A Beginner’s Guide to AutoML
Automated Machine Learning (AutoML) is a concept that provides the means to utilise existing data and create models for non-Machine Learning experts. In addition to that, AutoML provides Machine Learning (ML) professionals ways to develop and use effective models without spending time on tasks such as data cleaning and preprocessing, feature engineering, model selection, hyperparameter tuning, etc.
Before we move any further, it is important to note that AutoML is not some system that has been developed by a single entity. Several organisations have developed their own AutoML packages. These packages cover a broad area, and targets people at different skill levels.
In this blog, we will cover low-code approaches to AutoML that require very little knowledge about ML. There are AutoML systems that are available in the form of Python packages that we will cover in the future.
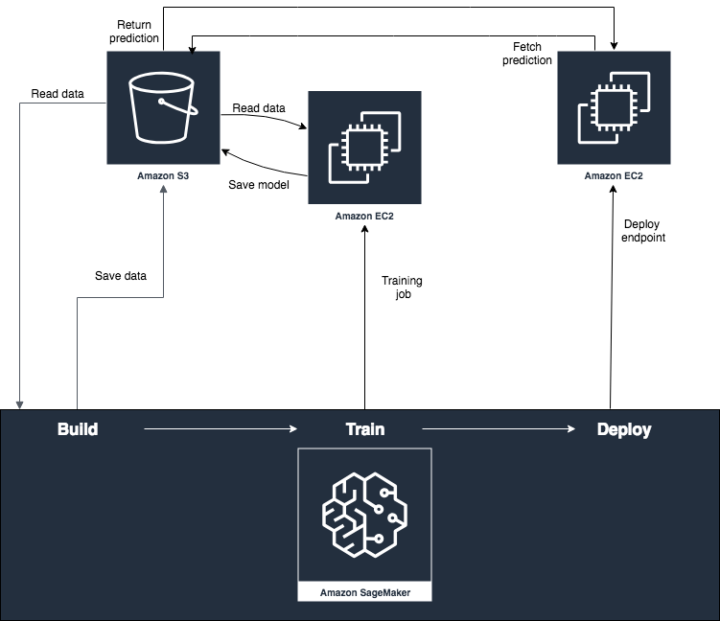
At the simplest level, both AWS and Google have introduced Amazon Sagemaker and Cloud AutoML, which are low-code PAAS solutions for AutoML. These cloud solutions are capable of automatically building effective ML models. The models can then be deployed and utilised as needed.
Data
In most cases, a person working with the platform doesn’t even need to know much about the dataset they want to analyse. The work carried out here is as simple as uploading a CSV file and generating a model. We will take a look at Amazon Sagemaker as an example. However, the process is similar in other existing cloud offerings.
With Sagemaker, we can upload our dataset to an S3 bucket and tell our model that we want to be working with that dataset. This is achieved using Sagemaker Canvas, which is a visual, no code platform.

The dataset we are working with in this example contains data about electric scooters. Our goal is to create a model that predicts the battery level of a scooter given a set of conditions.
Creating the model
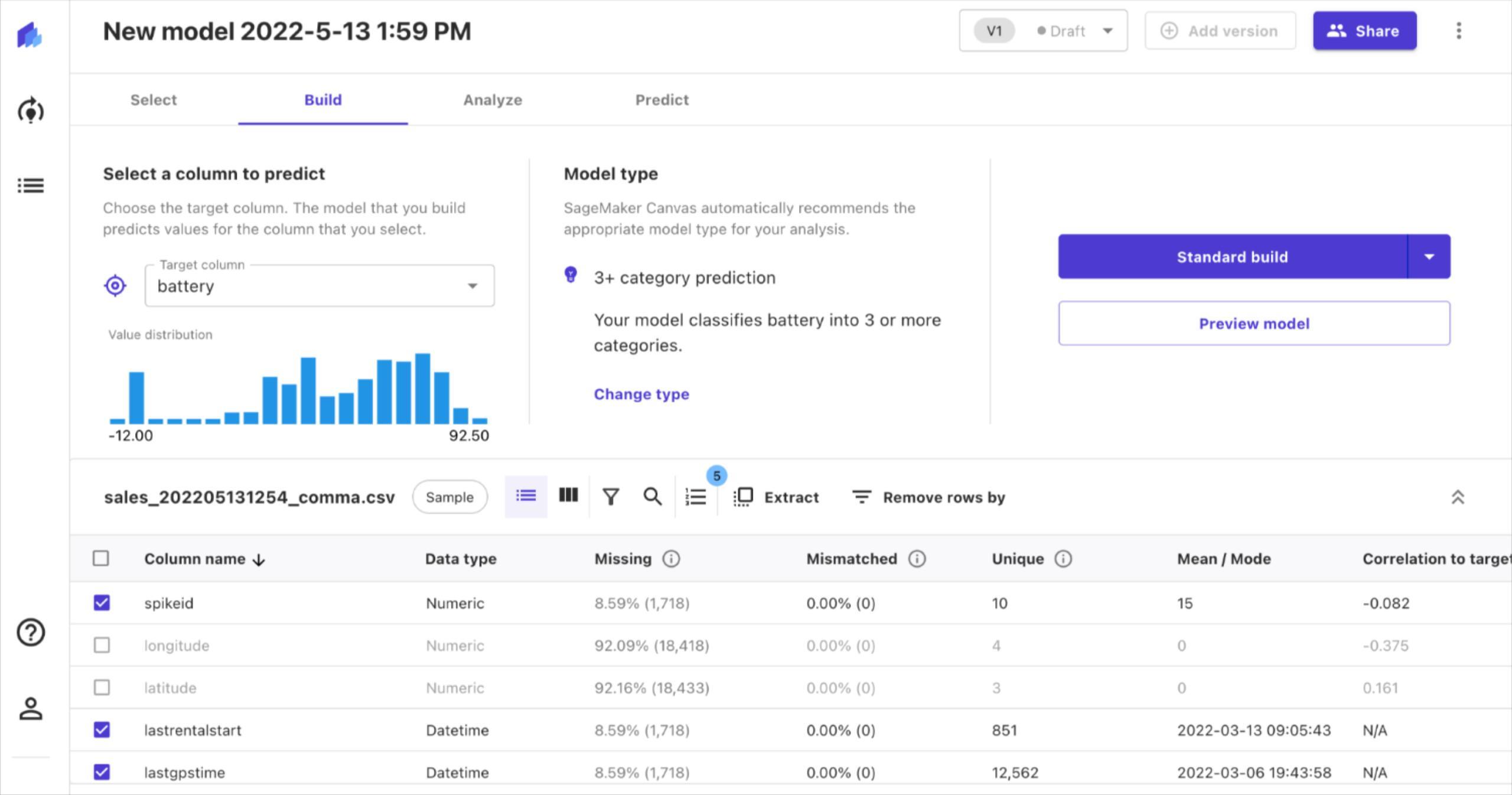
In this case, we say that our target column is “battery”. We can also see details of the other columns in our dataset. For example, the “latitude”and “longitude” columns have a significant amount of missing data. Thus, we can choose not to include those in our analysis.
Afterwards, we can choose the type of model we want to create. By default, Sagemaker suggests creating a model that classifies the battery level into 3 or more categories. However, what we want is to predict the battery level.
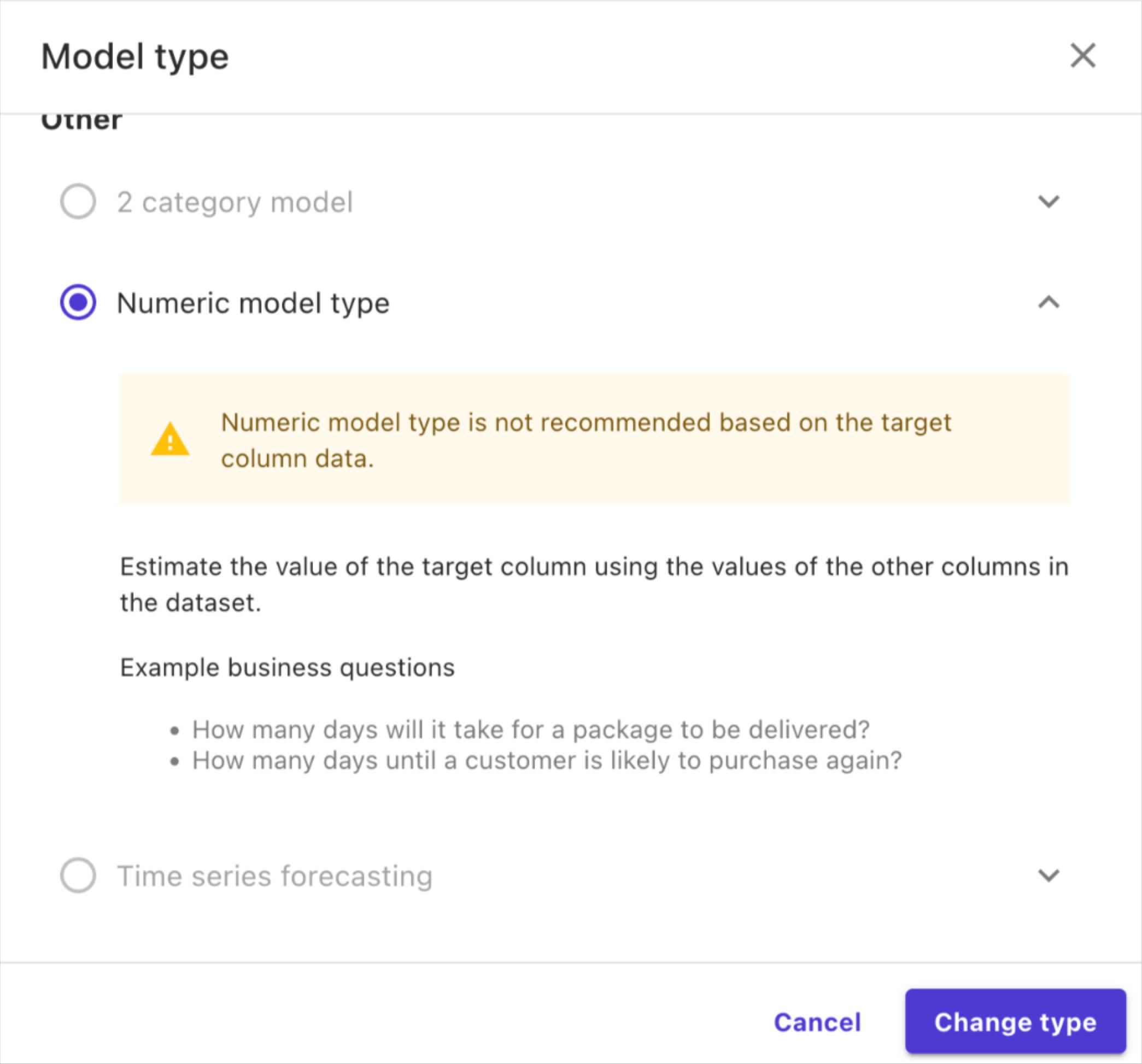
Therefore, we can change the model type to “numeric” in order to predict battery level.
Thereafter, we can begin building our models. This is a process that takes a considerable amount of time. Sagemaker gives you the option to “preview” the model that would be built before starting the actual build.
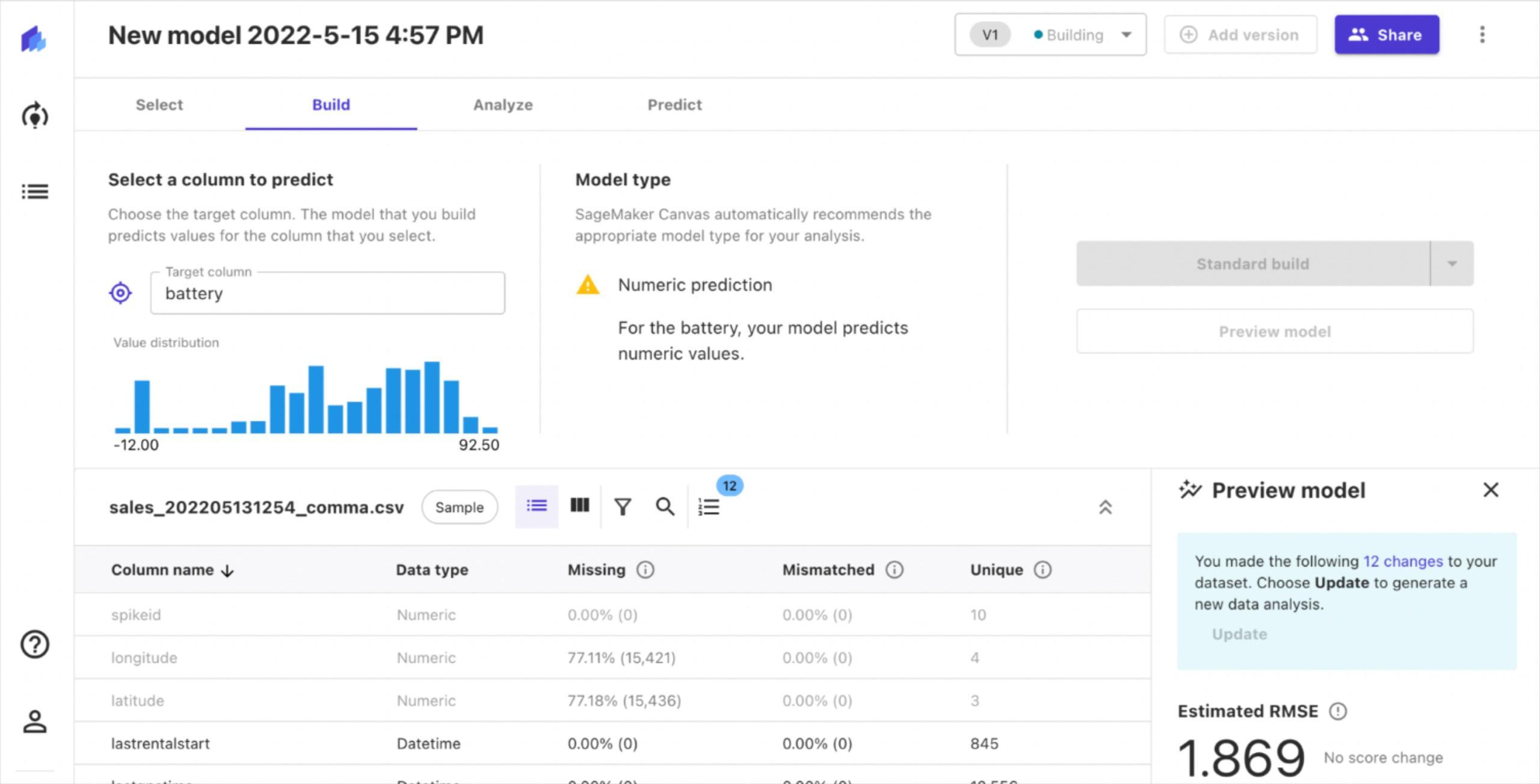
The preview only takes a few minutes, and provides an estimate of the performance we can expect from the final model. Since our goal is to predict the battery level, we will have a regression model. This model can be evaluated with RMSE (root mean square error).
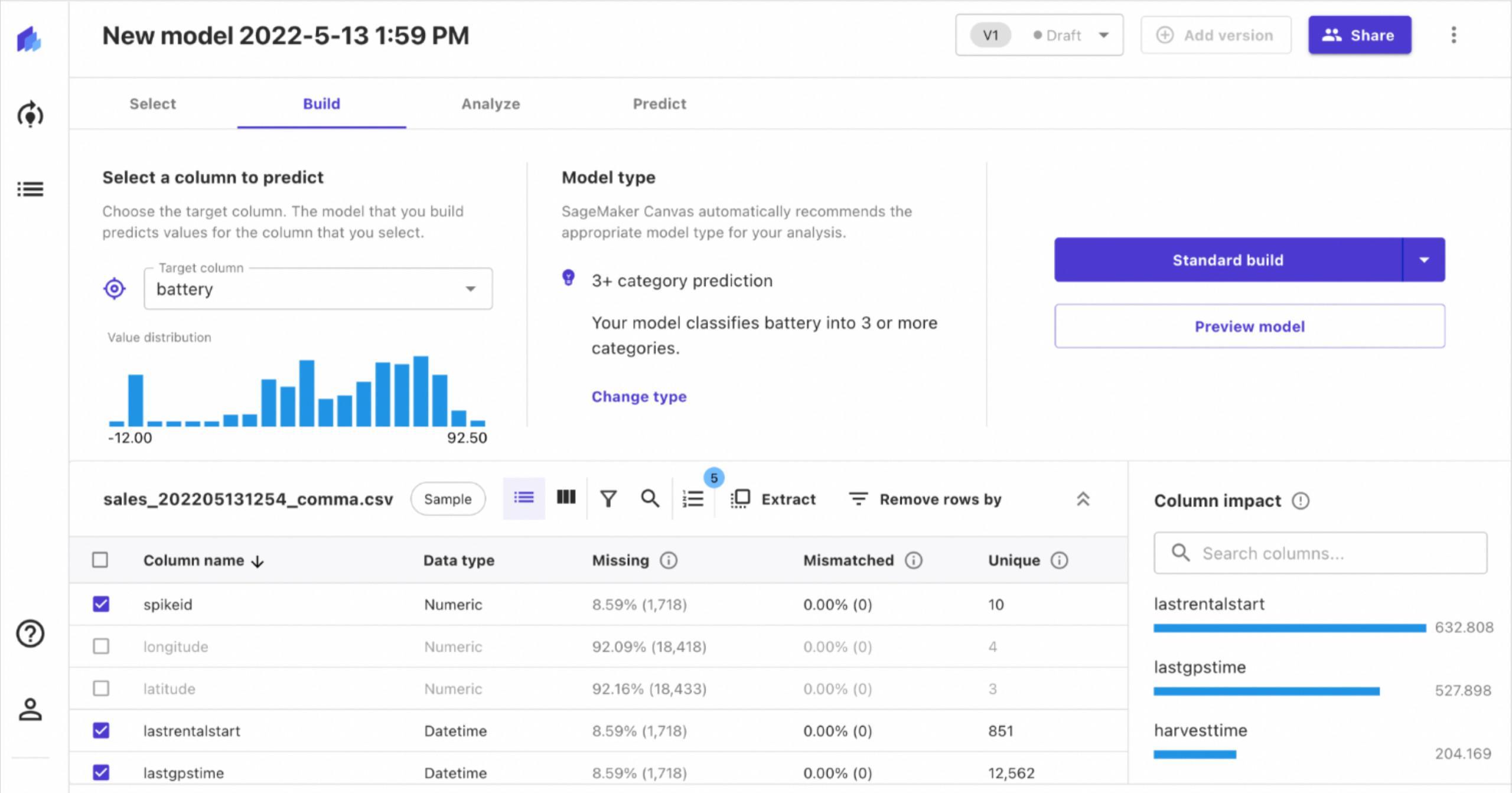
It also shows the impact different features have on the model. Therefore, we can choose to ignore features that have little or no impact.
Once we have selected the features we want to analyse, we select “standard build” and begin building the model. Sagemaker trains the dataset with different models along with multiple hyperparameter values for each model. This is done in order to figure out an optimal solution. As a result, the process of building the model takes a long time.
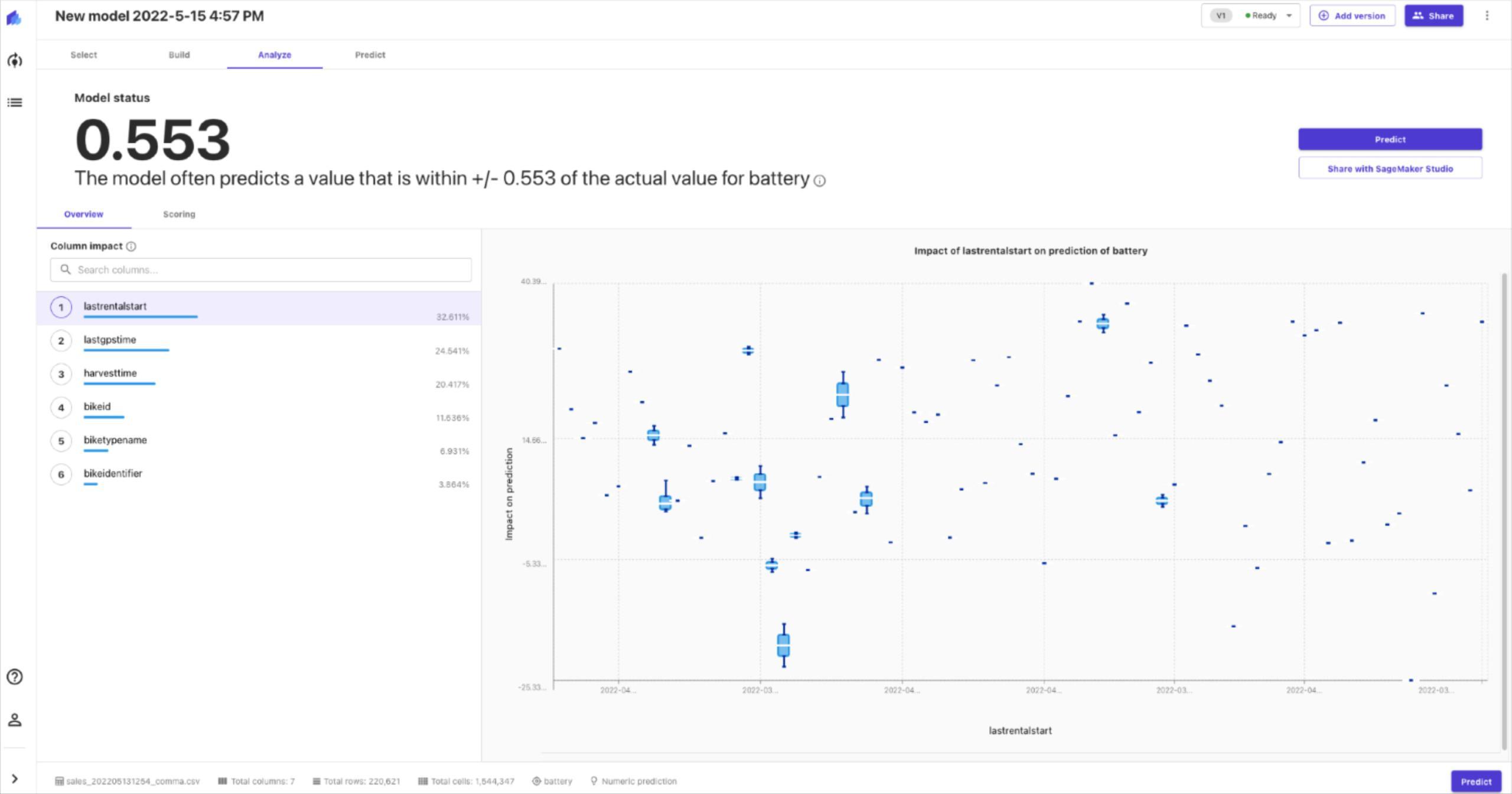
Once the build is complete, you are presented with information about the performance of the model. The model performance can be analysed in further detail with advanced metrics if necessary.
Making predictions
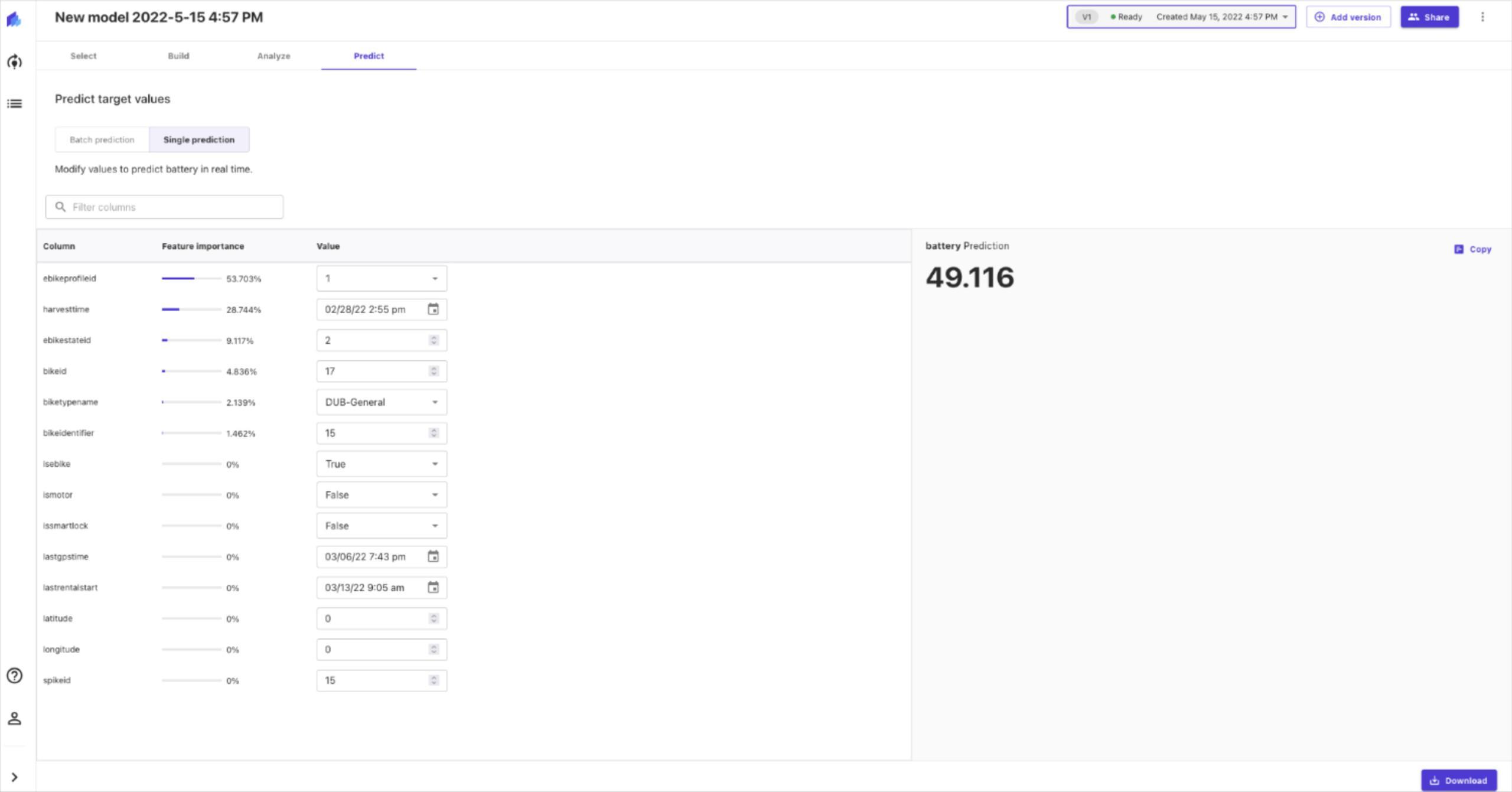
As a final step, we can use the model that was just built to make predictions. We can provide specific values and make a single prediction. We can also provide multiple data in the form of a CSV file and make batch predictions.
If we are satisfied with the model, we can share it to Amazon Sagemaker Studio, for further analysis. Sagemaker Studio is a web-based IDE that can be used for ML development. This is a more advanced ML platform geared towards data scientists to perform complex tasks with Machine Learning models. The model can be deployed and made available through an endpoint. Thereafter, existing systems can use these endpoints to make their predictions.
We will not be going over Sagemaker Studio as it is something that goes beyond AutoML. However, it is important to note that these AutoML cloud platforms are capable of going beyond tabular data. Both Sagemaker and Google AutoML are also capable of working with images, video, as well as text.
Conclusion
While there are many useful applications for AutoML, its simplicity comes with some drawbacks. The main issue that we noticed about AutoML especially with Sagemaker is the lack of flexibility. The platform provides features such as basic filtering, removal, and joining of multiple datasets. However, we could not perform basic derivations such as calculating the distance traveled using the coordinates, or measuring the duration of rentals. All of these should have been simple mathematical derivations based on existing features.
We also noticed issues with flexibility for the classification of battery levels. The ideal approach to this would be to have categories such as “low”, “medium”, and “high”. However, we were not allowed to define these categories or their corresponding threshold values. Instead, the values were chosen by the system automatically.
The main purpose of AutoML is to make Machine Learning available to those who are not experts in the field. As a benefit of this approach, this also becomes useful to people like data scientists. They do not have to spend a large amount of time and effort selecting an optimal model, and hyperparameter tuning.
Experts can make good use of low code AutoML platforms such as Sagemaker to validate any data they have collected. These systems could be utilised as a quick and easy way to produce well-optimised models for new datasets. The models would measure how good the data is. Experts also get an understanding about the type of model and hyperparameters that are best suited for their requirements.