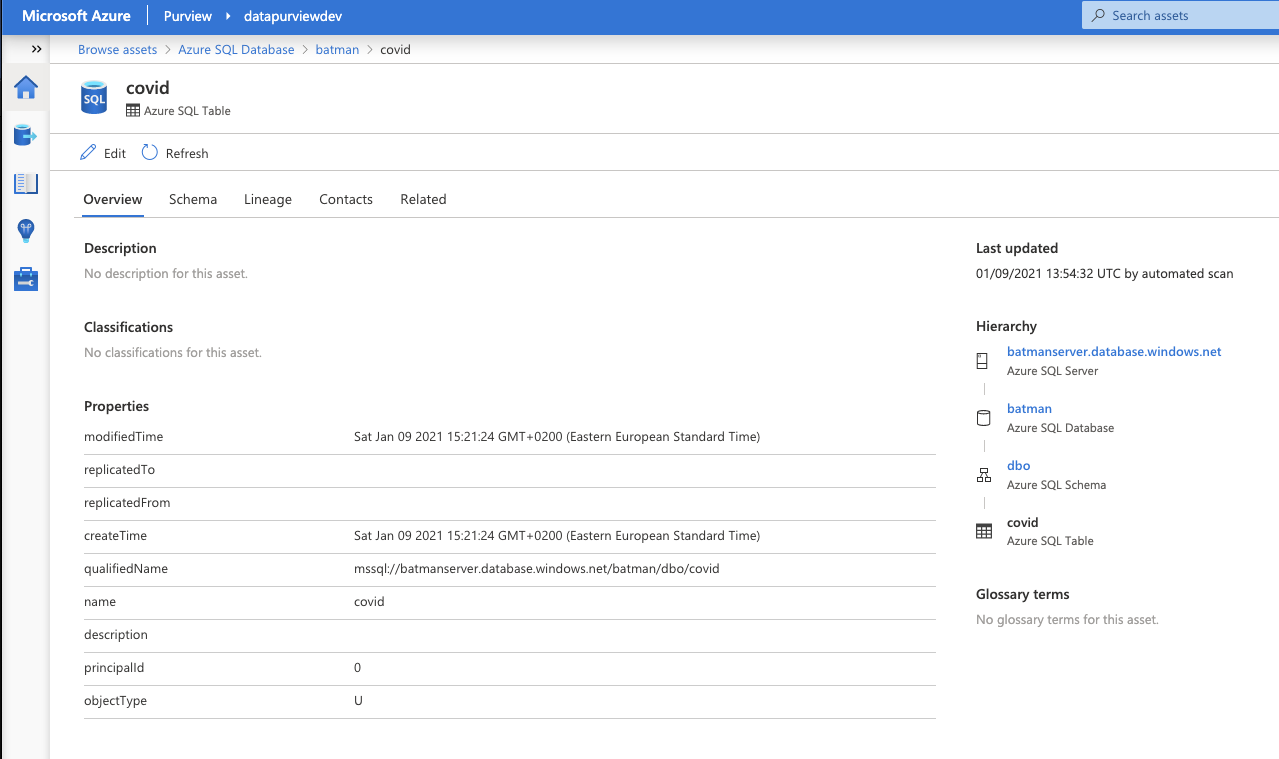
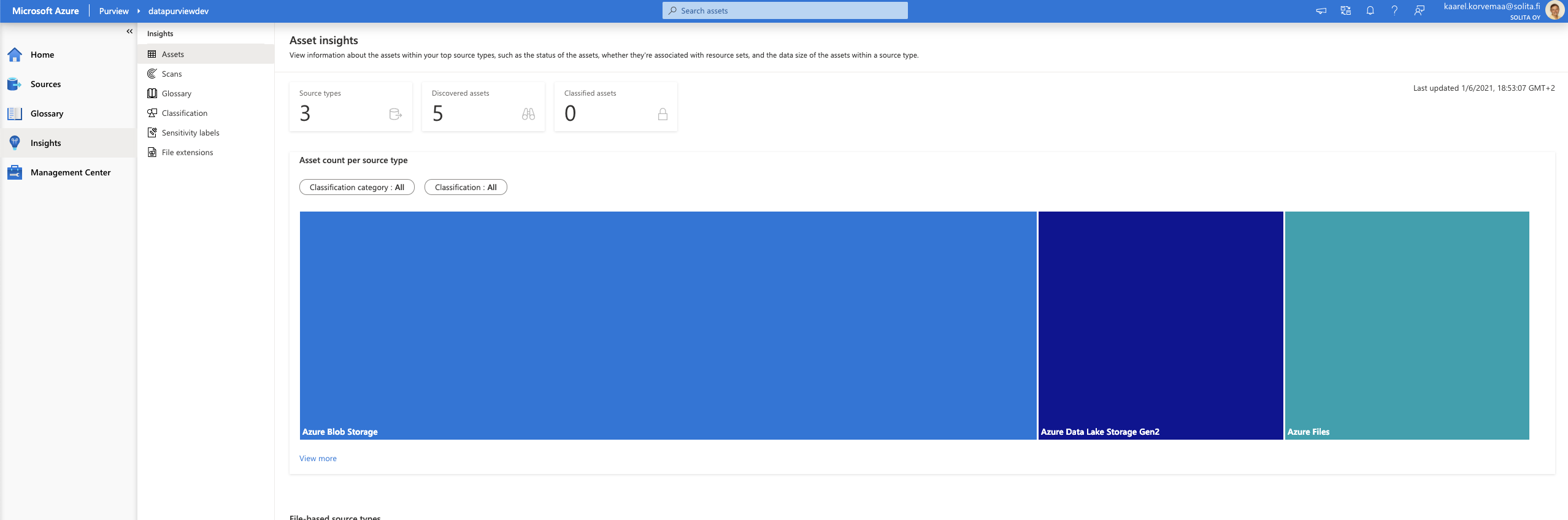





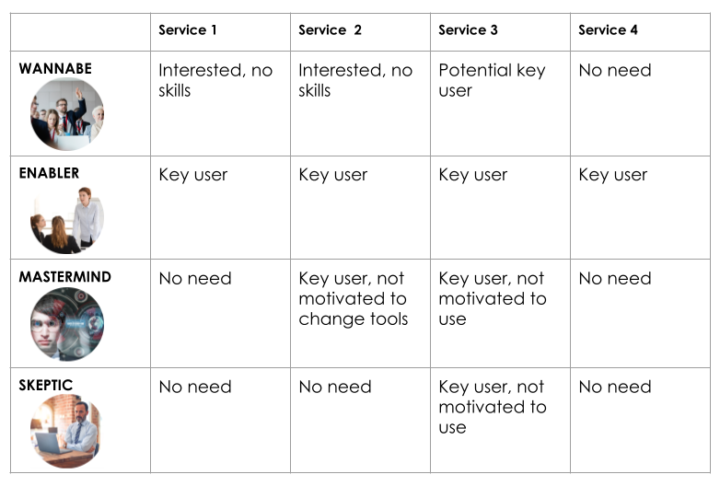


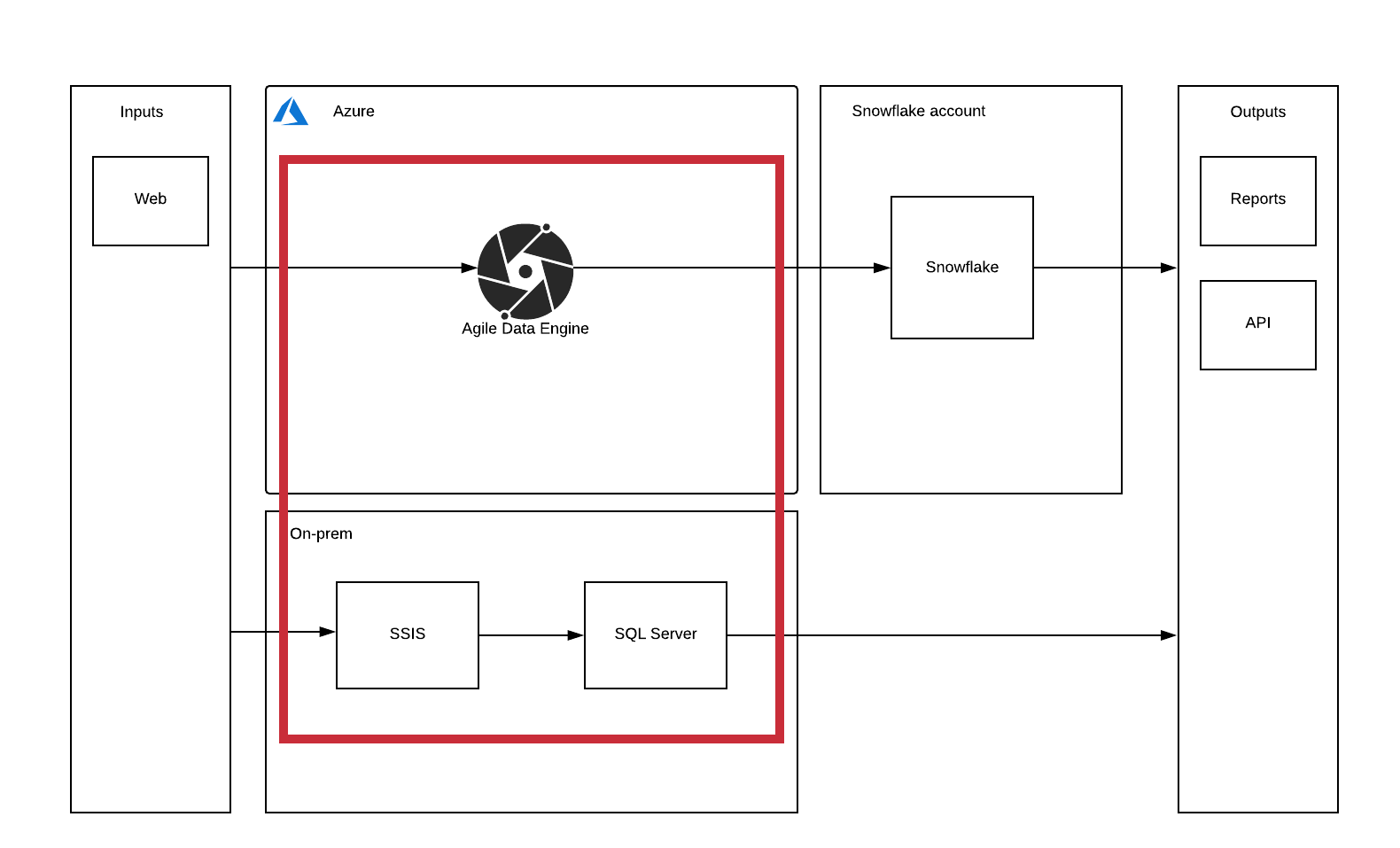
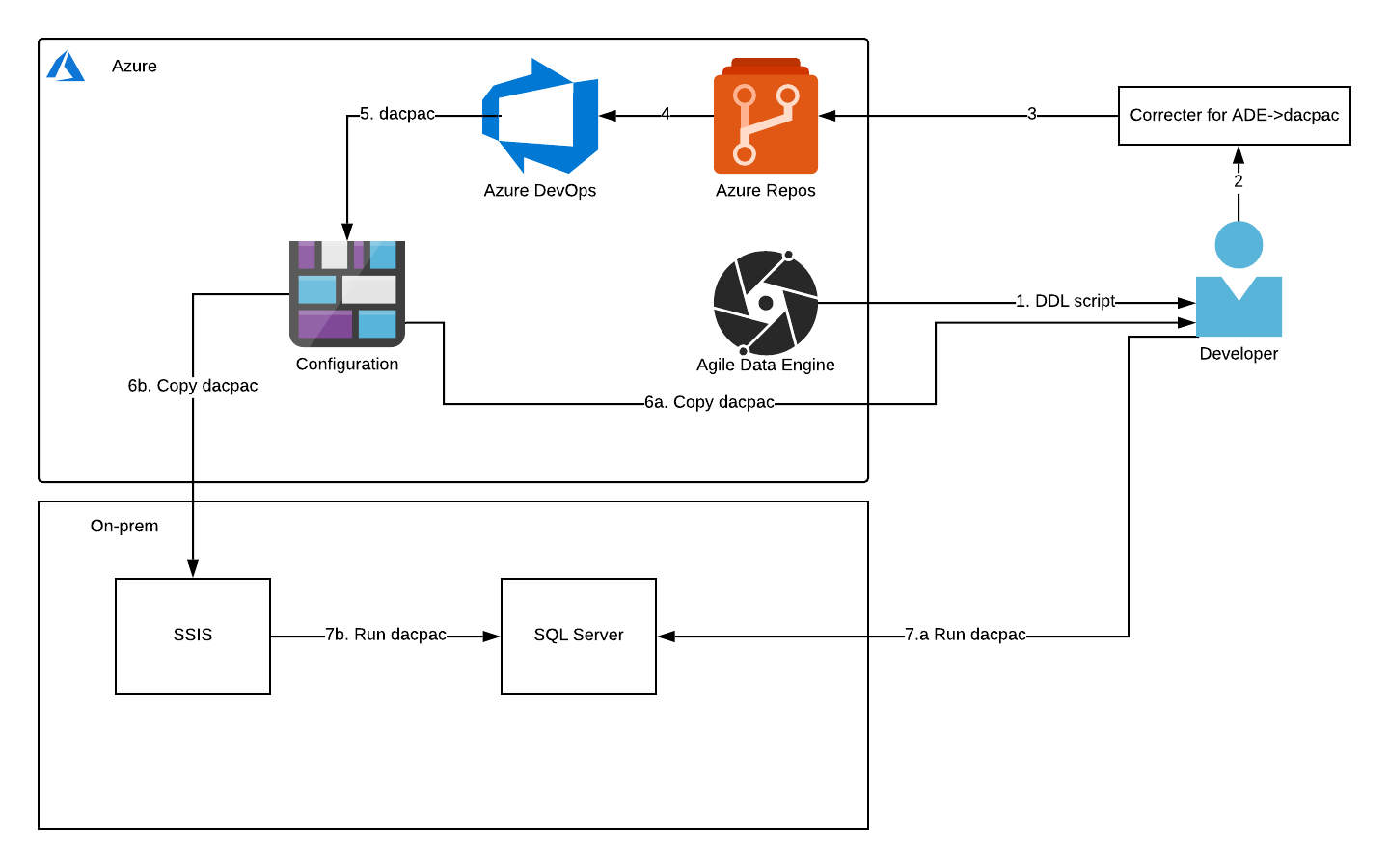


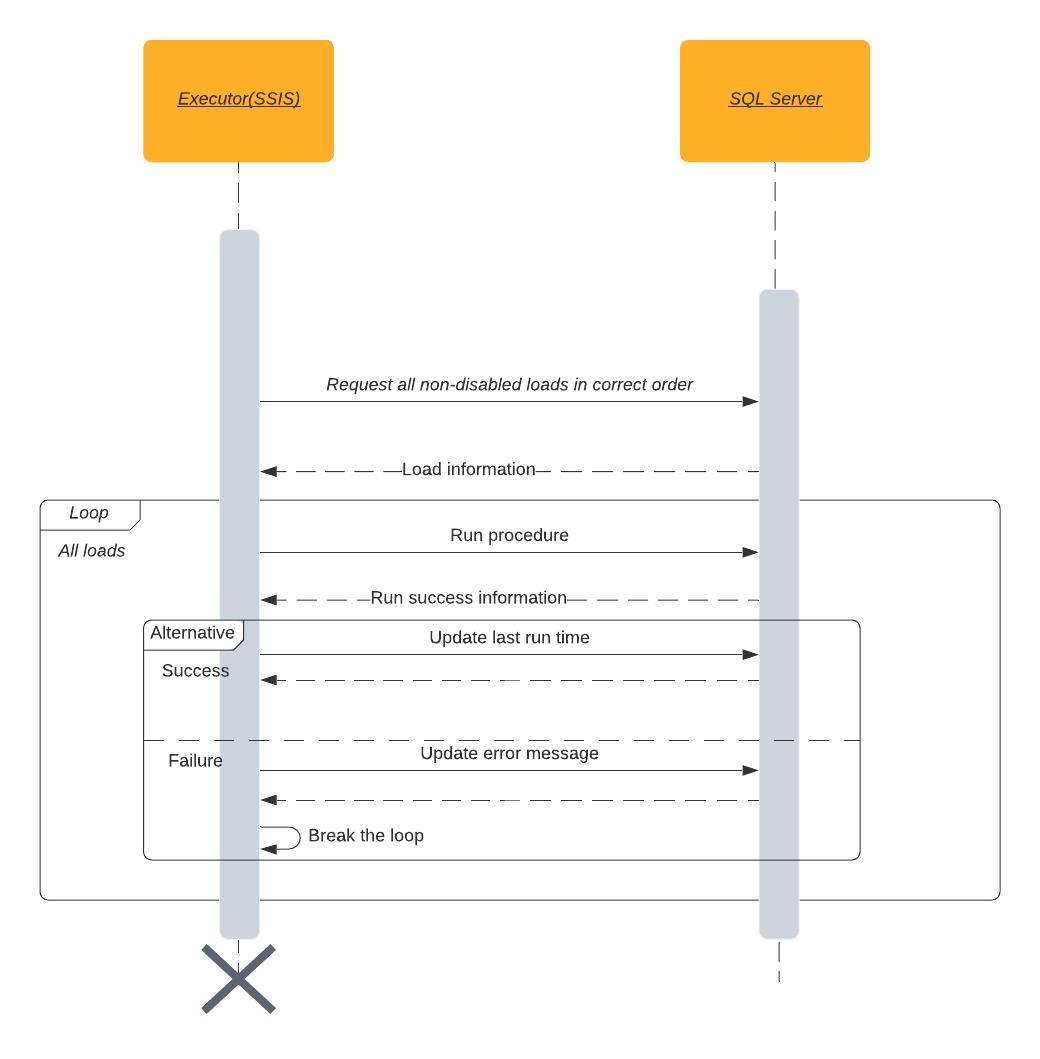












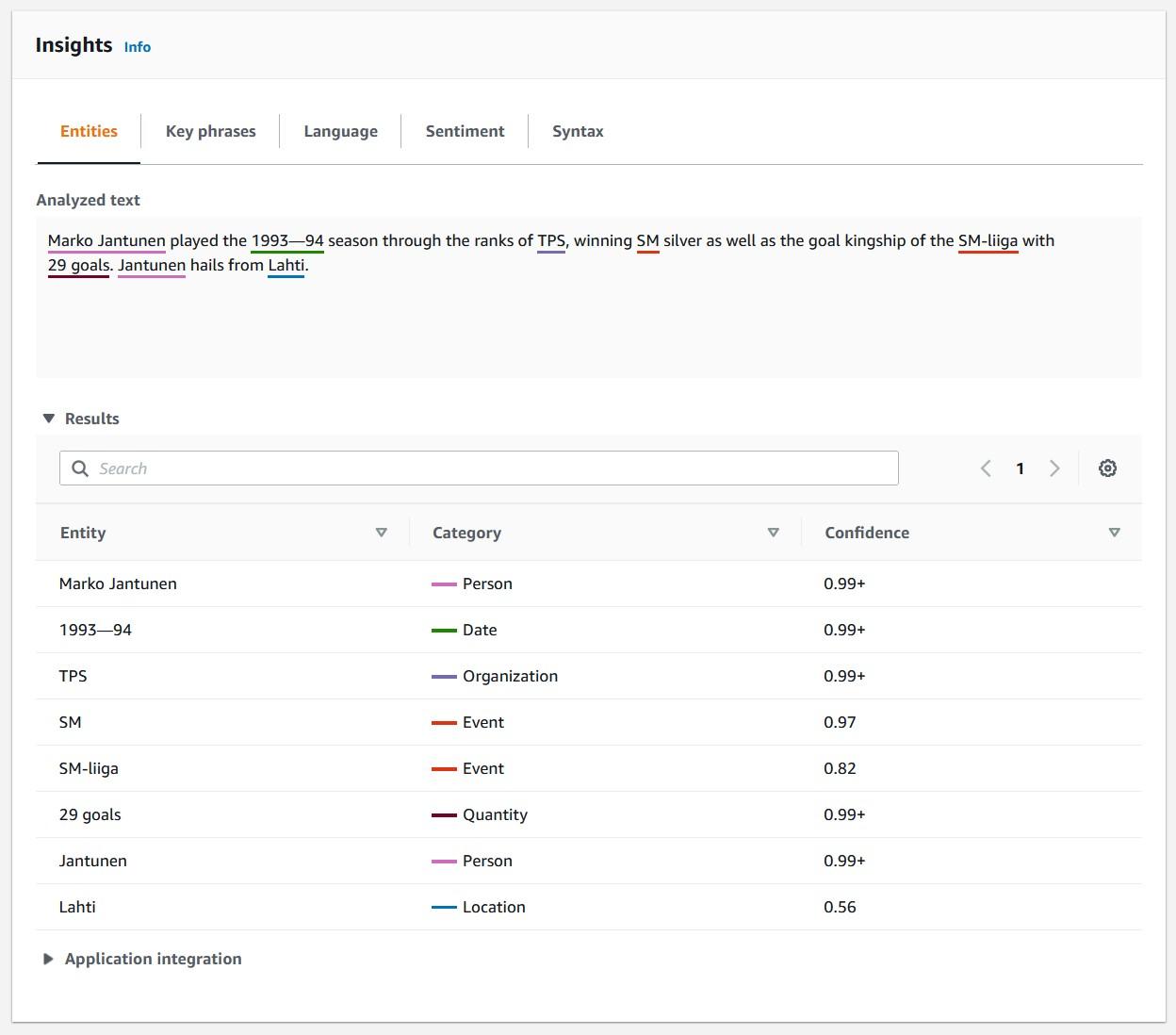

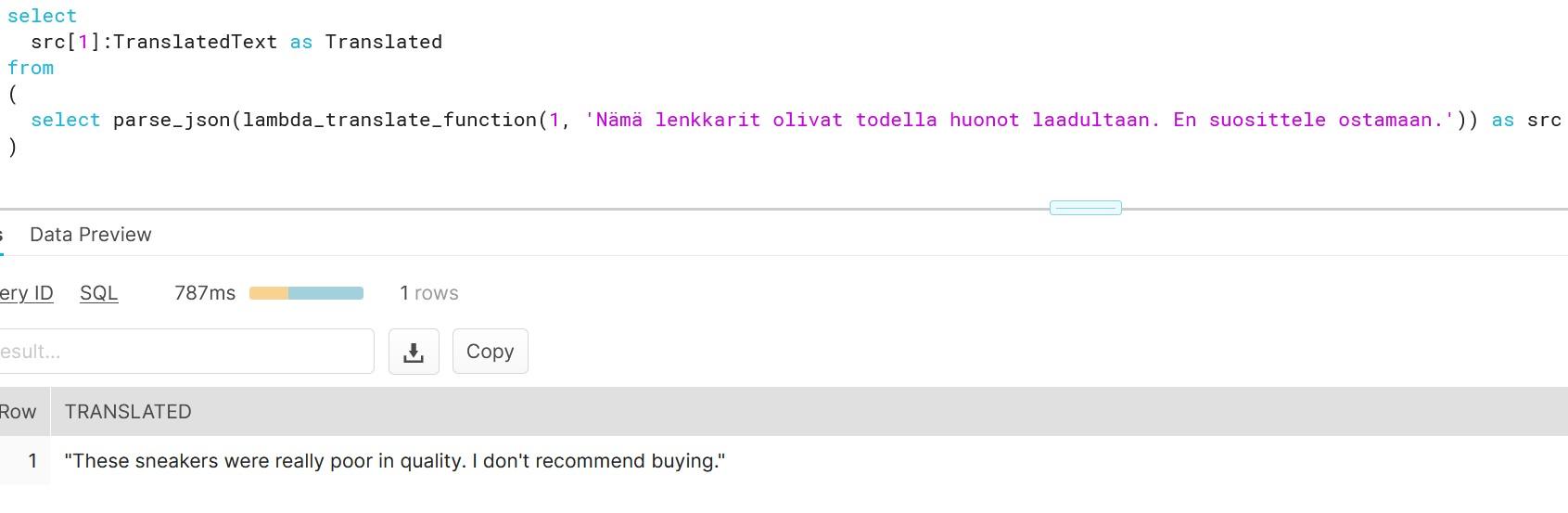 As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
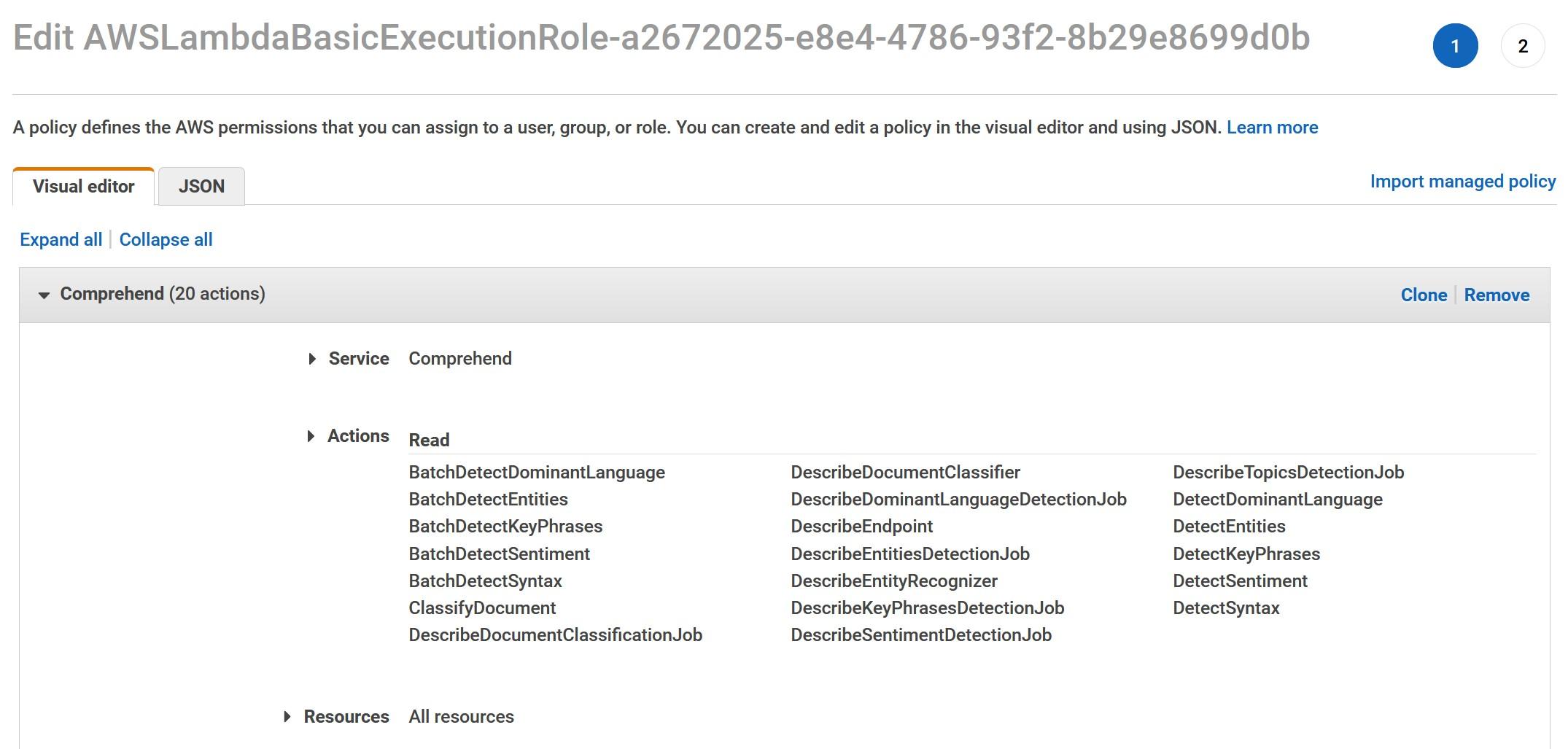
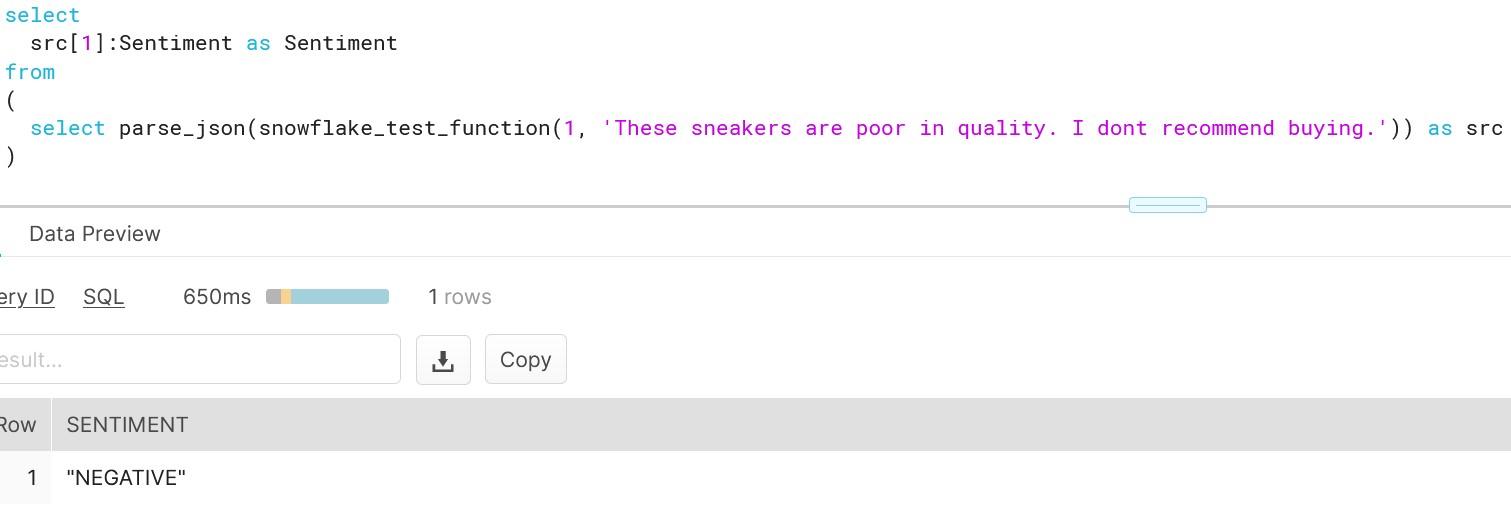
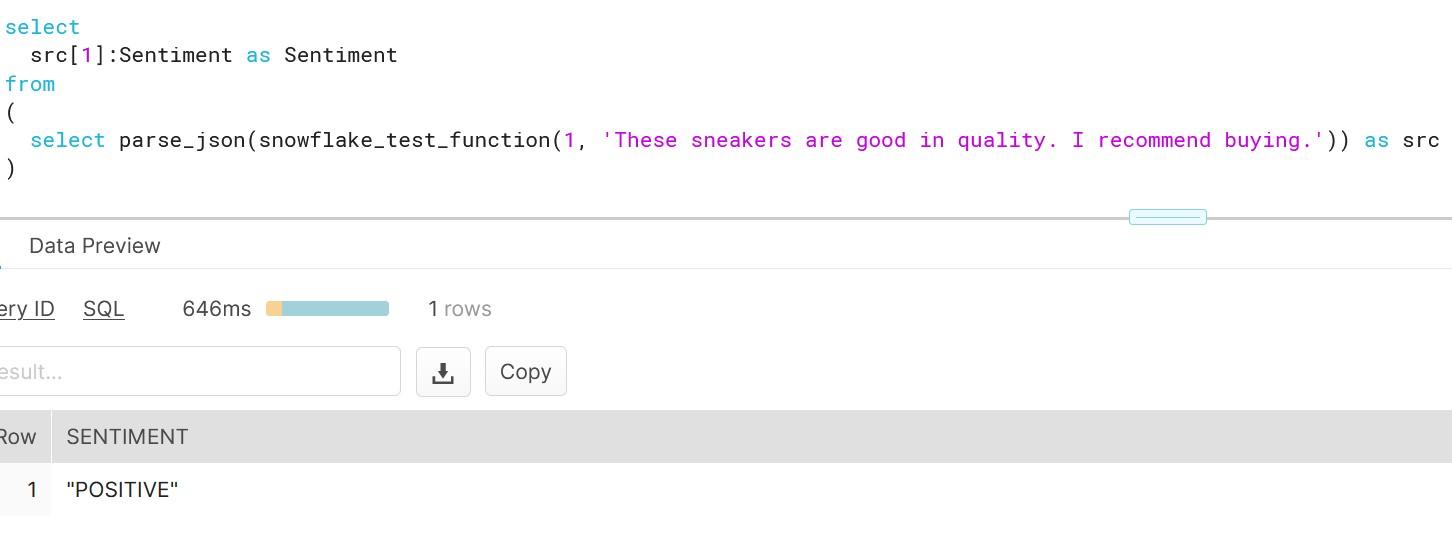
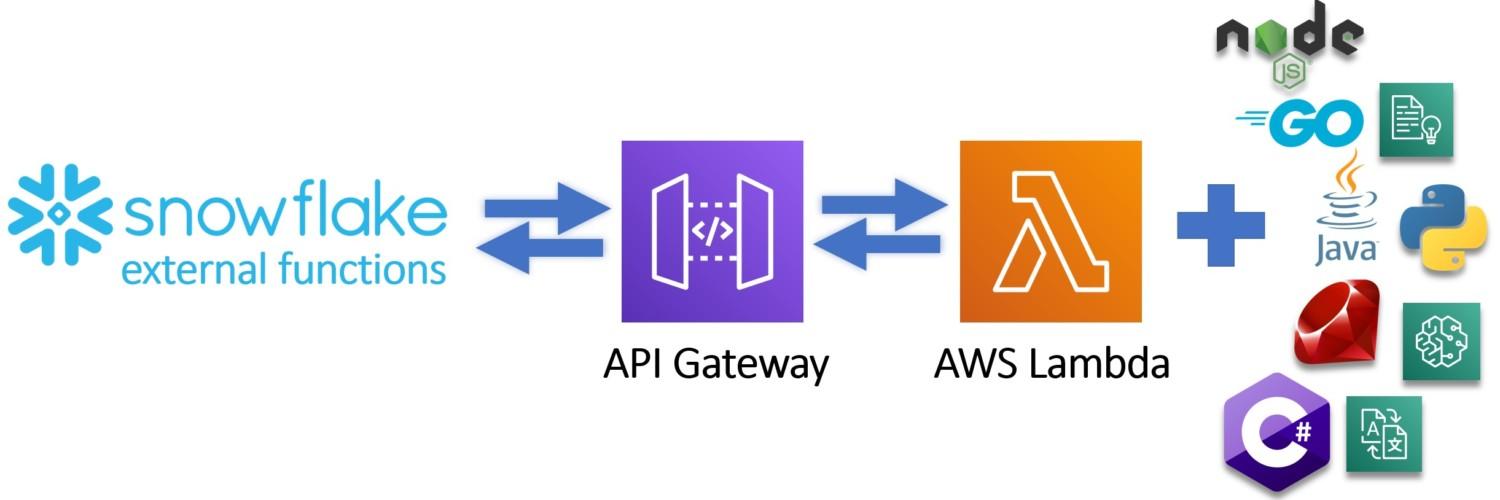

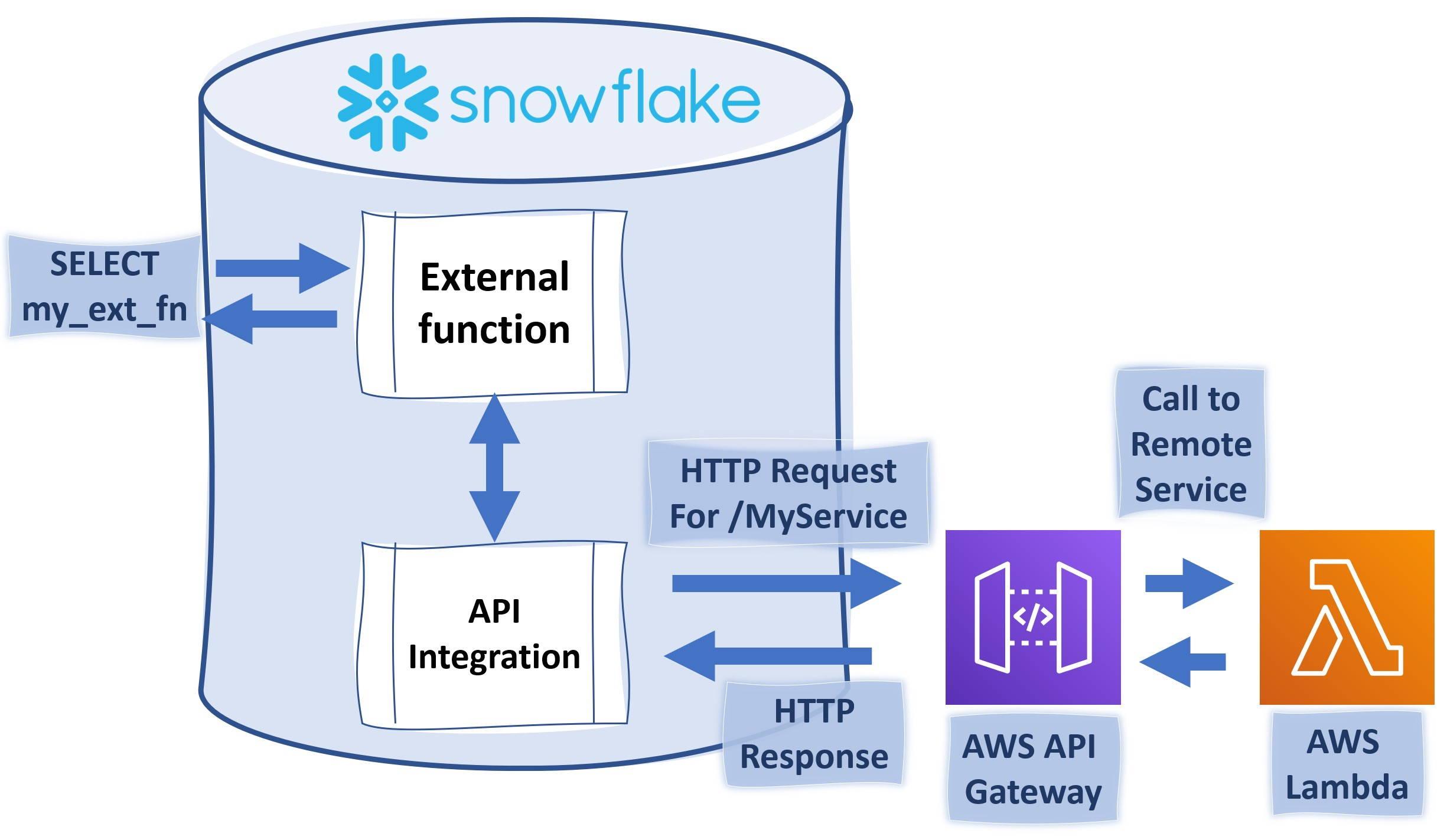
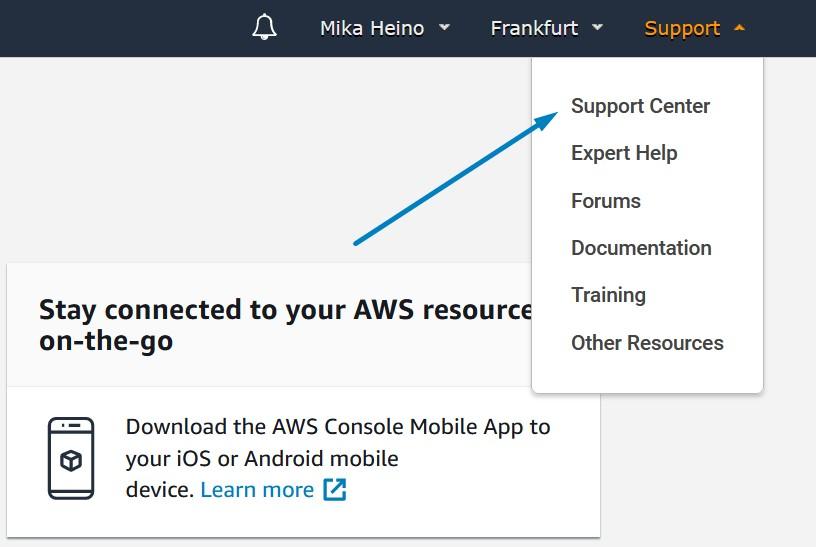
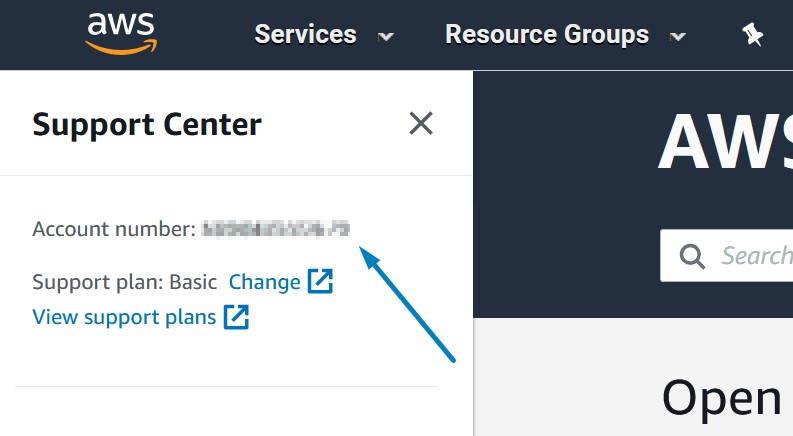

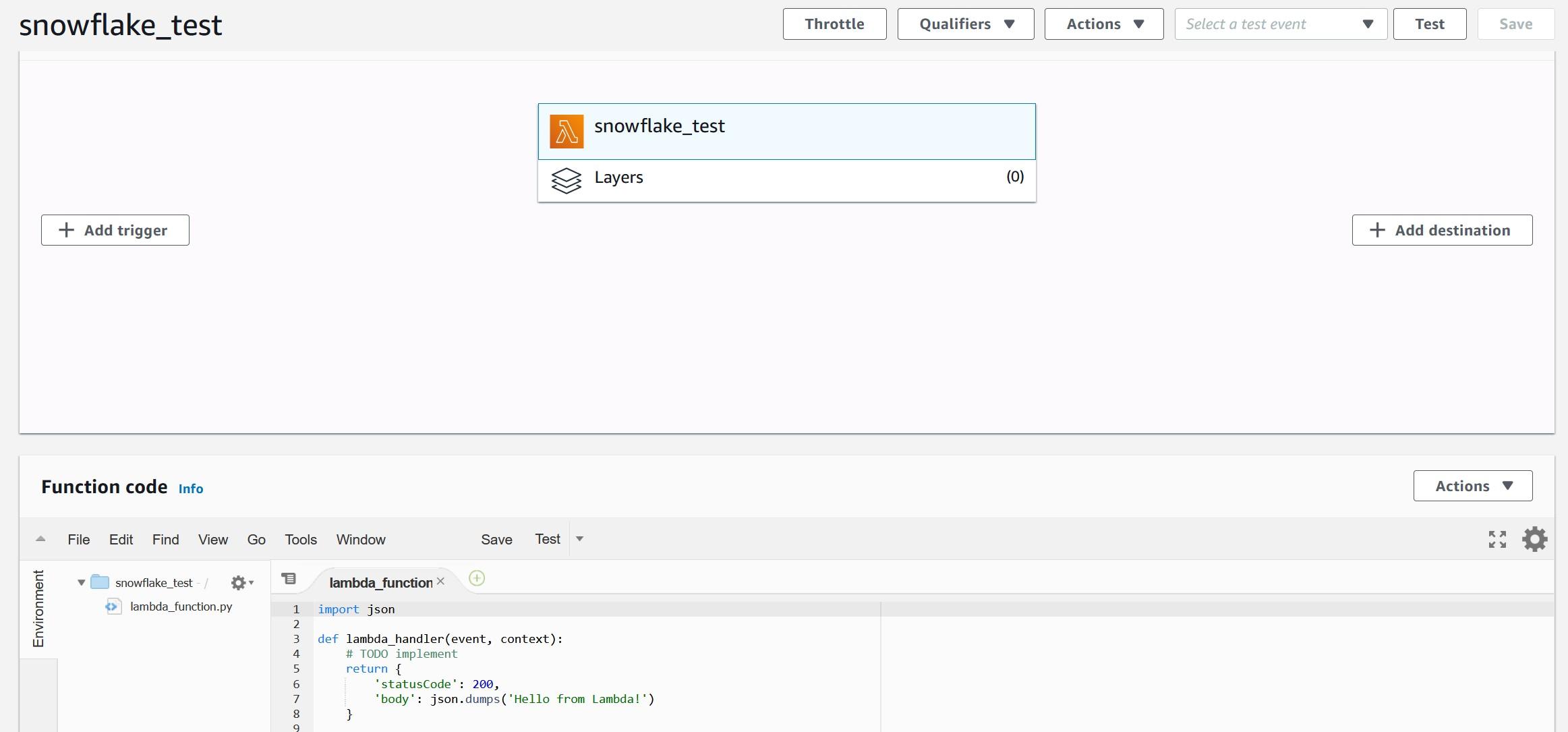


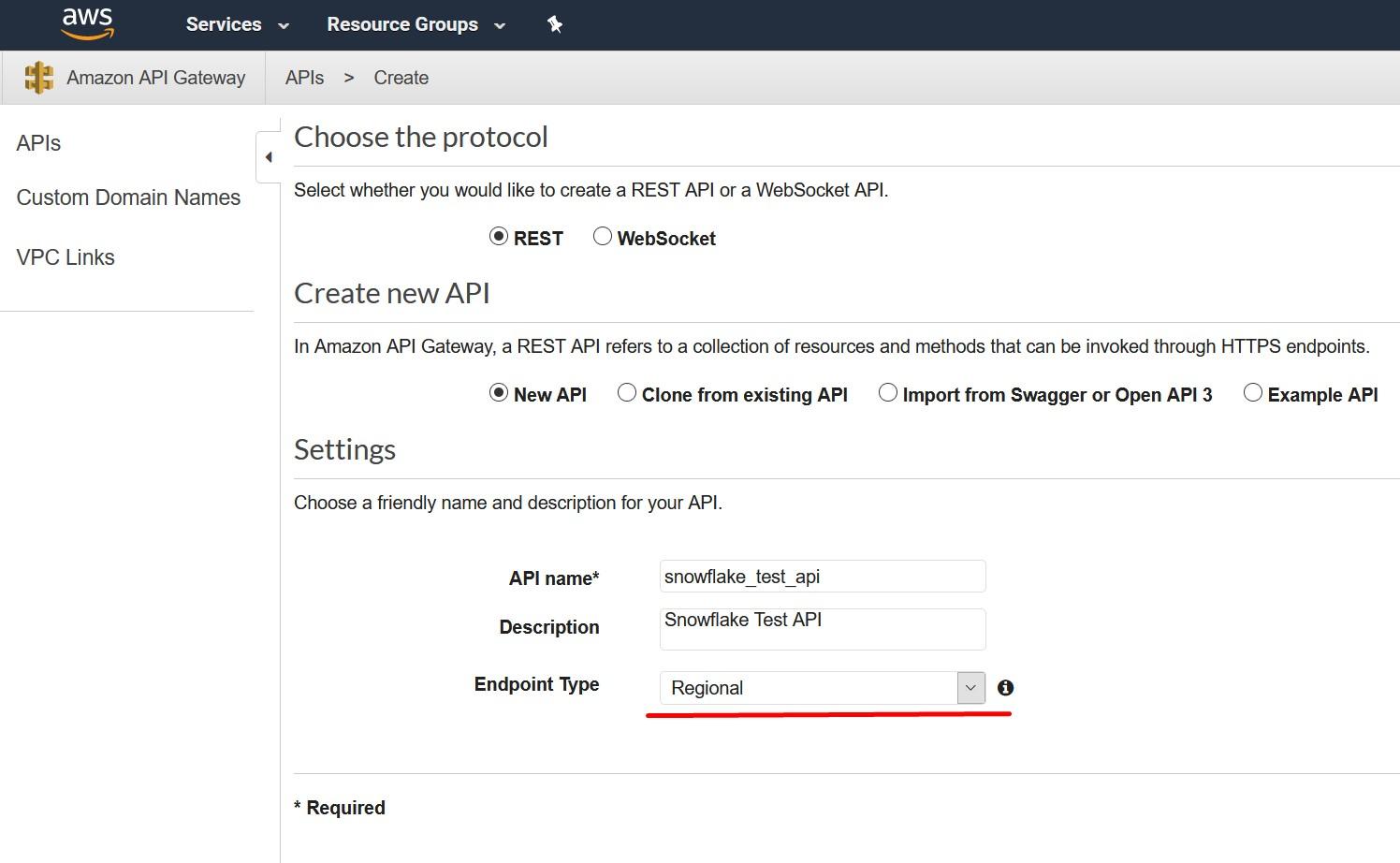
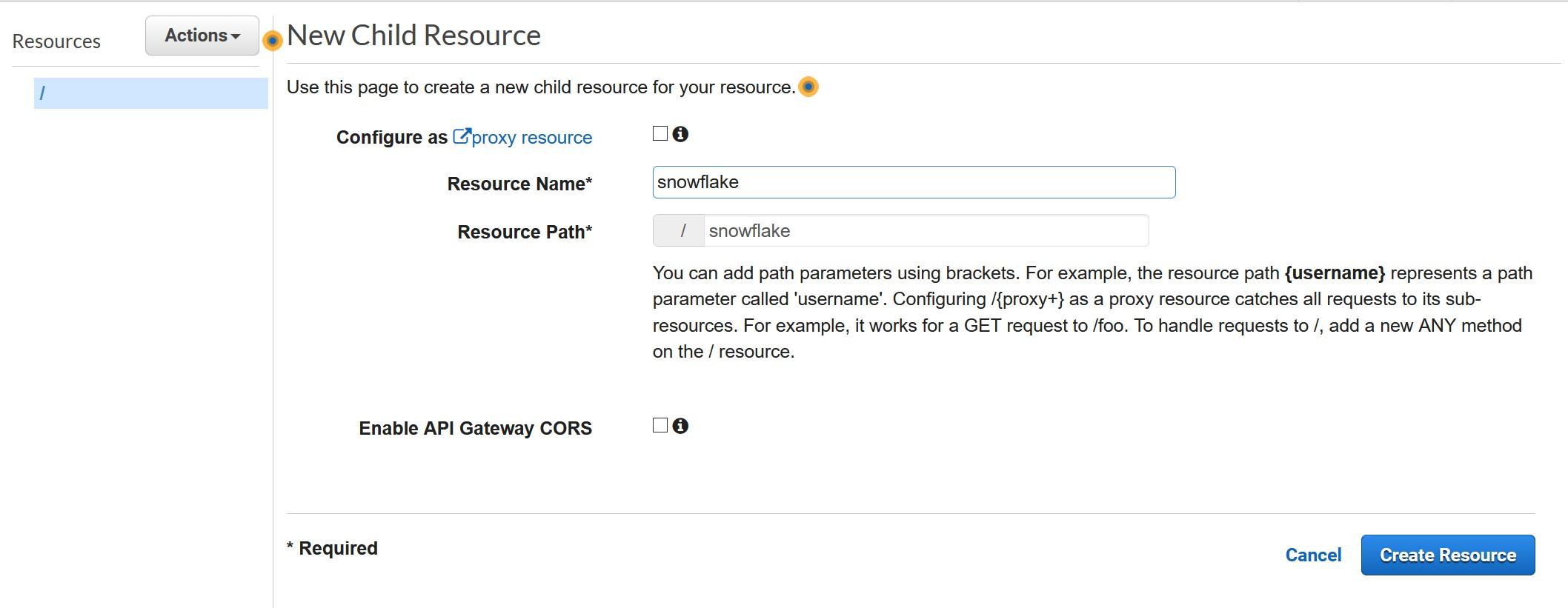
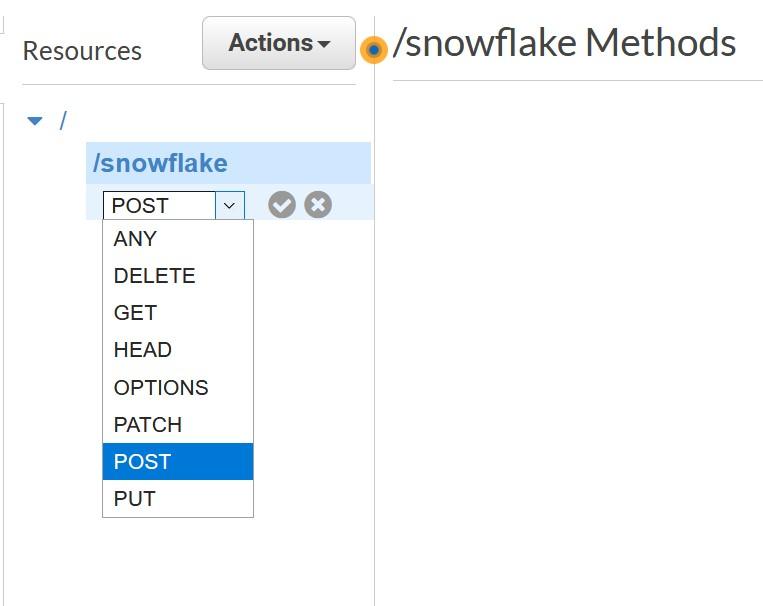
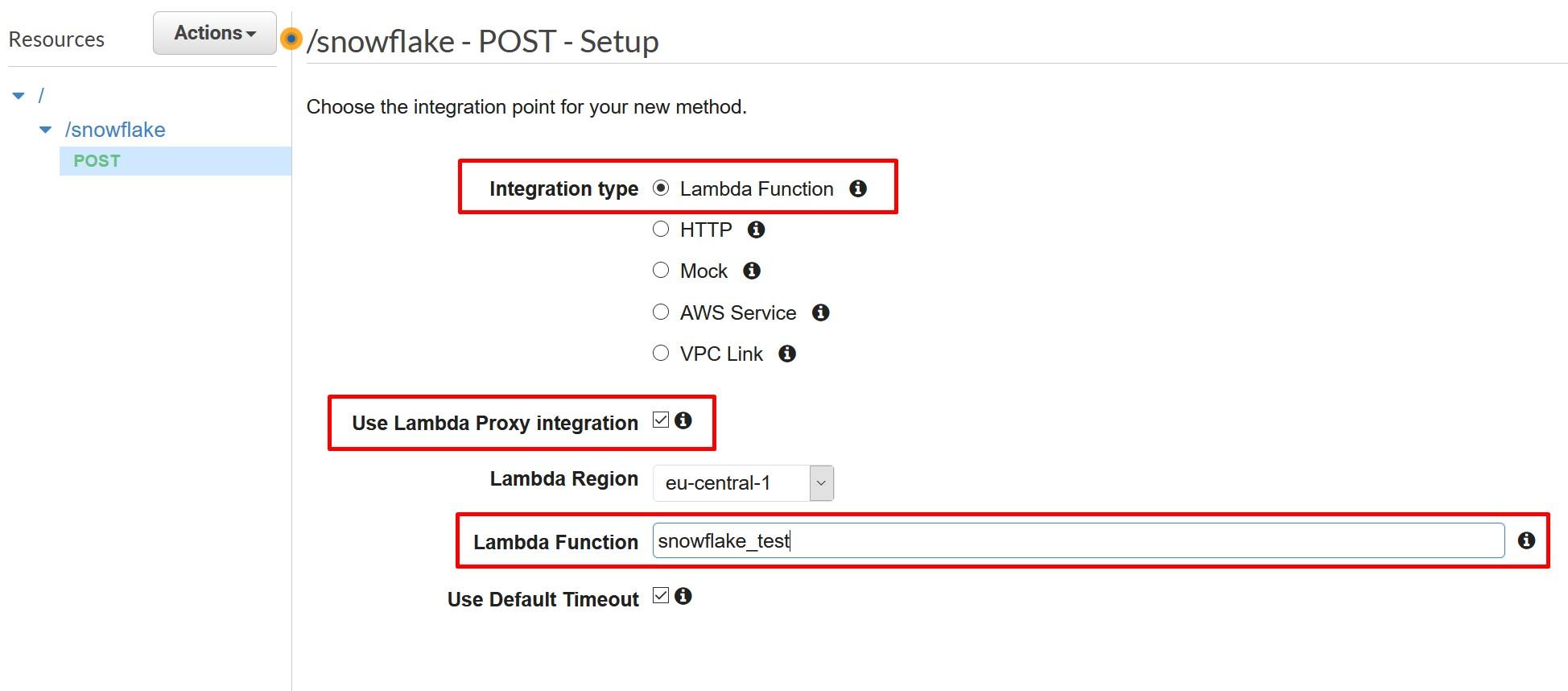
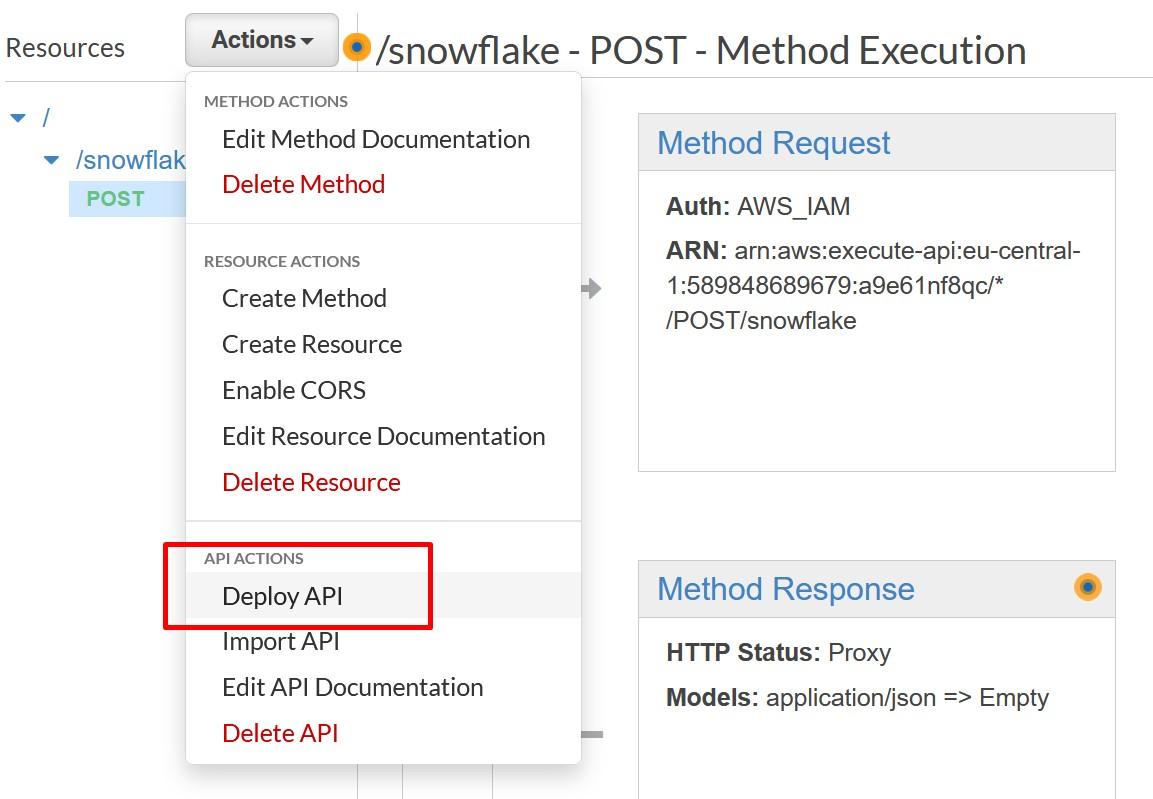
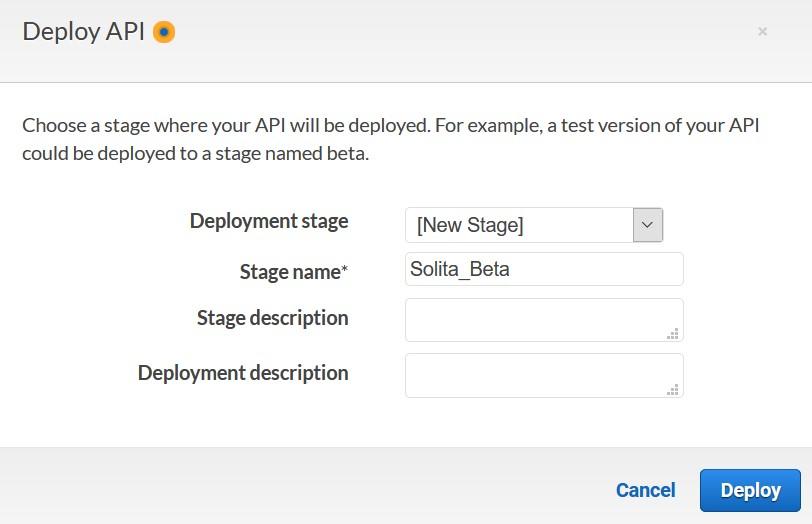
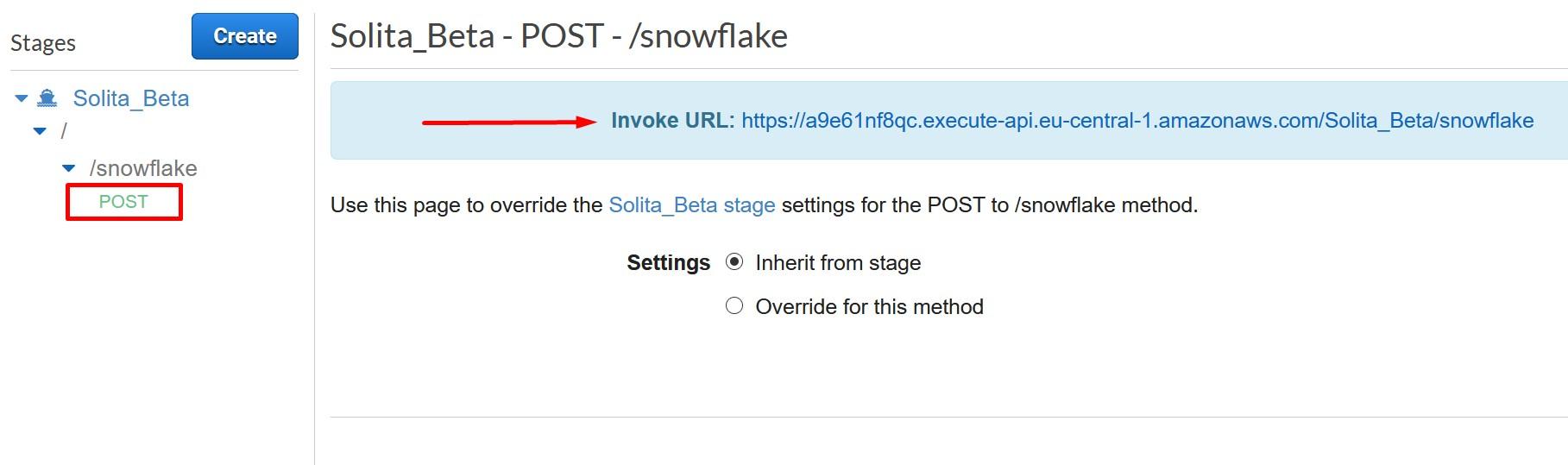
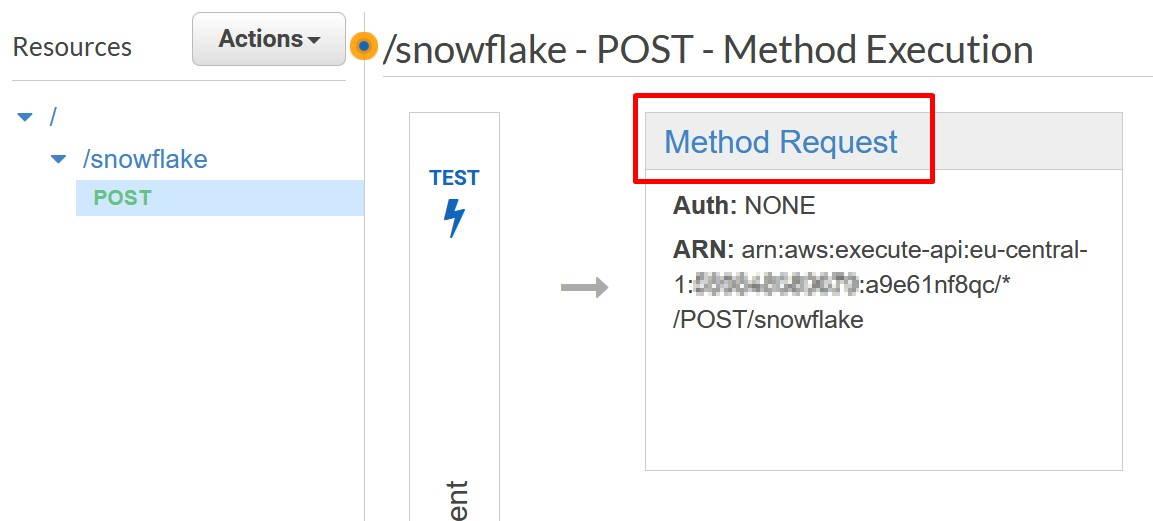
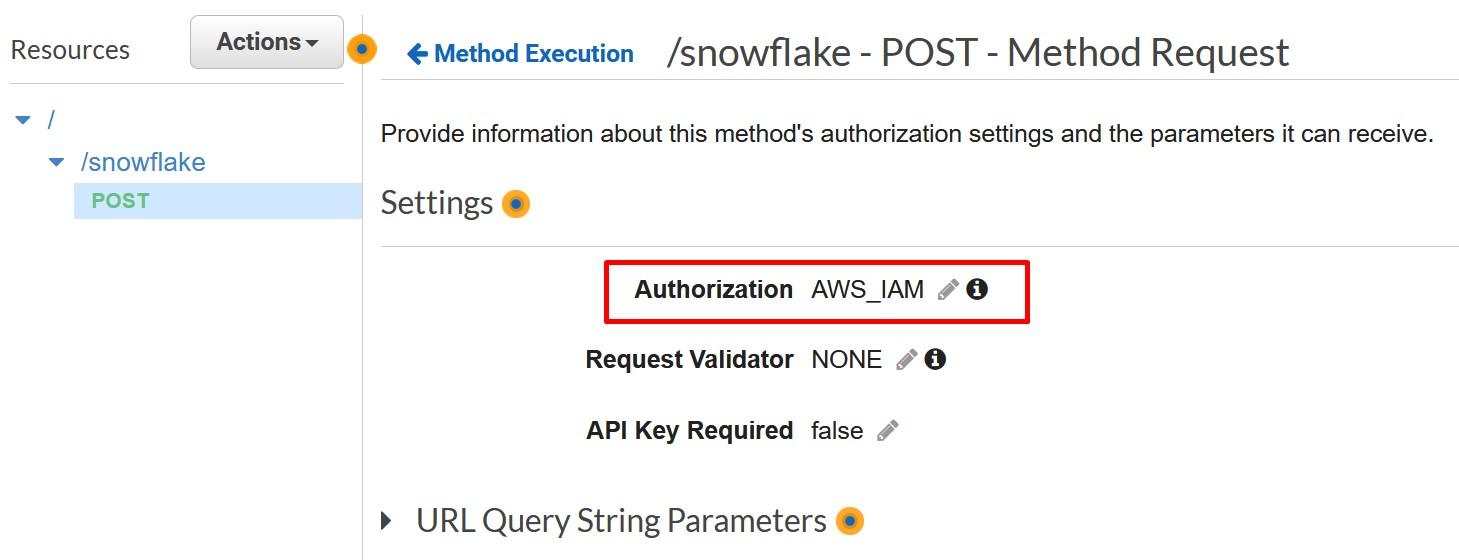
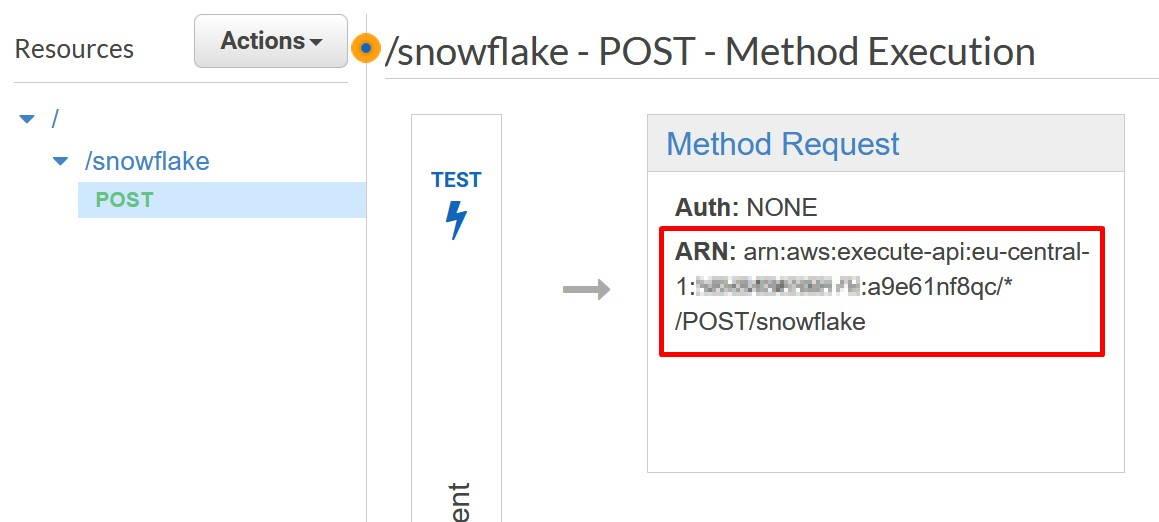
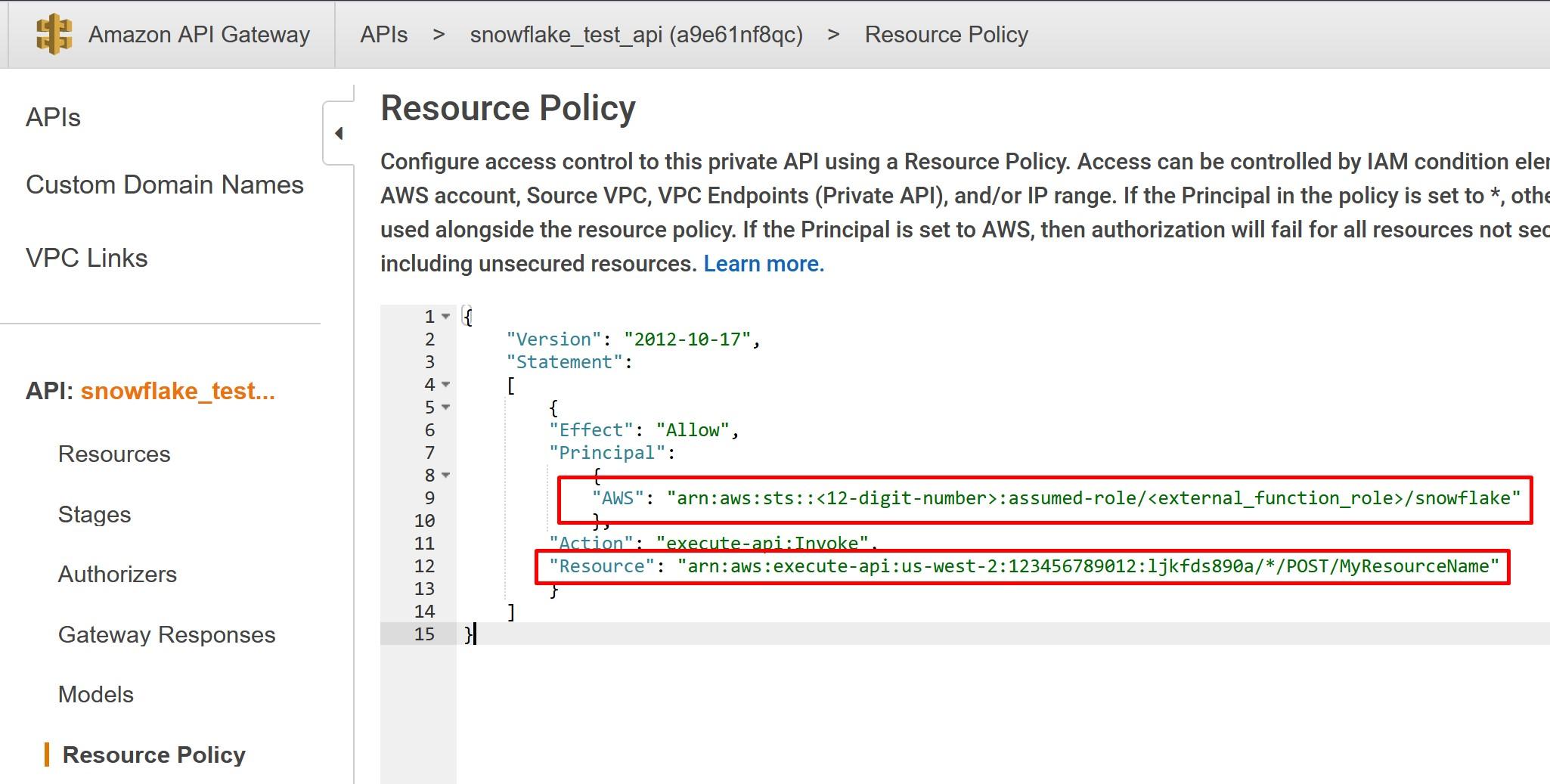

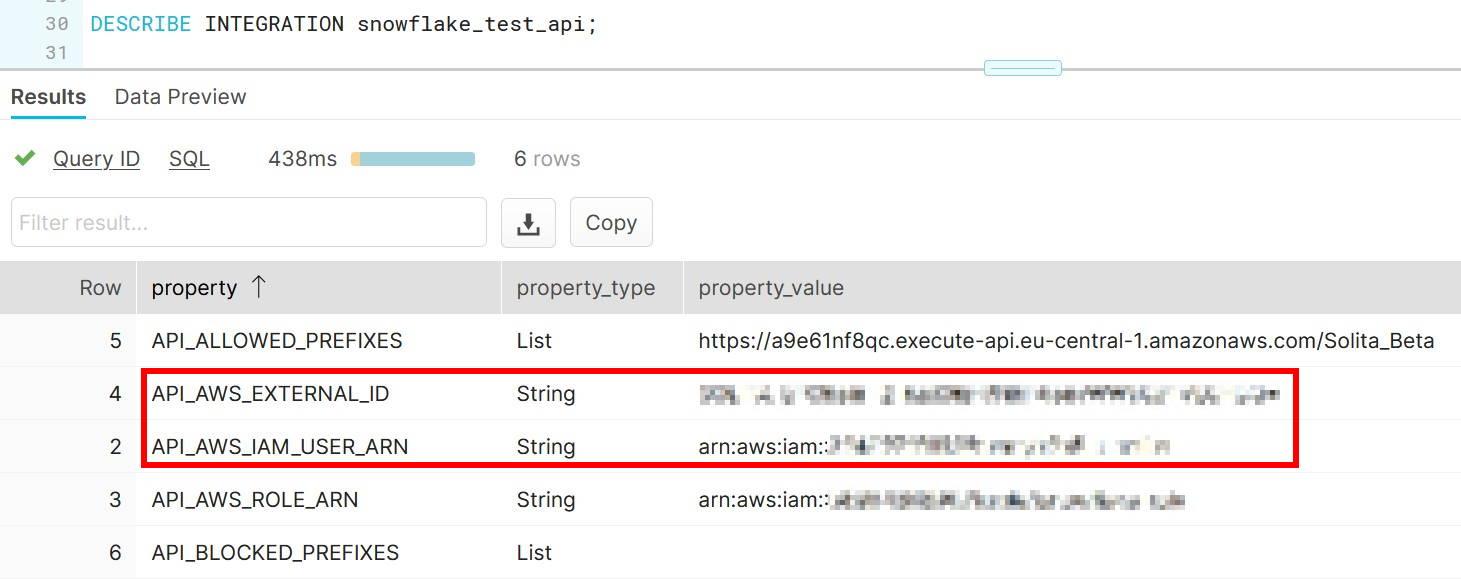
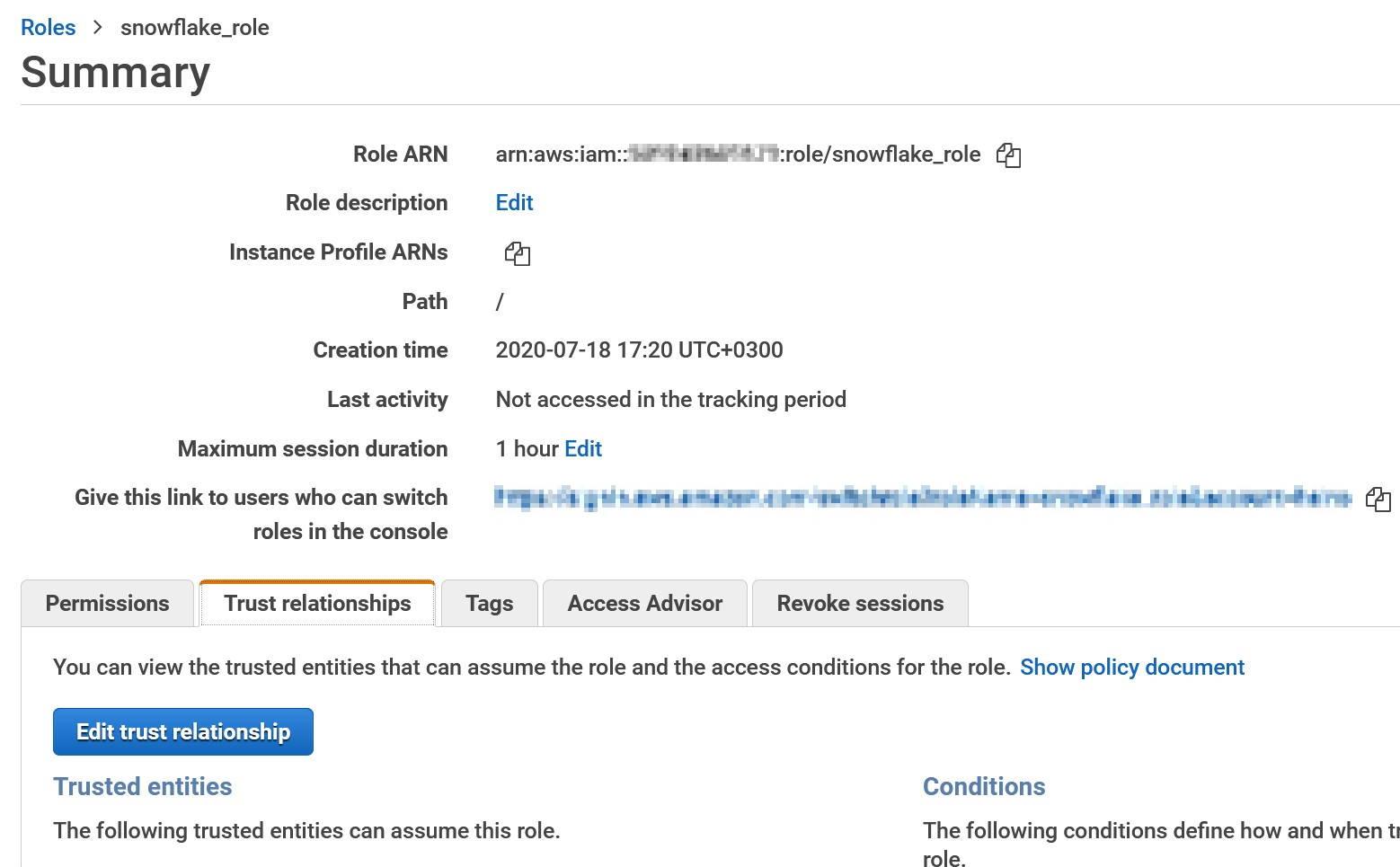
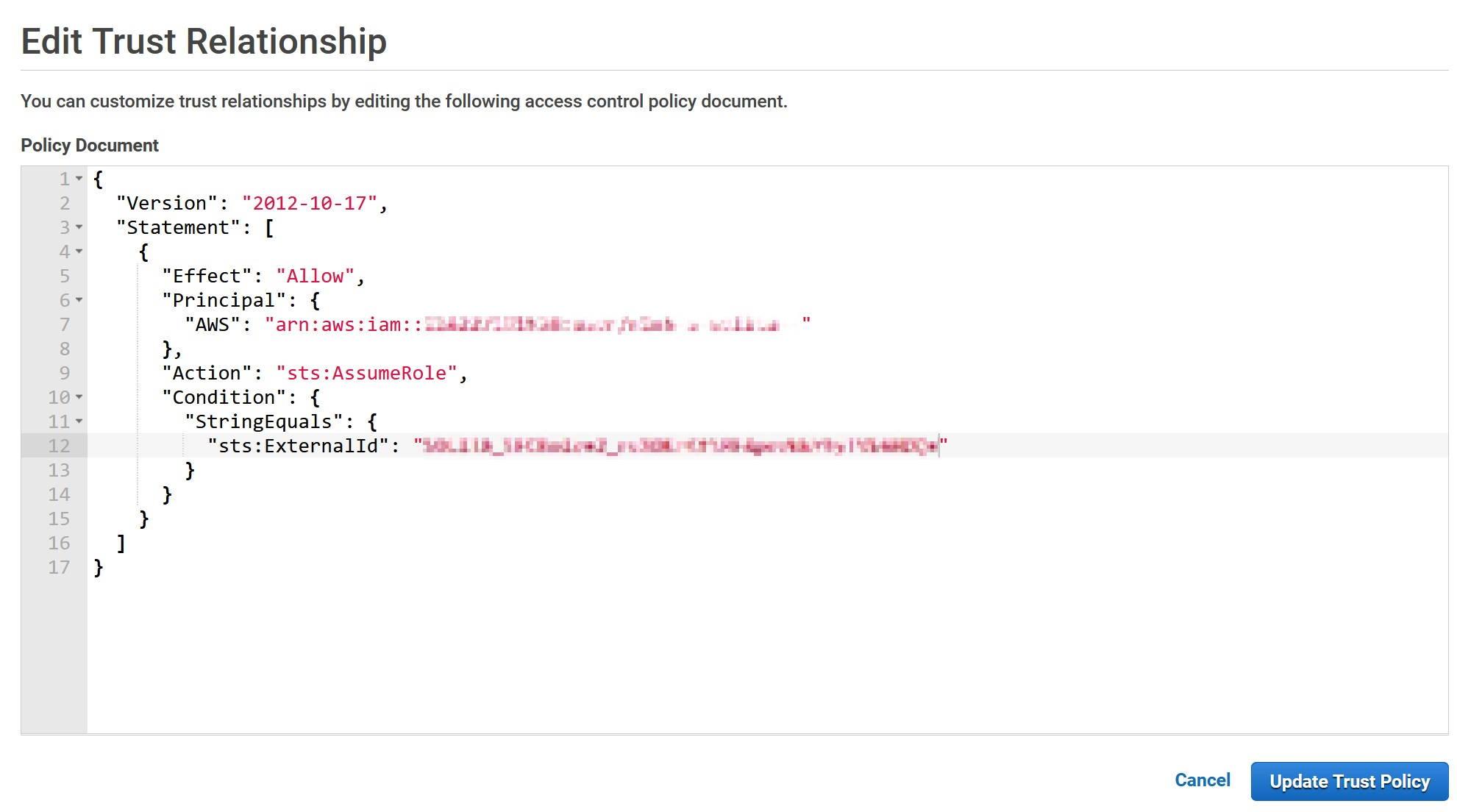

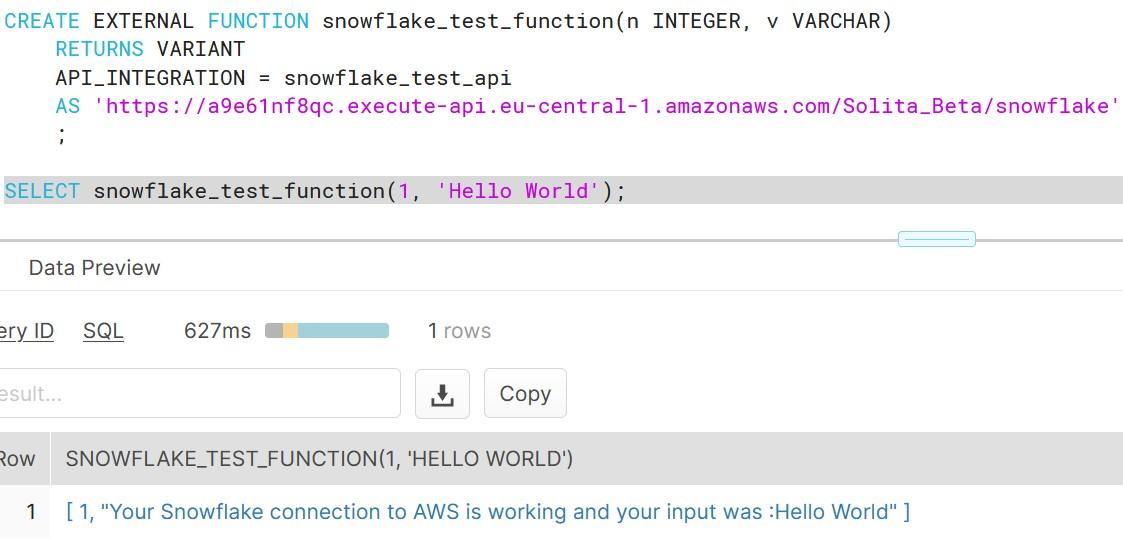


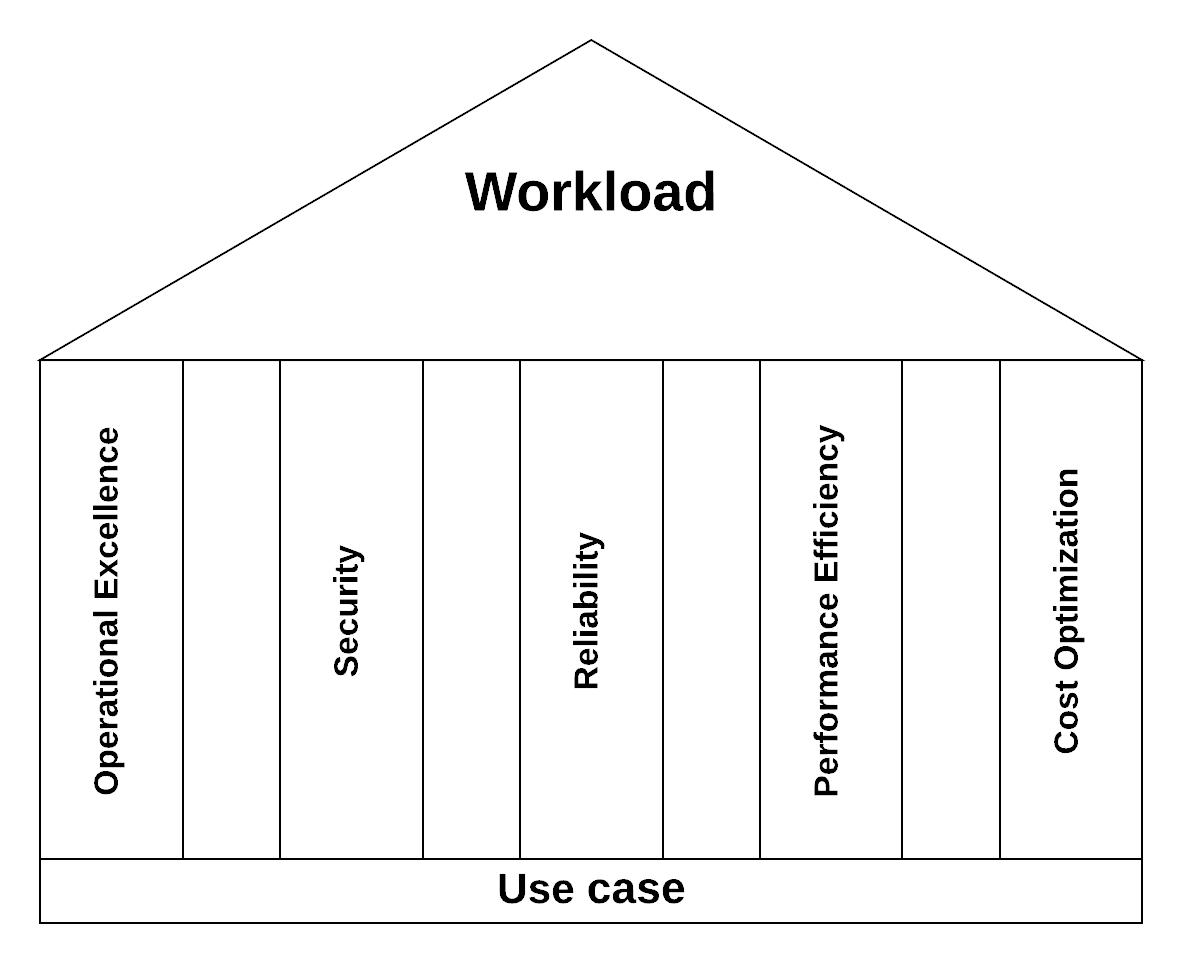


 More information: https://docs.snowflake.com/en/sql-reference/external-functions.html
More information: https://docs.snowflake.com/en/sql-reference/external-functions.html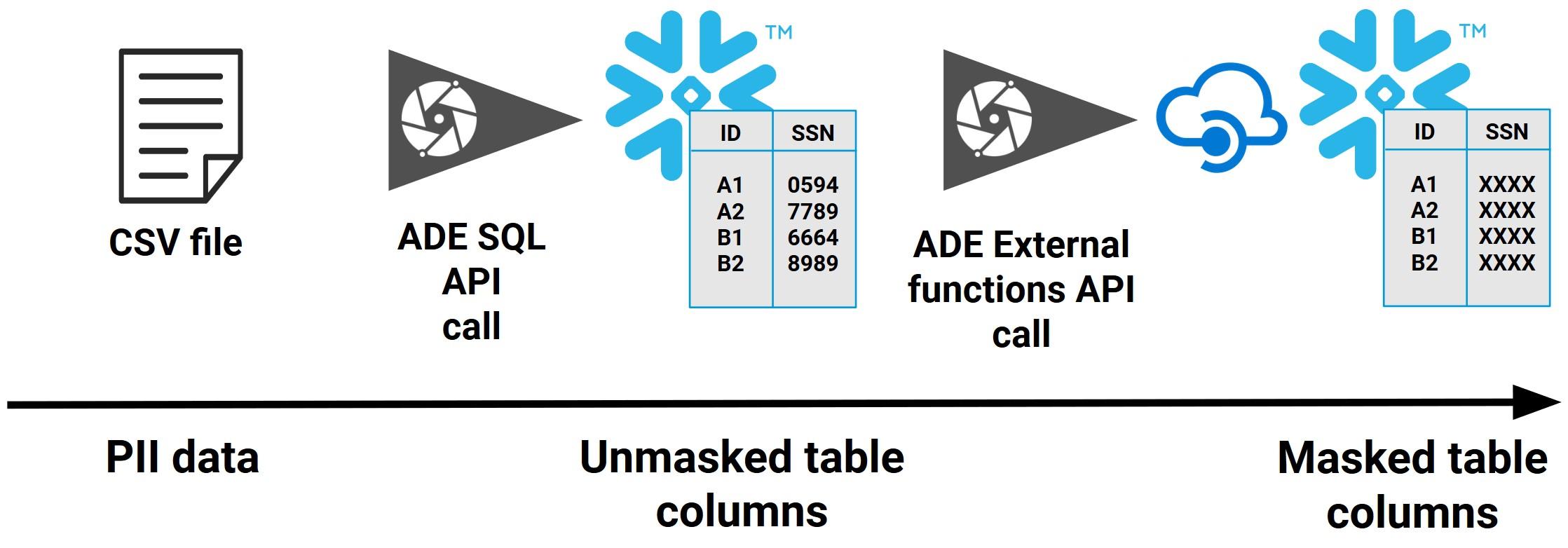



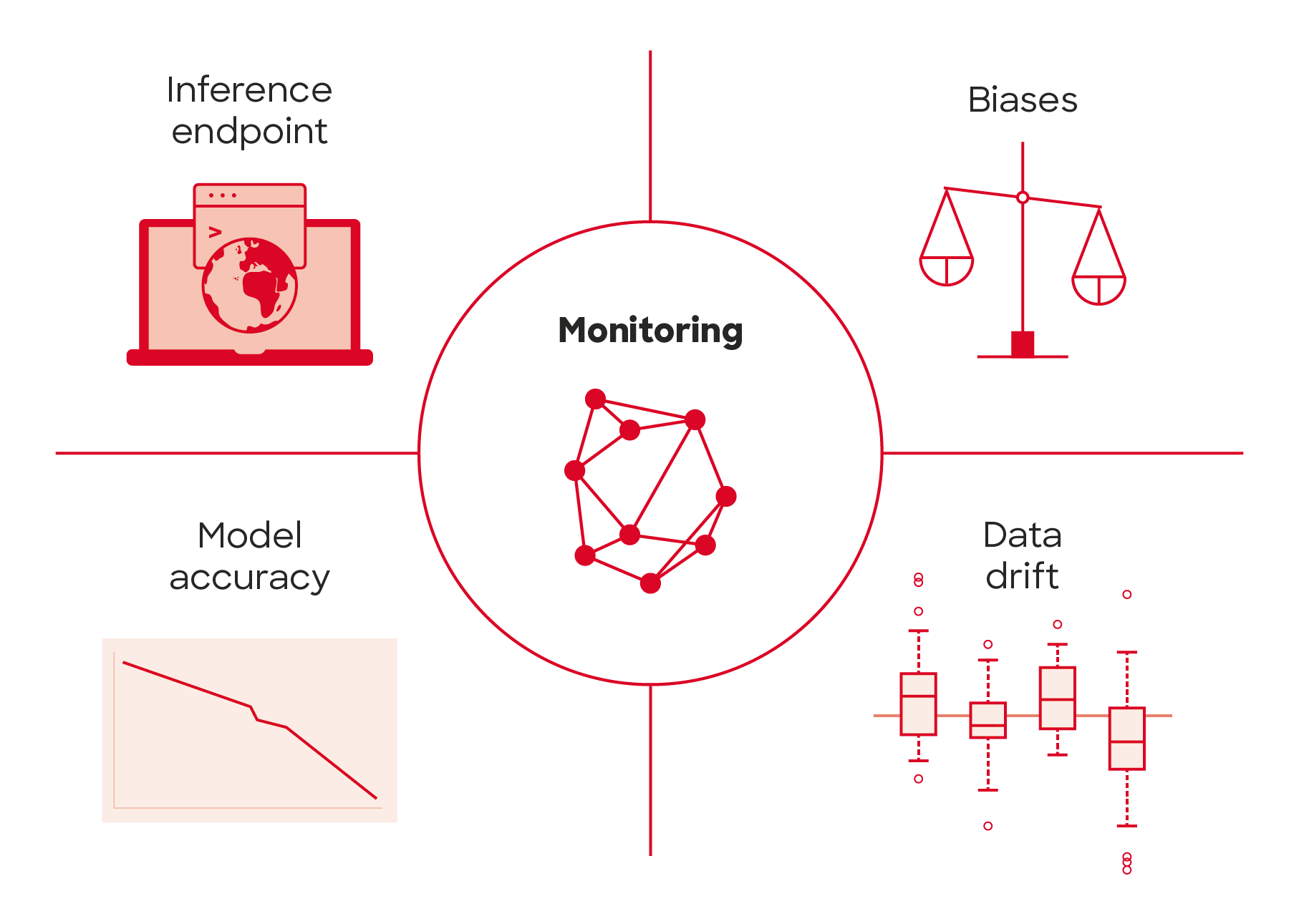




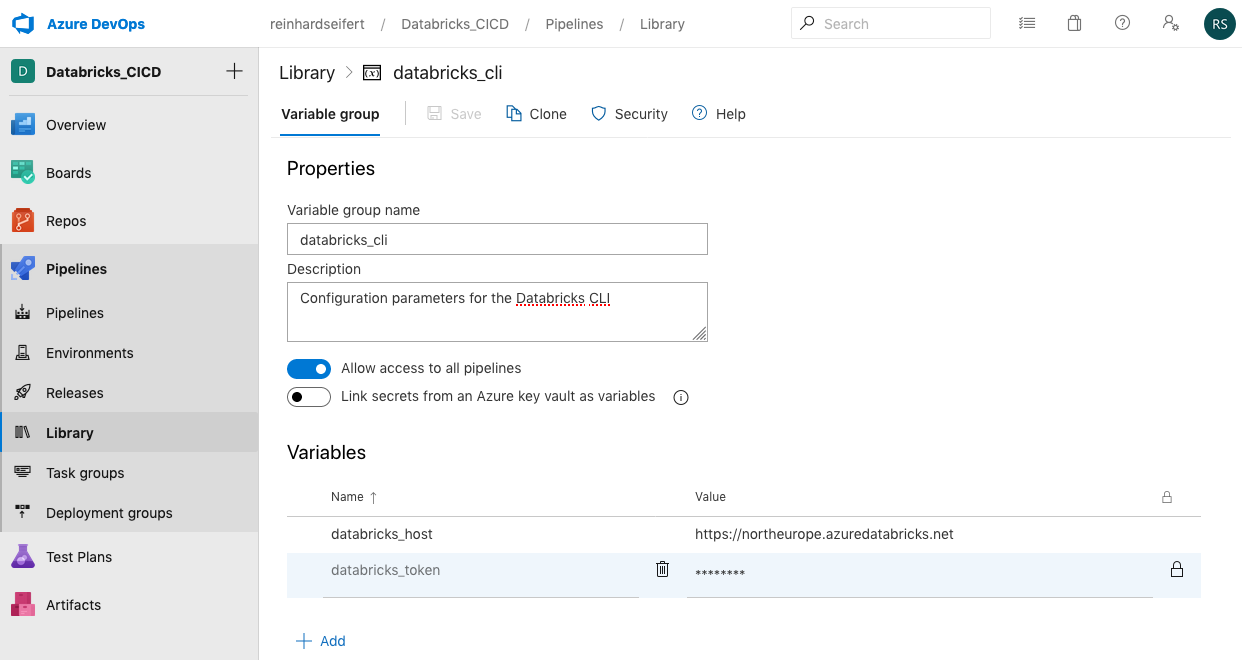





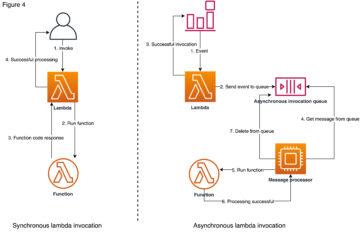




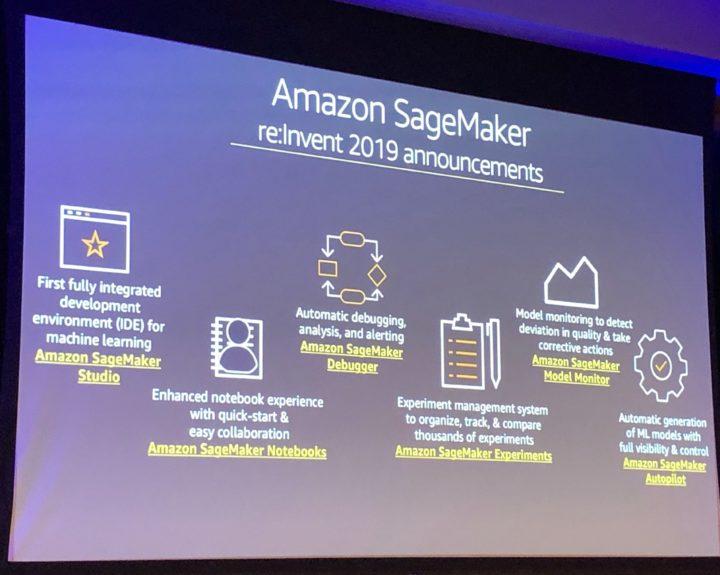






























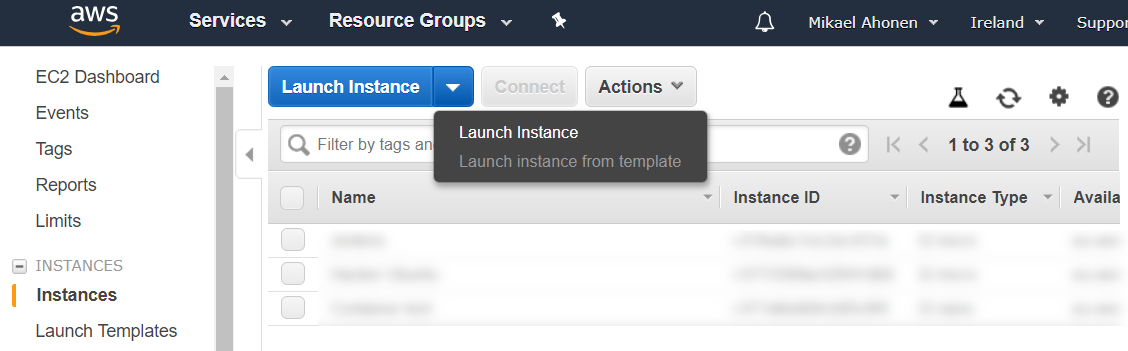
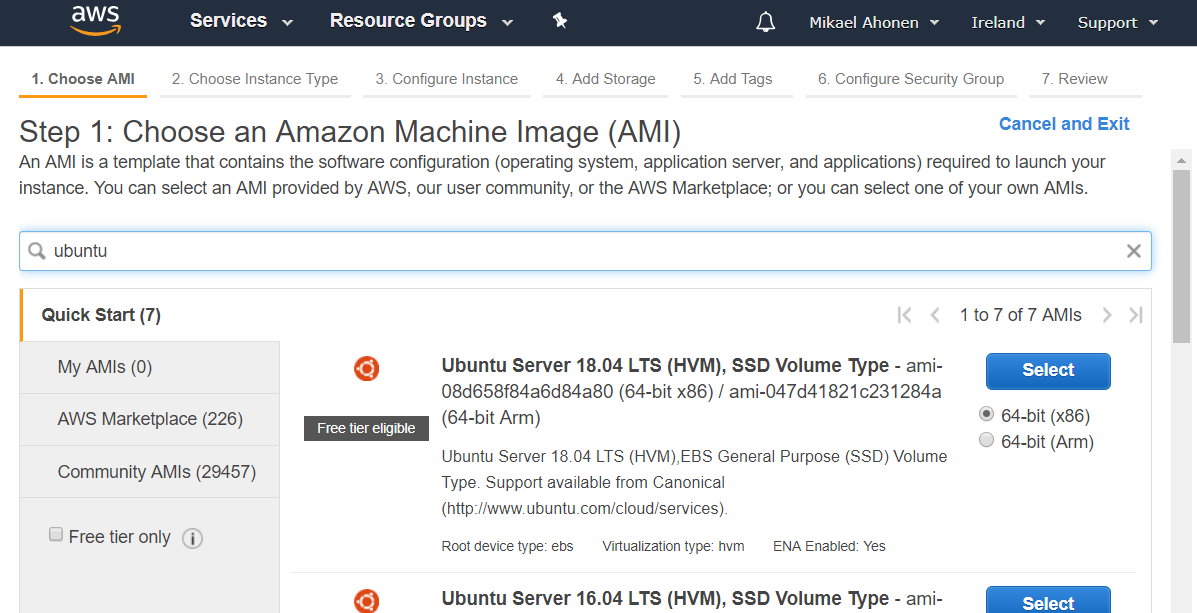
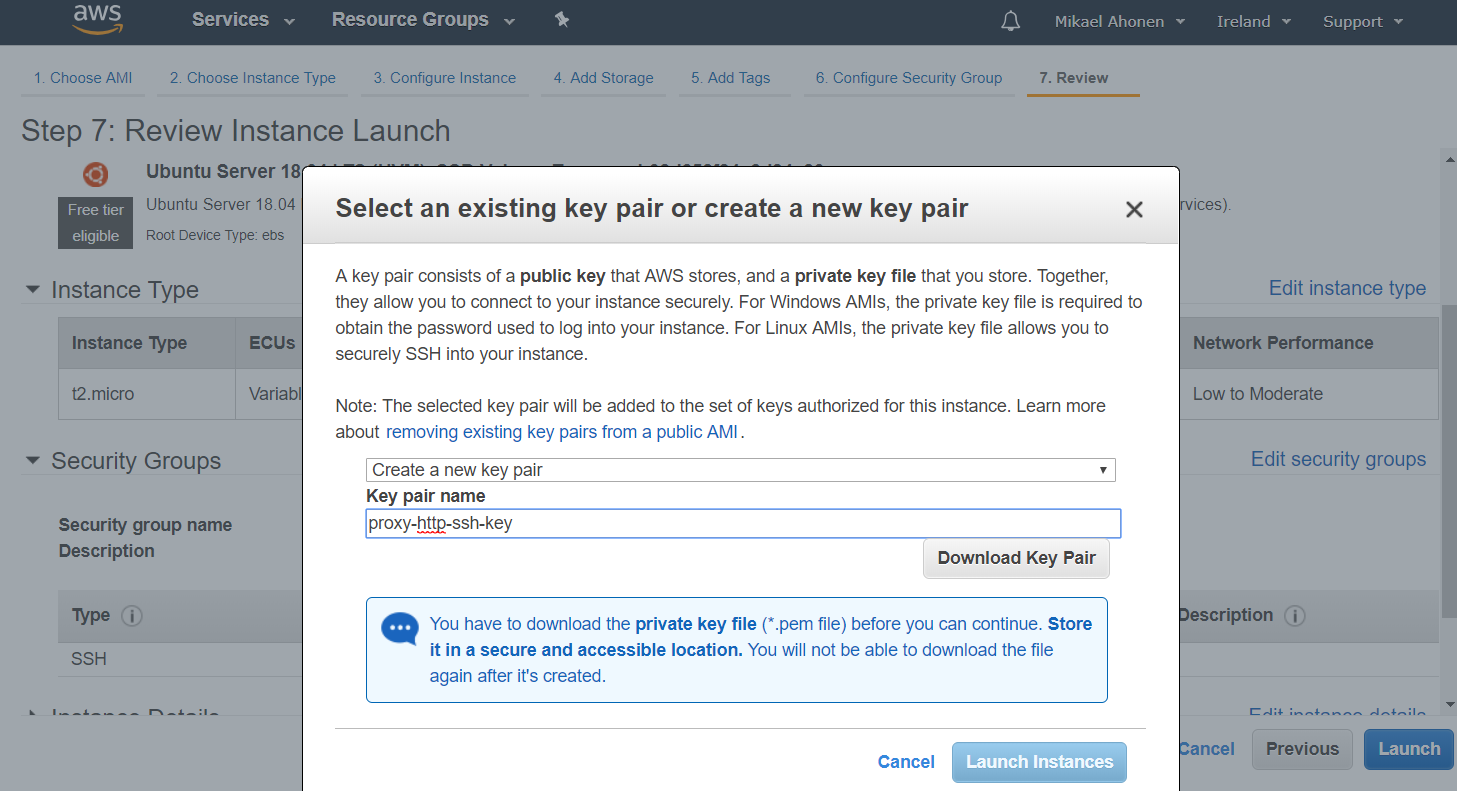


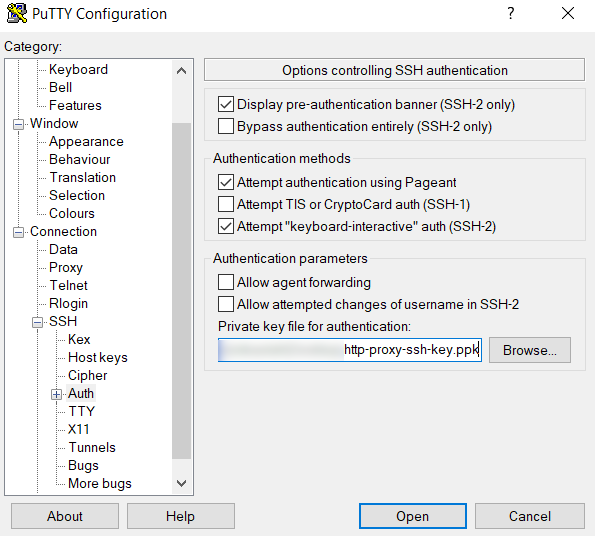
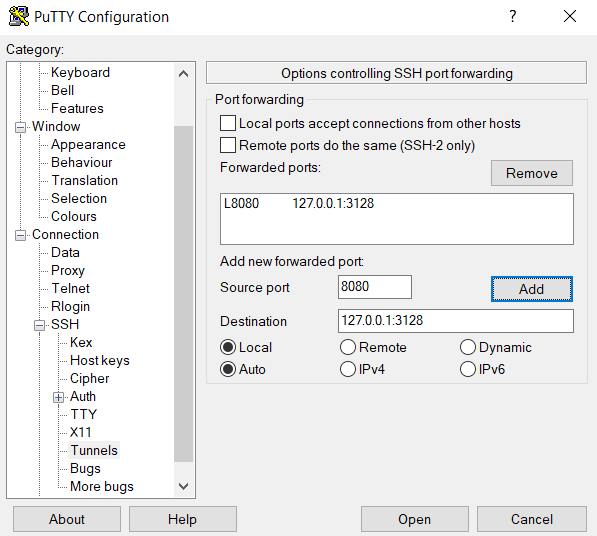







 The cost of warehouses are stored inside WAREHOUSE_METERING_HISTORY -table in CREDITS_USED column, but the Snowflake credits need to be converted into dollars and euro’s and grouped accordingly.
The cost of warehouses are stored inside WAREHOUSE_METERING_HISTORY -table in CREDITS_USED column, but the Snowflake credits need to be converted into dollars and euro’s and grouped accordingly.