Introduction to Edge AI with HPE Ezmeral Data Fabric
To see what Edge AI is, we need to take a deeper look at the history of data processing over time.
The evolutions of data-intensive workloads
On-premises data centers
Back in 2000, almost everything was running locally in on-premises data centers. This means that everything from management to maintenance was on the company’s shoulders. It was fine but over time, when everything was getting more dependent on the internet, businesses faced some challenges. Here are some of the most important ones:
Infrastructure inflexibility
Over time, many new services and technologies are released and it should be taken into consideration that there might be a need to update the infrastructure or apply some changes to the services.
This can be challenging when it comes to hardware changes. The only solution seems to be purchasing the desirable hardware, then manual configuration. It can be worse if, at some point, we realize that the new changes are not beneficial. In this case, we have to start all over again!
This inflexibility causes wasting money and energy.
How about scaling on demand
A good business invests a lot of money to satisfy its customers. It can be seen from different angles but one of the most important ones always has the capacity to respond to the clients as soon as possible. This rule is also applied to the digital world: even loyal customers might change their minds if they see that the servers are not responding due to reaching their maximum capacity.
Therefore, there should be an estimation of the demand. The challenging part of this estimation is when this demand goes very high on some days during the year and one should forecast it. This demand forecasting has many aspects and it is not limited to the digital traffic from clients to servers. Having a good estimation of the demand for a particular item in the inventory is highly valuable.
Black Friday is a good example of such a situation.
There are two ways to cope with this unusual high demand:
- Purchase extra hardware to ensure that there will be no delay in responding to the customers’ requests. This strategy seems to be safe, but it has some disadvantages. First, since the demand is high on only certain days, many resources are in idle mode for a long time. Second, the manual configuration of the newly purchased devices should be considered. All in all, it is not a wise decision financially.
- Ignore that demand and let customer experience the downtime and wait for servers to become available. As it is easy to guess, it is not good for the reputation of the business.
This inflexibility is hard to address, and it gets worst over time.
Expansion
One might want to expand the business geographically. Along with marketing, there are some technical challenges.
The issue with the geographical expansion is the delay that is caused by the physical distance between the clients and servers. A good strategy is to distribute the data centers around the world and locate them somewhere closer to the customers.
The configuration of these new data centers along with the security, networking, and data management might be very hard.
Cloud Computing
Having the challenges of the on-premises data centers, the first evolution of data-intensive workloads happened around 2010 when third-party cloud providers such as Amazon Web Services and Microsoft Azure were introduced.
They provided companies with the infrastructure/services with the pay-as-you-go approach.
Cloud Computing solved many problems with on-premises approaches.
Risto and Timo have a great blog post about “Cloud Data Transformation” and I recommend checking it out to know more about the advantages of Cloud Computing.
Edge Computing
Over time, more applications have been developed, and Cloud Computing seemed to be the proper solution for them, but around 2020 Edge Computing got more and more attention as the solution for a group of newly-introduced applications that were more challenging.
The common feature of these applications was being time-sensitive. Cloud computing might act poorly in such cases since the data transmission to the cloud is time-consuming itself.
The basic idea of Edge Computing is to process data close to where it is produced. This decentralization has some benefits such as:
Reducing latency
As discussed earlier, the main advantage of Edge Computing is that it reduces the latency by eliminating the data transmission between its source and cloud.
Saving Network Bandwidth
Since the data is being processed in Edge Nodes, the network bandwidth can be saved. This matters a lot when the stream of data needs to be processed.
Privacy-preserving
Another essential advantage of Edge Computing is that the data does not need to leave its source. Therefore, it can be used in some applications where sending data to the cloud/on-perm data centers is not aligned with regulations.
AI applications
Many real-world use cases in the industry were introduced along with the advances in Artificial Intelligence.
There are two options for deploying the models: Cloud-based AI and Edge AI. There is also another categorization for training the model (centralized and decentralized) but it is beyond the scope of this blog.
Cloud-based AI
With this approach, everything happens in the cloud, from data gathering to training and deploying the model.
Cloud-based AI has many advantages, such as being cost-saving. It would be much cheaper to use cloud infrastructure for training a model rather than purchasing the physical GPU-enabled computers.
The workflow of such an application is that after the model is deployed, new unseen data from the business unit (or wherever the source of data is) will be sent to the cloud, the decision will be made there and it will be sent back to the business unit.
Edge AI
As you might have guessed, Edge AI addresses the time-sensitivity issue. This time, the data gathering and training of the model steps still happen in the cloud, but the model will be deployed on the edge nodes. This change in the workflow not only saves the network bandwidth but also reduces the latency.
Edge AI opens the doors to many real-time AI-driven applications in the industry. Here are some examples:
- Autonomous Vehicles
- Traffic Management Systems
- Healthcare systems
- Digital Twins
Data Fabric
So far, we have discussed a bit about the concepts of Cloud/Edge computing, but as always, the story is different in real-world applications.
We talked about the benefits of cloud computing but it is important to ask these questions ourselves:
- What would be the architecture of having such services in the Cloud/Edge?
- What is the process of migration from on-prem to cloud? What are the challenges? How can we solve them?
- How can we manage and access data in a unified manner to avoid data silos?
- How can we orchestrate distributed servers or edge nodes in an optimized and secure way?
- How about monitoring and visualization?
Many companies came up with their own solutions for the above questions with manual work but there is a need for a better way for a business to focus on creating values, rather than dealing with these issues. This is when Data Fabric comes into the game.
Data Fabric is an approach for managing data in an organization. Its architecture consists of a set of services that make accessing data easier regardless of its location (on-prem, cloud, edge). This architecture is flexible, secure, and adaptive.
Data Fabric can reduce the integration time, the maintenance time, and the deployment time.
Next, we will be talking about the HPE Ezmeral Data Fabric (Data Fabric is offered as a solution by many enterprises and the comparison between them is beyond the scope of this blog).
HPE Ezmeral Data Fabric
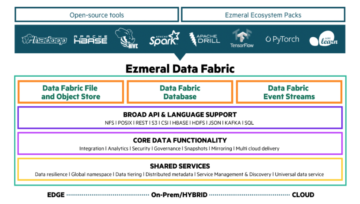
HPE Ezmeral Data Fabric is an Edge to Cloud solution that supports industry-standard APIs such as REST, S3, POSIX, and NFS. It also has an ecosystem package that contains many open-source tools such as Apache Spark and allows you to do data analysis.
You can find more information about the benefits of using HPE Ezmeral Data Fabric here.
As you can see, there is an eye-catching part named “Data Fabric Event Stream”. This is the key feature that allows us to develop Edge AI applications with the HPE Ezmeral Data Fabric.
Edge AI with HPE Ezmeral Data Fabric – application
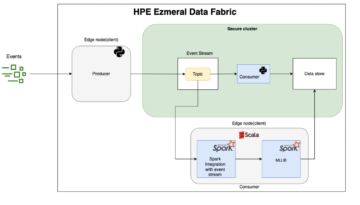
An Edge AI application should contain at least one platform for orchestrating the broker cluster such as Kafka, some tools such as Apache Spark, and a data store. This might not be as easy as it seems, especially in large-scale applications when we have millions of sensors, thousands of edge sites, and the cloud.
Fortunately, with HPE Ezmeral Data Fabric Event Stream, this task can be done much easier. We will go through it by demonstrating a simple application that we developed.
Once you set up the cluster, the only thing you need to do is to install the client on the edge nodes, connect them to the cluster (by a simple line maprlogin command), and then enable the services that you want to use.
For the event stream, it is already there, and again it just needs a single command for creating a stream and then creating topics in it.
For the publisher (also called producer), you need to just send the data from any source to the broker, and for the subscriber (also called consumer) the story is the same.
For using open-source tools such as Apache Spark (or in our case Spark Structure Streaming), you just need to install them on the mapr client, and the connection between the client and the cluster will be automatically established. So you can run a script in edge nodes and access data in the cluster.
Storing data is again as simple as the previous ones. The table creation can be done with a single command, and storing it is also straightforward.
Conclusion
To sum up, Edge AI has a promising future, and leveraging it with different tools such as Data Fabric can be a game changer.
Thank you for reading this blog! I would also like to invite you to our talk about the benefits of Edge Computing in Pori on 23/09/2022!
More information can be found here.
Sadaf Nazari.