Data classification methods for data governance
In the process of data classification, data is initially organized into categories based on type, contents and other metadata. Afterwards, these categories are used to determine the proper level of controls for the confidentiality, integrity, and availability of data based on the risk to the organization. It also implies likely outcomes if the data is compromised, lost or misused, such as the loss of trust or reputational damage.
Though there are multiple ways and labels for classifying company data, the standard way is to use high risk, medium risk and low/no risk levels. Based on specific data governance needs and the data itself, organizations can select their own descriptive labels for these levels. For this blog, I will label the levels confidential (high risk), sensitive (medium risk) and public (low/no risk). The risk levels are always mutually exclusive.
- Confidential (high risk) data is the most critical level of data. If not properly controlled, it can cause the most significant harm to the organization if compromised. Examples: financial records, IP, authentication data
- Sensitive (medium risk) data is intended for internal use only. If medium risk data is breached, the results are not disastrous but not desirable either. Examples: strategy documents, anonymous employee data or financial statements
- Public (low risk or no risk) data does not require any security or access measures. Examples: publicly available information such as contact information, job or position postings or this blog post.
High risk can be divided into confidential and restricted levels. Medium risk is sometimes split into private data and internal data. Because a three-level design may not fit every organization, it is important to remember that the main goal of data classification is to assess a fitting policy level that works with your company or your use case. For example, governments or public organizations with sensitive data may have multiple levels of data classification but for a smaller entity, two or three levels can be enough. Guidelines and recommendations for data classification can be found from standards organizations such as International Standards Organization (ISO 27001) and National Institute of Standards and Technology (NIST SP 800-53).
Besides standards and recommendations, the process of data classification itself should be tangible. AWS (Amazon Web Services) offers a five-step framework for developing company data classification policies. The steps are:
- Establishing a data catalog
- Assessing business critical functions and conduct an impact assessment
- Labeling information
- Handling of assets
- Continuous monitoring
These steps are based on general good practices for data classification. First, a catalog for various data types is established and the data types are grouped based on the organization’s own classification levels.
The security level of data is also determined by its criticality to the business. Each data type should be assessed by its impact. Labeling the information is recommended for quality assurance purposes.
AWS uses services like Amazon SageMaker (SageMaker provides tools for building, training and deploying machine learning models in AWS) and AWS Glue (AWS Glue is an ETL event-driven service that is used for e.g. data identification and categorization) to provide insight and support for data labels. After this step, the data sets are handled according to their security level. Specific security and access controls are provided here. After this, continuous monitoring kicks in. Automation handles monitoring, identifies external threats and maintains normal functions.
Automating the process
The data classification process is fairly complex work and takes a lot of effort. Managing it manually every single time is time-consuming and prone for errors. Automating the classification and identification of data can help control the process and reduce the risk of human error and breach of high risk data. There are plenty of tools available for automating this task. AWS uses Amazon Macie for machine learning based automation. Macie uses machine learning to discover, classify and protect confidential and sensitive data in AWS. Macie recognizes sensitive data and provides dashboards and alerts for visual presentation of how this data is being used and accessed.
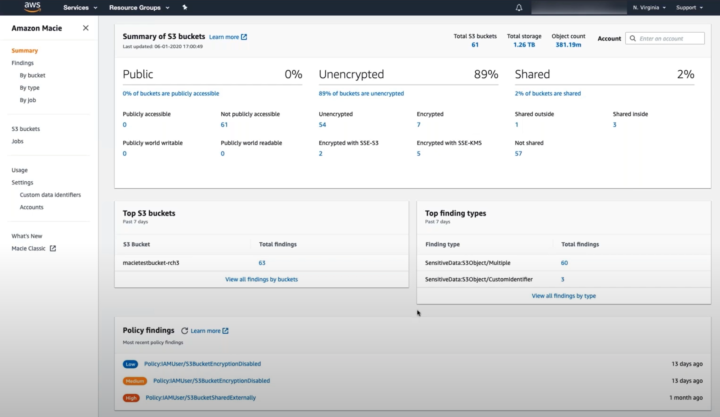
After selecting the S3 buckets the user wants to enable for Macie, different options can be enabled. In addition to the frequency of object checks and filtering objects by tags, the user can use custom data identification. Custom data identifiers are a set of criteria that is defined to detect sensitive data. The user can define regular expressions, keywords and a maximum match distance to target specific data for analysis purposes.
As a case example, Edmunds, a car shopping website, promotes Macie and data classification as an “automated magnifying glass” into critical data that would be difficult to notice otherwise. For Edmunds, the main benefits of Macie are better visibility into business-critical data, identification of shared access credentials and protection of user data.
Though Amazon Macie is useful for AWS and S3 buckets, it is not the only option for automating data classification. A simple Google search offers tens of alternative tools for both small and large scale companies. Data classification is needed almost everywhere and the business benefit is well-recognized.
For more information about this subject, please contact Solita Industrial.