
Getting started with Azure Purview
Over the last few years, Microsoft has brought several different data solutions to the Azure platform, like Data Factory, Machine learning studio, Synapse, and now Azure Purview.
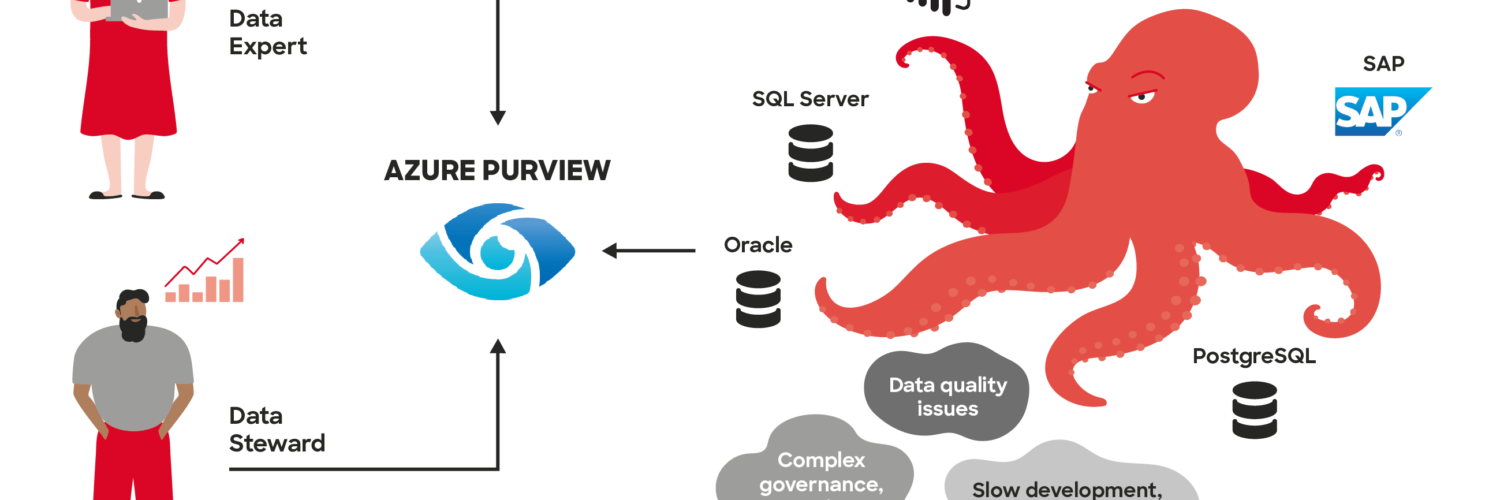
Azure Purview is a unified data governance service that helps you manage and govern your on-premises, multi-cloud, and software-as-a-service (SaaS) data. Easily create a holistic, up-to-date map of your data landscape with automated data discovery, sensitive data classification, and end-to-end data lineage. Empower data consumers to find valuable, trustworthy data. – Microsoft
Why Azure Purview?
What Azure Purview tries to solve is the data discovery and lay down the foundation for data governance. The business point is that everyone wants to know how data is connected between systems and where does the data come from. A very common issue in any organization.
- Centralized place for all the metadata
- Track and visualize data lineages
- Search and find answers about your data
The core problem organizations have is a lack of data ownership. Cataloging data and having a full picture of how different sources are connected, will definitely provide better ownership and transparency. The solution works across on-premises, multi-cloud, and SaaS sources.
Currently, Purview can do three things:
Catalog:
- Source registration, automated scanning, and classification and data discovery.
At the moment there is some limitation on what type of source you can register. The majority of Microsoft products are offered in the selection. There will be custom sources available later, this will grow very fast. (Snowflake, Oracle, Salesforce, etc.)
- Business glossary and lineage and lineage visualization
This area lets you see where the data is coming from and how it is connected with different systems. For example, it is possible to connect Purview with Data Factory and Power BI, so you can see the whole lineage of how data is joined, transformed, and stored in different parts of the pipeline.
Data insights:
- Catalog insights and sensitivity insights
Combining all the metadata that you have and providing analytics and classification. This is defiantly the most interesting part, where you can also label and group different parts of your data into a collection.
Getting started
The service is in preview, so don’t expect much. The ARM template can be found from here, There are not many things you can configure or change. If you want you can use the default parameters and deploy it to Europe west. Hopefully, there will be a similar Git integration like Data Factory has, till then source integrations will be done from the Azure portal.
Now that we have deployed, let’s open up Azure Purview studio from Azure Portal.
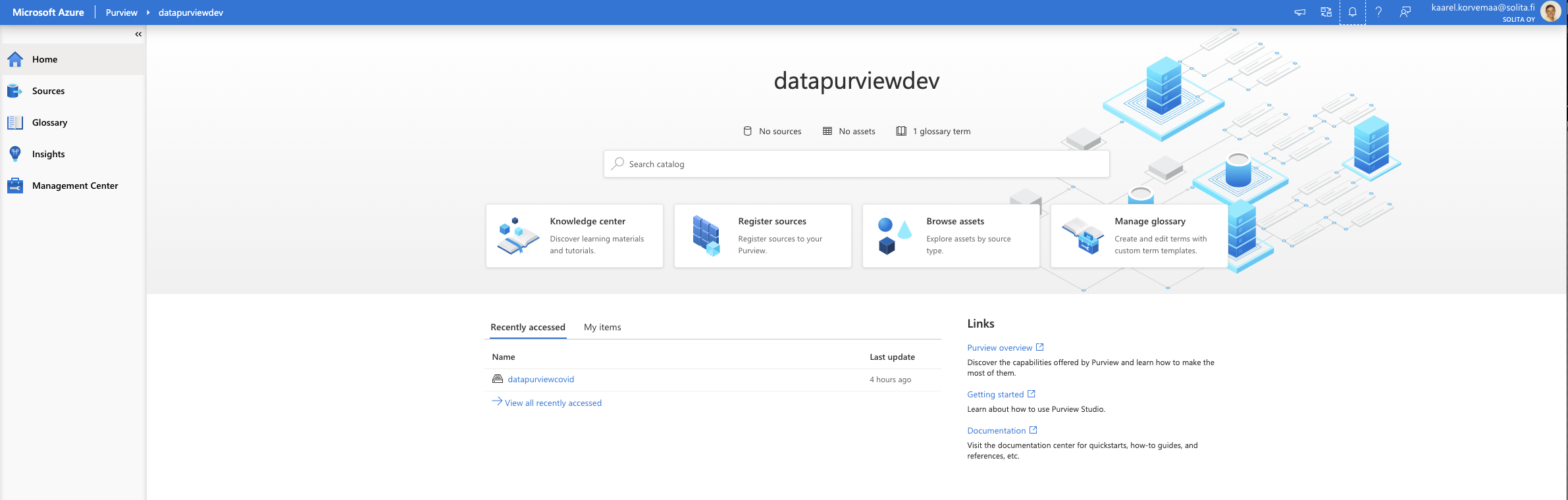
Purview
Dive into the data and let’s see how things work. From the left side choose source, from their registry, from credentials, you can either choose to select a key vault and search for the secrets there, but as we previously did the managed identity we already have rights to access the storage account. The best thing is that you can’t type your passwords or other credentials into the portal, like in Data factory. It forces you to use a key vault. This is the beginning of an end to hardcoded credentials? Maybe, let’s hope so!
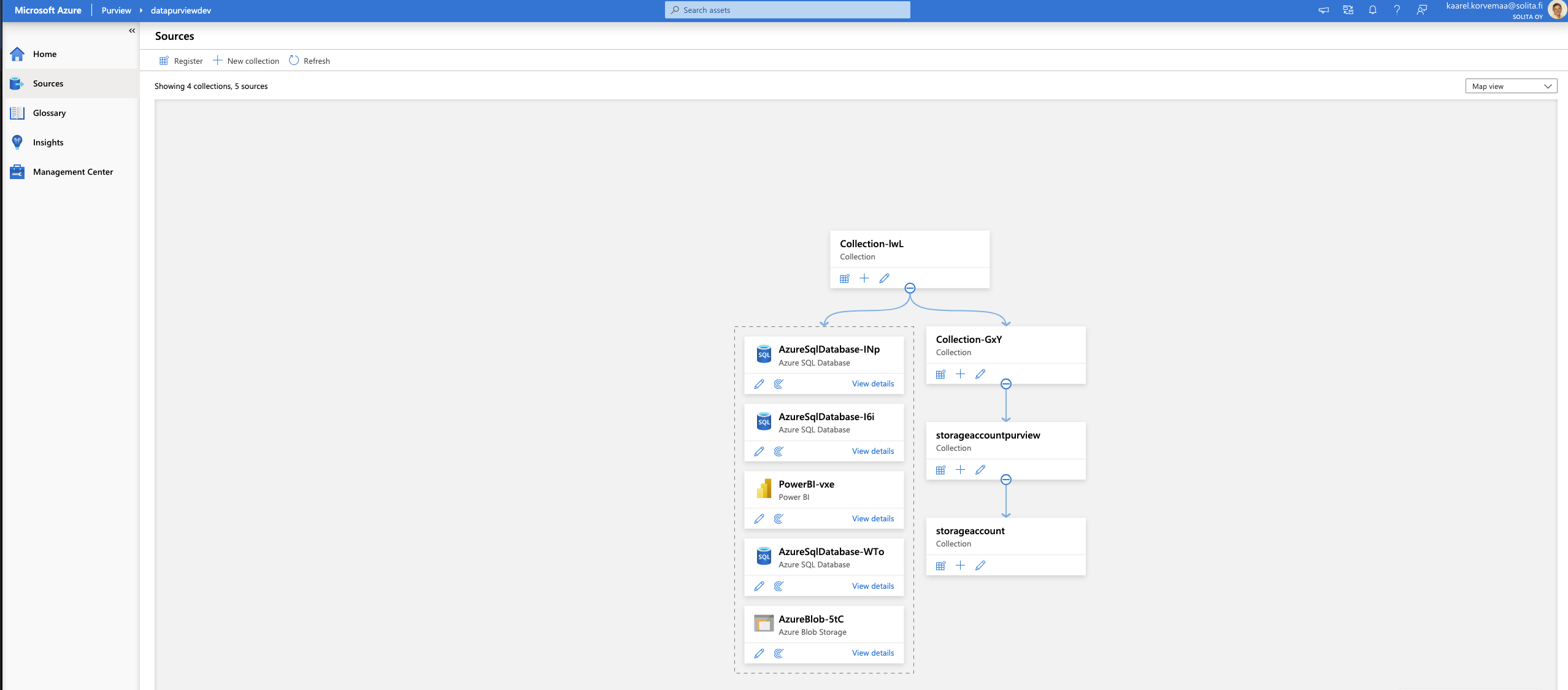
Remember that whatever you choose as a source system, Purview requires a lot of rights. I like to call owner rights as God rights because it can select * from all tables, which is superuser rights.
Scanning
Now it gets interesting, some rules are applied by default. The list is long, so the more boxes you check the longer it will take to run your scan. This will help if you are working with sensitive data and want to make sure that you comply with the regulations. Creating a new rule, allows you to specify what you want to scan and what not.

Remember, this isn’t a live connection. You either do a one time only scan or set a schedule. When running a scan you can do the full scan or incremental, which will search for the changes,
The assumption is that there will be some sort of an event-grid option in the future, where you can trigger scans based on data modifications.
Glossary
This is the place where you create owners for the data. You can add people who have the domain understanding and who are working with the data and how it is connected to different resources. This is the thing you connect with the scanned data. What field relates to what data and what is the definition.
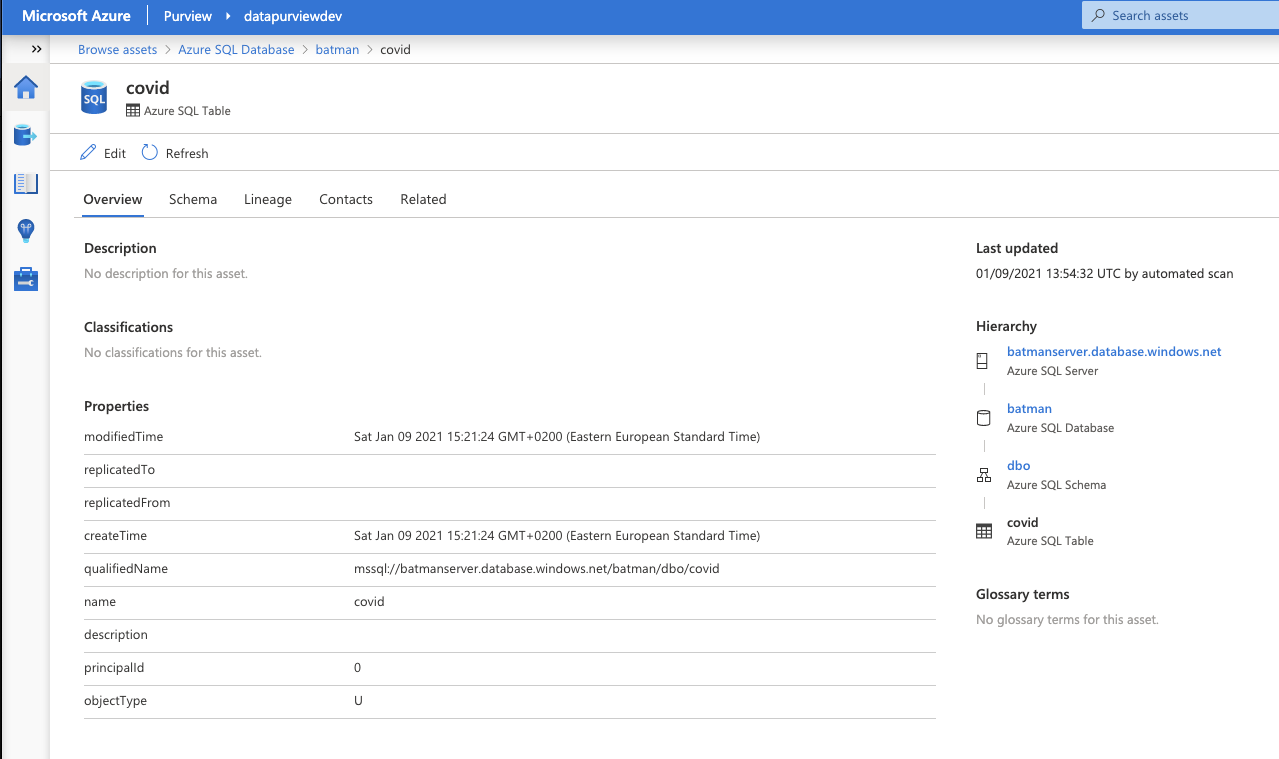
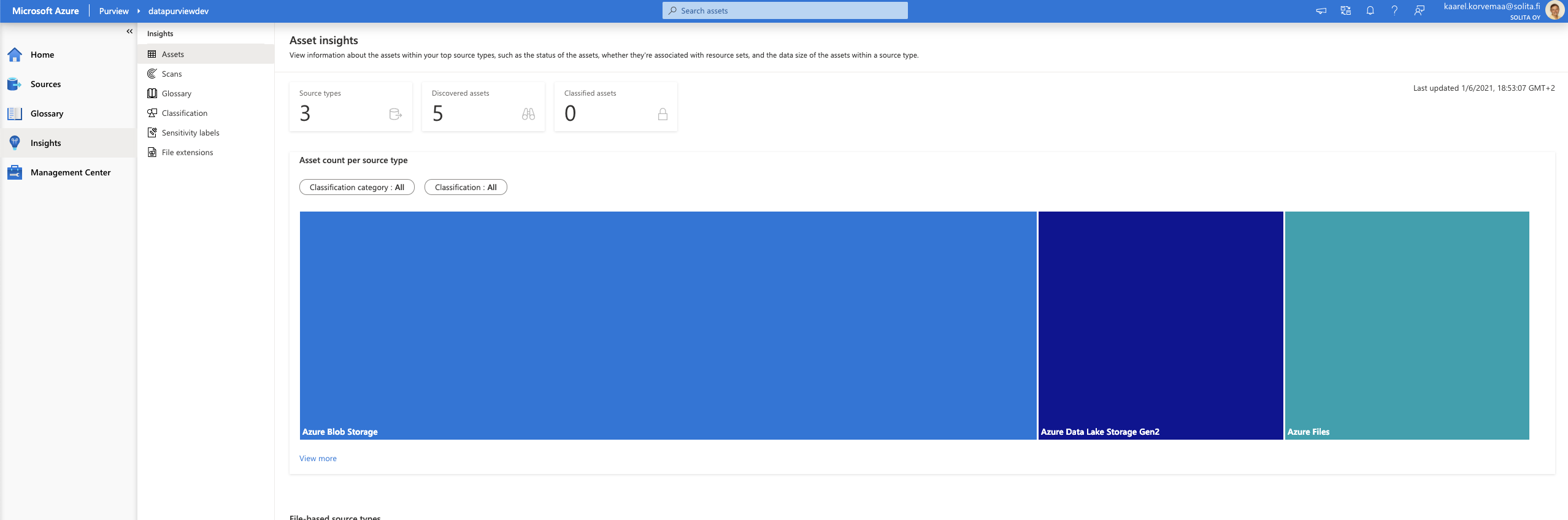
Insights
I used two datasets, one is covid data and another one is credit data. The covid data didn’t automatically give any classifications, but credit data gave. Of course, you can do the classification yourself.
Summary
Considering the amount of data circling in different silos, this will improve data ownership and transparency. At the moment it’s not a production-ready solution but very promising.
Administration level rights that are needed will become a bottleneck for individuals who would like to connect to different sources. Even getting a connection to Power Bi requires Admin level rights.
This needs to be implemented into your data strategy and data governance model. Services like this will need planning, we at Solita have delivered more than +400 different data projects over +20 years. Ping me on Linkedin, more than happy to help your organization out!