Reading the genomic language of DNA using neural networks
I have been finishing my studies while working at Solita and got the opportunity to do my master’s thesis in the ivves.eu research program in which Solita is participating. The topic of my thesis consisted of language, genomics and neural networks, and this is a story of how they all fit into the same picture.
When I studied Data Science at the University of Helsinki, courses in NLP were my favorites. In NLP, algorithms are taught to read, generate, and understand language, in both written and spoken forms. The task is difficult because of the characteristics of the language: words and sentences can have many interpretations depending on the context. Therefore, the language is far from accurate calculations and rules where the algorithms are good at. Of course, such challenges only make NLP more attractive!
Neural networks
This is where neural networks and deep learning come into play. When a computational network is allowed to process a large amount of text over and over again, the properties of the language will gradually settle into place, forming a language model. A good model seems to “understand” the nuances of language, although the definition of understanding can be argued, well, another time. Anyways, these language models taught with neural networks can be used for a wide variety of NLP problems. One example would be classifying movie reviews as positive or negative based on the content of the text. We will see later how the movie reviews can be used as a metaphor for genes.
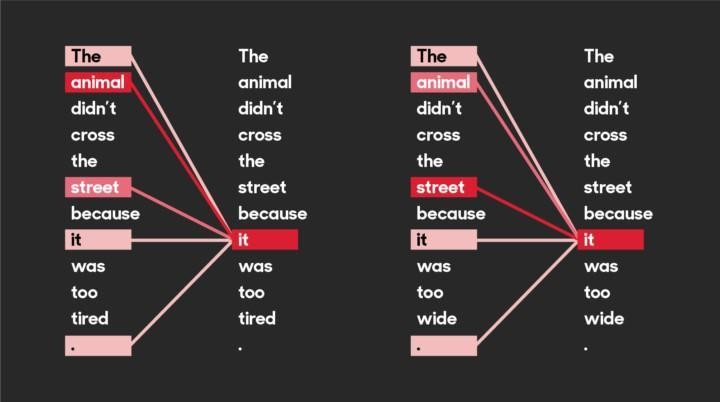
In recent years, a neural network architecture called transformers has been widely used in NLP. It utilizes a method called attention, which is said to pay attention to emphases and connections of the text (see the figure below). This plays a key role in building the linguistic “understanding” for the model. Examples of famous transformers (other than Bumblebee et al.) include Google’s BERT and OpenAI’s GPT-3. Both are language models, but transformers are, well, transformable and can also be used with inputs other than natural language.
DNA-language
And here DNA and genomes come into the picture (also literally in the picture below). You see, DNA has its own grammar, semantics, and other linguistic properties. At its simplest, genes can be thought of as positive movie reviews, and non-coding sequences between genes as negative reviews. However, because the genomes of organisms are part of nature, genes are a little more complex in reality. But this is just one more thing that language and genomics have in common: the rules do not always apply and there is room for interpretation.
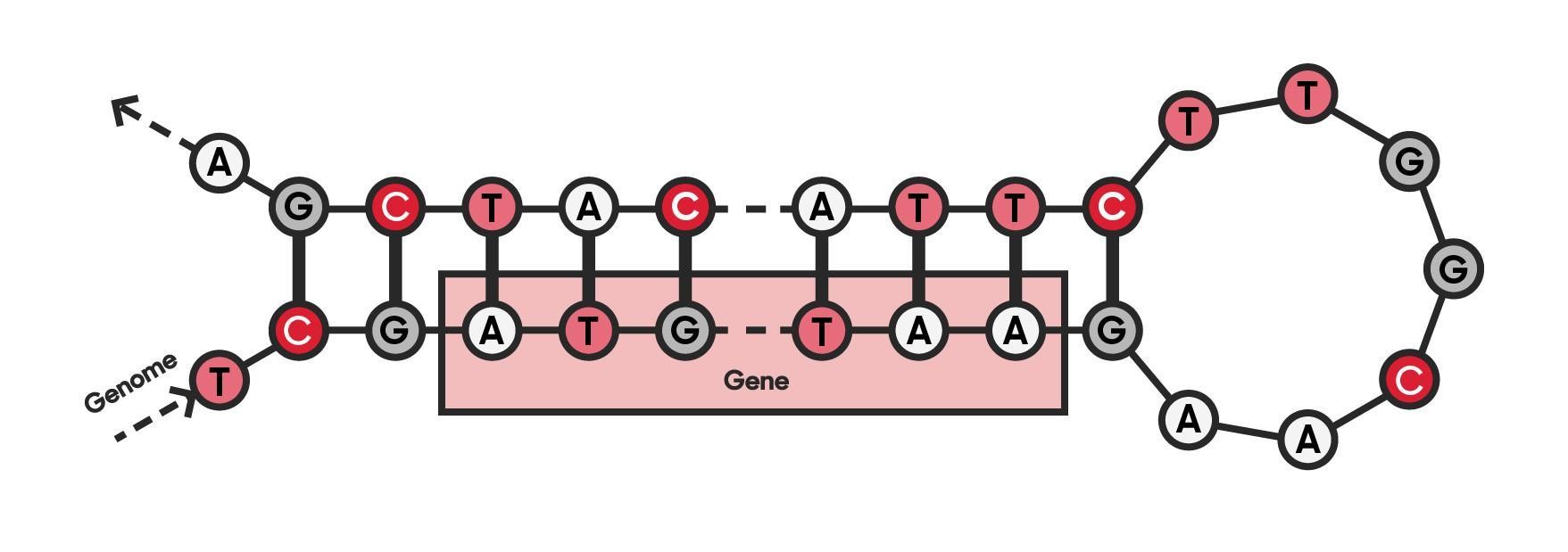
Since both text and genomic data consist of letters, it is relatively straightforward to teach the transformer model with DNA sequences instead of text. Like the classification of movie reviews in an NLP-model, the DNA-model can be taught to identify different parts of the genome, such as genes. In this way, the model gains the understanding of the language of DNA.
In my thesis, I used DNABERT, a transformer model that has been pre-trained with a great amount of genomic data. I did my experiments with one of the most widely known genomes, E. coli bacterium, and fine-tuned the model to predict its gene locations.

After finding the most optimal settings and network parameters, the results clearly showed the potential. Accuracy of 90.15% shows that the model makes “wise” decisions instead of just guessing the locations of the genes. Therefore the method has potential to assist in the basic task of bioinformatics: new genomes are sequenced at a rapid pace, but their annotation is slower and more laborious. Annotated genes are used, for example, to study the causes of diseases and to develop treatments tailored to them.
There are also other methods for finding genes and other markers in DNA sequences, but neural networks have some advantages over more traditional statistics and rule based systems. Rather than human expertise in genomics, the neural network based method relies on the knowledge gathered by the network itself, using a large amount of genomic data. This saves time and expert hours in the implementation of the neural network. The use of the pre-trained general DNA language model is also environmentally friendly. Such a model can be fine-tuned with the task-specific data and settings in just a few iterations, saving computational resources and energy.
There is a lot of potential in further developing the link between transformer networks and DNA to study what else the genome language has to tell us about the life around us. Could this technology contribute to the understanding of genetic traits, the study of evolution, the development of medicine or vaccines? These questions are closely related to the healthcare field, in which Solita has strong expertise, including in research. If you are interested in this type of research, I and other Solita experts will be happy to tell you more!