Unfolding the work of an Analytics Consultant
All three have had different journeys to become an Analytics Consultant. Tuomas has a business degree and Tero started his career working with telecommunications technology. Johanna however found her way to visualizations quite young: “I created my first IBM Cognos reports as a summer trainee when I was 18 and somehow, I ended up studying Information Systems Science.” It has been, however, love at first sight for all of them. Now they work at Solita’s Data Science and Analytics Cell.
What is a typical Analytics Consultant’s workday like?
The interest in versatile work tasks combines our Analytics Consultants. Tuomas describes himself as “a Power BI Expert”. His days go fast by designing Power BI phases, modelling data, and doing classical pipeline work. “Sometimes I’d say my role has been something between project or service manager.”
Tero in the other hand is focusing on report developing and visualizations. He defines backlogs, develops metadata models, and holds client workshops.
Johanna sees herself as a Data Visualization Specialist, who develops reports for her customers. She creates datasets, and defines report designs and themes. “My work also includes data governance and the occasional maintenance work,” Johanna adds.
All three agree that development work is one of their main tasks. “I could say that a third of my time goes to development,” Tuomas estimates. “In my case I would say even half of my time goes to development,” Tero states.
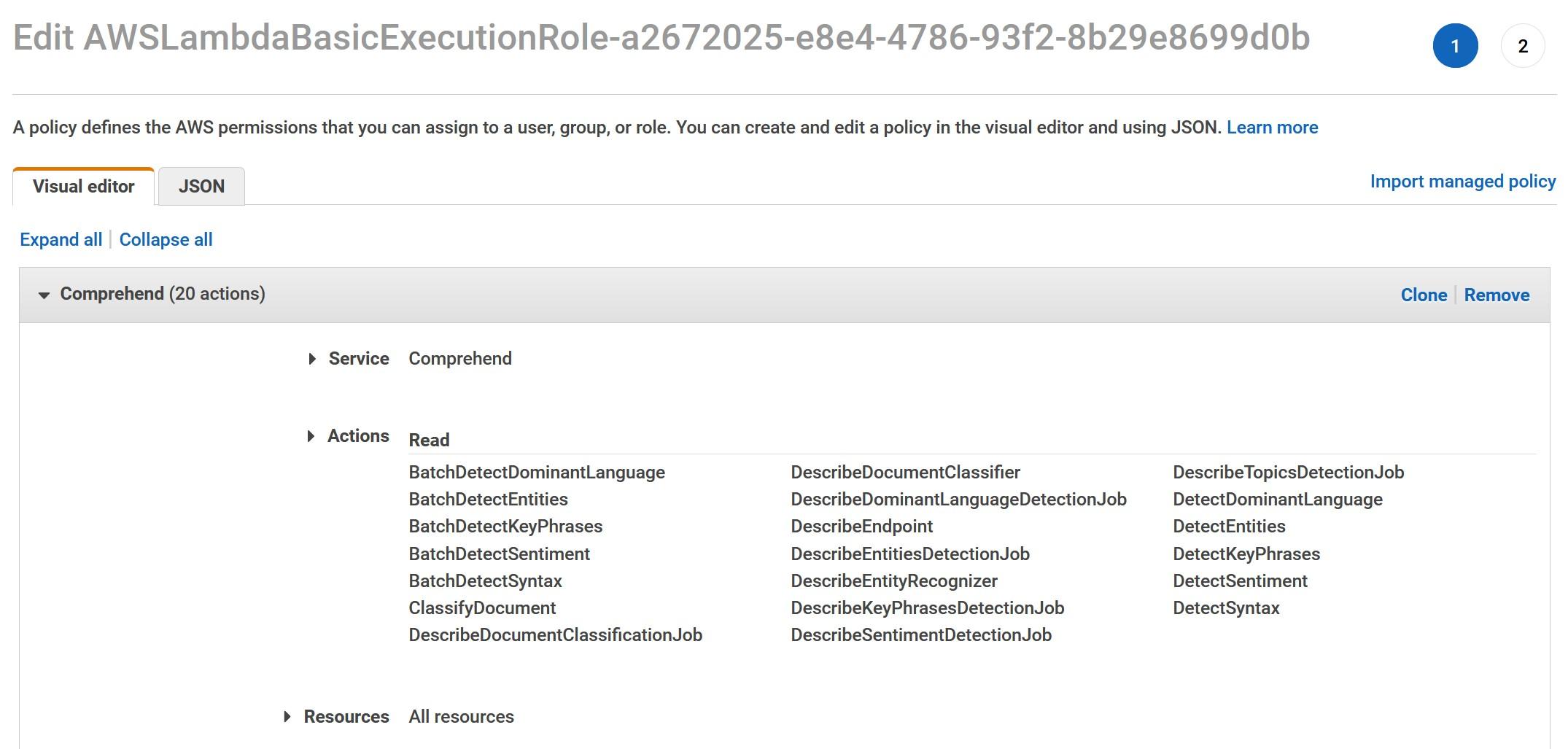
Power BI is the main tool that they are using. Microsoft Azure and Snowflake are also in daily use. Tools vary in projects, so Tuomas highlights that “it is important to understand the nature of different tools even though one would not work straight with them”.
What is the best part of an Analytics Consultant’s work?
The possibility to work with real-life problems and creating concrete solutions brings the most joy to our consultants. “It is really satisfying to provide user experiences, which deliver the necessary information and functionality, which the end users need to solve their business-related questions,” Johanna clarifies her thoughts.
And of course, collaborating with people keeps our consultants going! Tuomas estimates that 35% of his time is dedicated to stakeholder communications: he mentions customer meetings, but also writing documentations, and creating project defining, “specs”, with his customers.
Our consultants agree that communication skills are one of the key soft skills to master when desiring to become an Analytics Consultant! Tuomas tells, that working and communicating with end-users has always felt natural to him.
Tero is intrigued by the possibility of working with different industries: “I will learn how different industries and companies work, what kind of processes they have and how legislation affects them. This work is all about understanding the industry and being customer-oriented.”
“Each workday is different and interesting! I am dealing with many different kinds of customers and business domains every day.”
When asked, what keeps the consultants working with visualizations, they all ponder for a few seconds. “A report, which I create, will provide straight benefit for the users. That is important to me,” Tuomas sums up his thoughts. “Each workday is unique and interesting! I am dealing with many different customers and business domains every day,” Johanna answers. Tero smiles and concludes: “When my customers get excited about my visualization, that is the best feeling!”
How are our Analytics Consultants developing their careers?
After working over 10 years with reporting and visualizations, Tero feels that he has found his home: “This role feels good to me, and it suits my personality well. Of course, I am interested in getting involved with new industries and learning new tools, but now I am really contented!”
Tuomas, who is a newcomer compared to Tero, has a strong urge to learn more: “Next target is to get a deeper and more technical understanding of data engineering tools. I would say there are good opportunities at Solita to find the most suitable path for you.”
Johanna has had different roles in her Solita journey, but she keeps returning to work with visualizations: “I will develop my skills in design, and I would love to learn a new tool too! This role is all about continuous learning and that is an important capability of an Analytics Consultant!”
“I would say there are good opportunities at Solita to find the most suitable path for you.”
How to become an excellent Analytics Consultant? Here are our experts’ tips:
Johanna: “Work together with different stakeholders to produce the best solutions. Do not be afraid to challenge the customer, ask questions or make mistakes.”
Tuomas: “Be curious to try and learn new things. Don’t be afraid to fail. Ask colleagues and remember to challenge customer’s point of view when needed.”
Tero: “Be proactive! From the point of view of technical solutions and data. Customers expect us to bring them innovative ideas!”
Would you like to join our Analytics Consultant team? Check our open positions.
Read our Power BI Experts’ blog post: Power BI Deep Dive


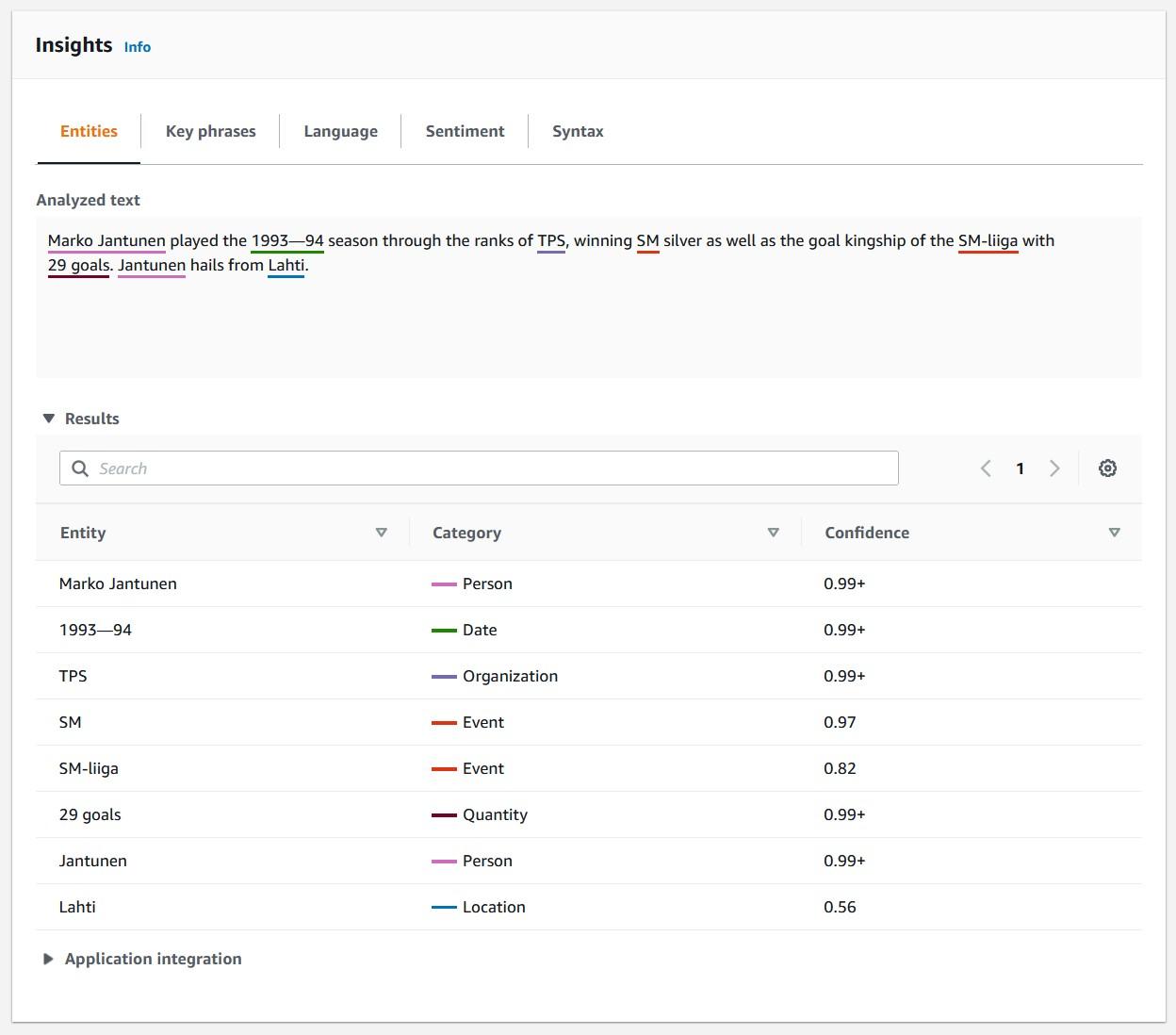

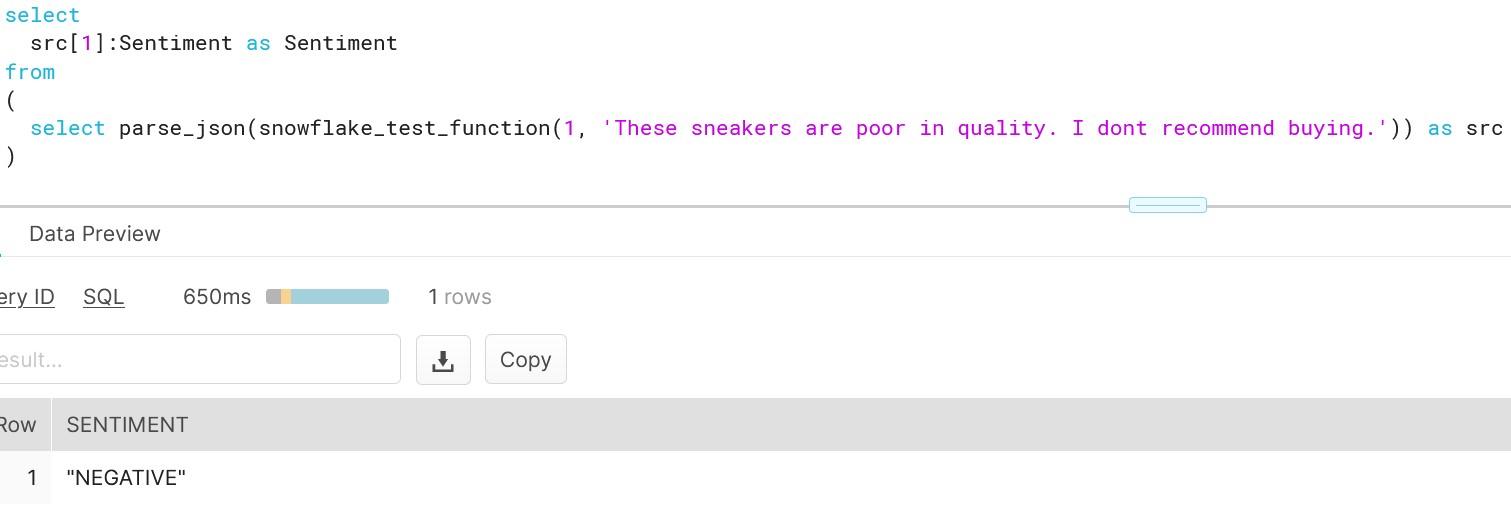
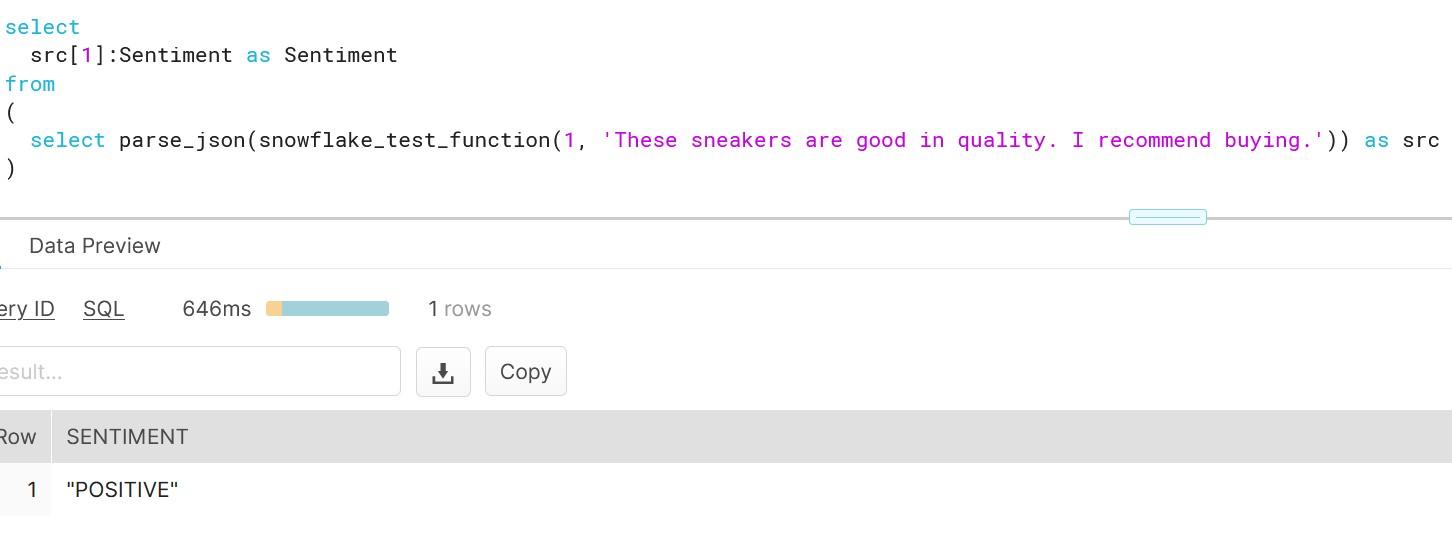
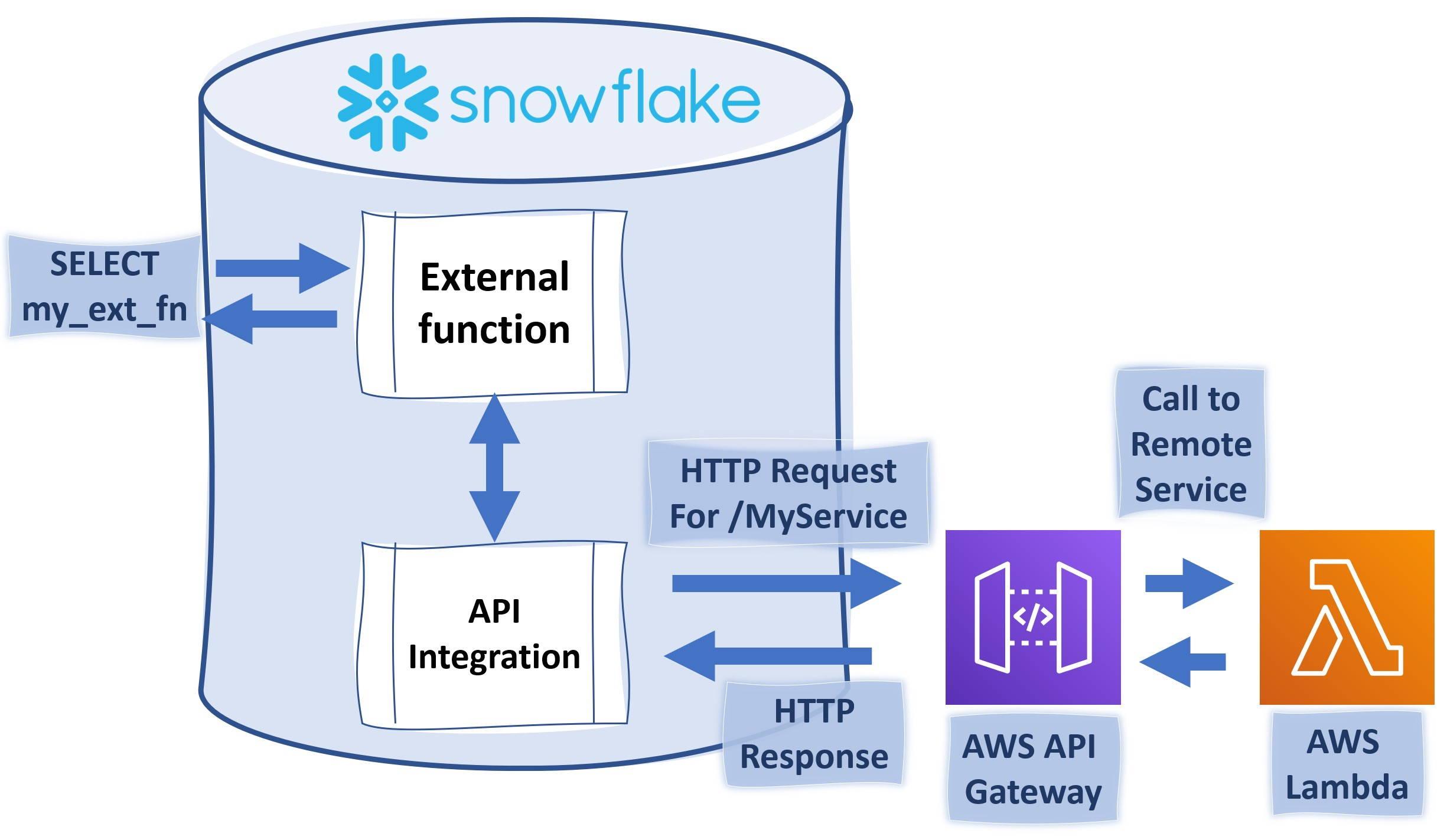
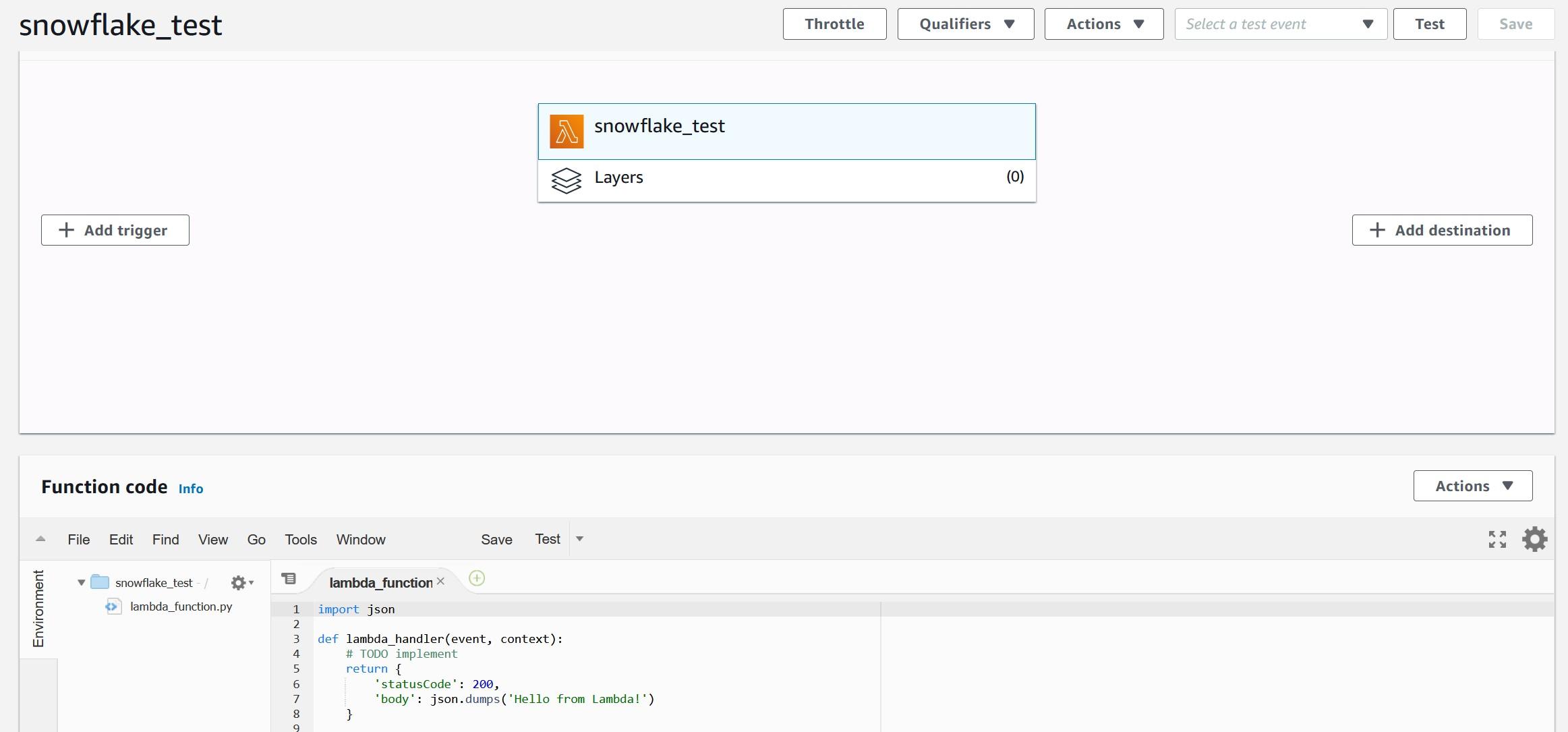
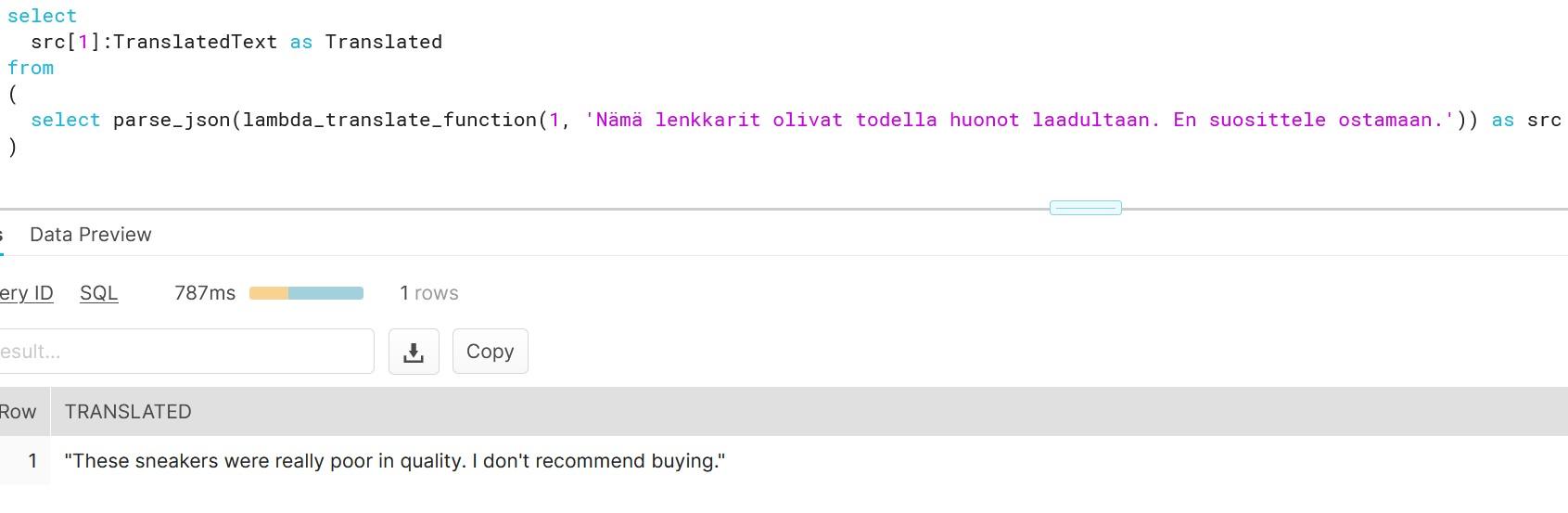 As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
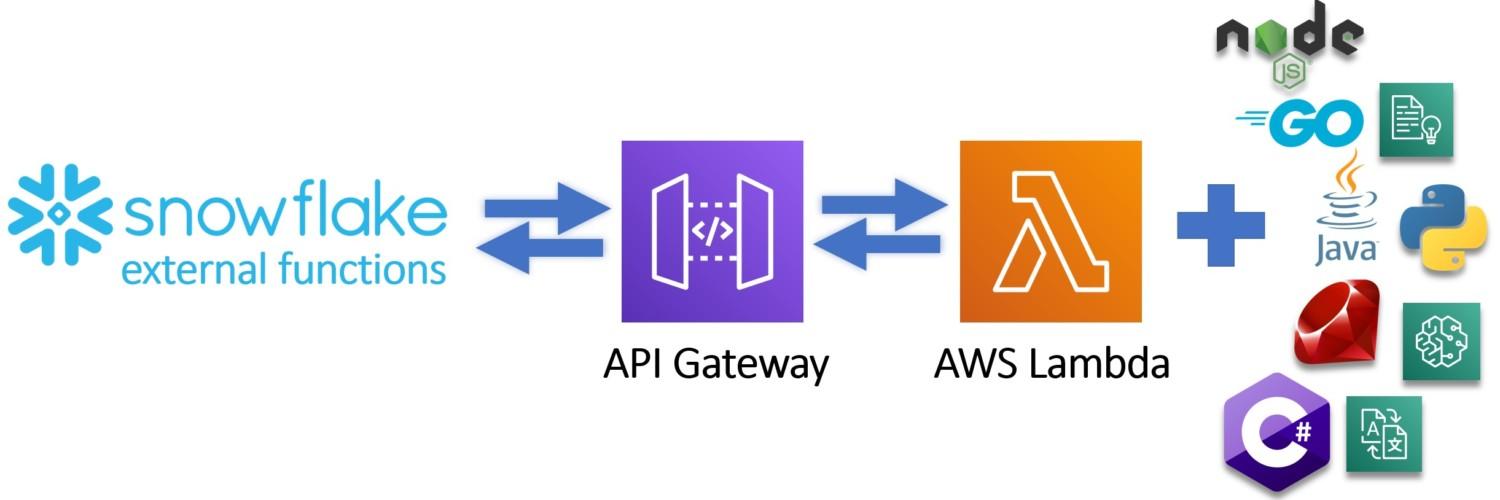




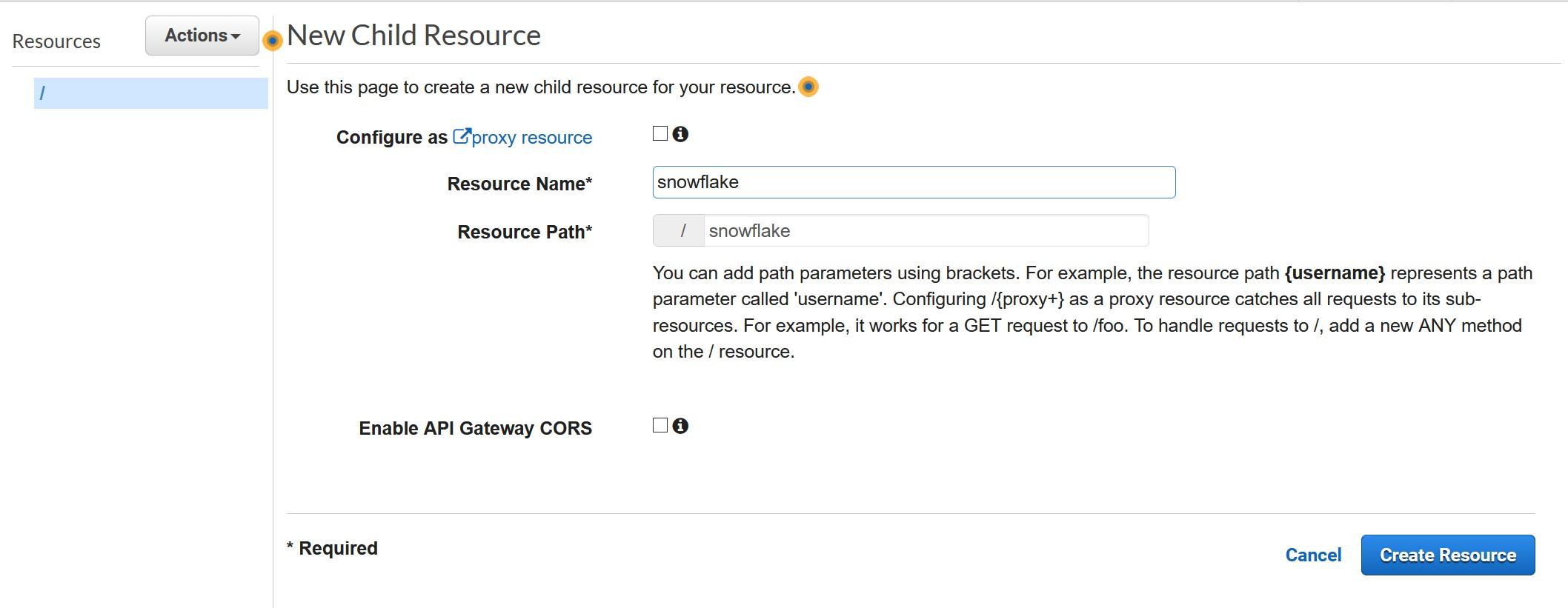
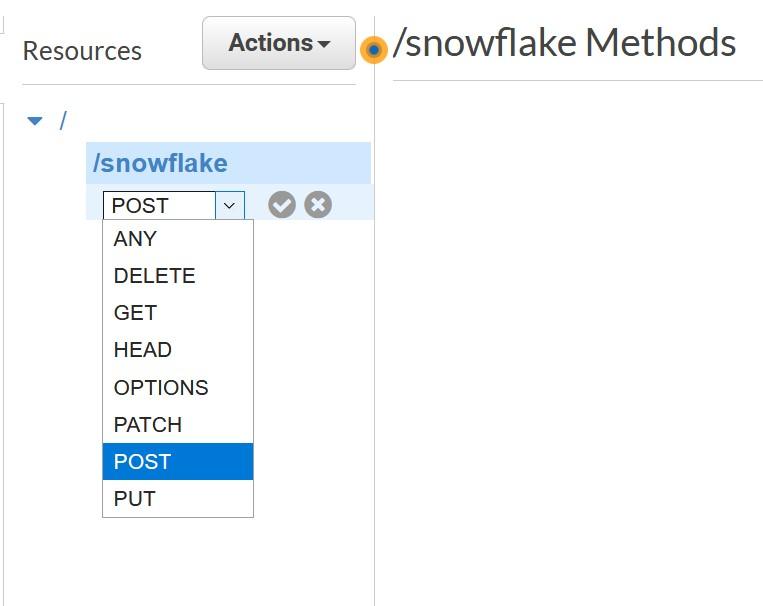
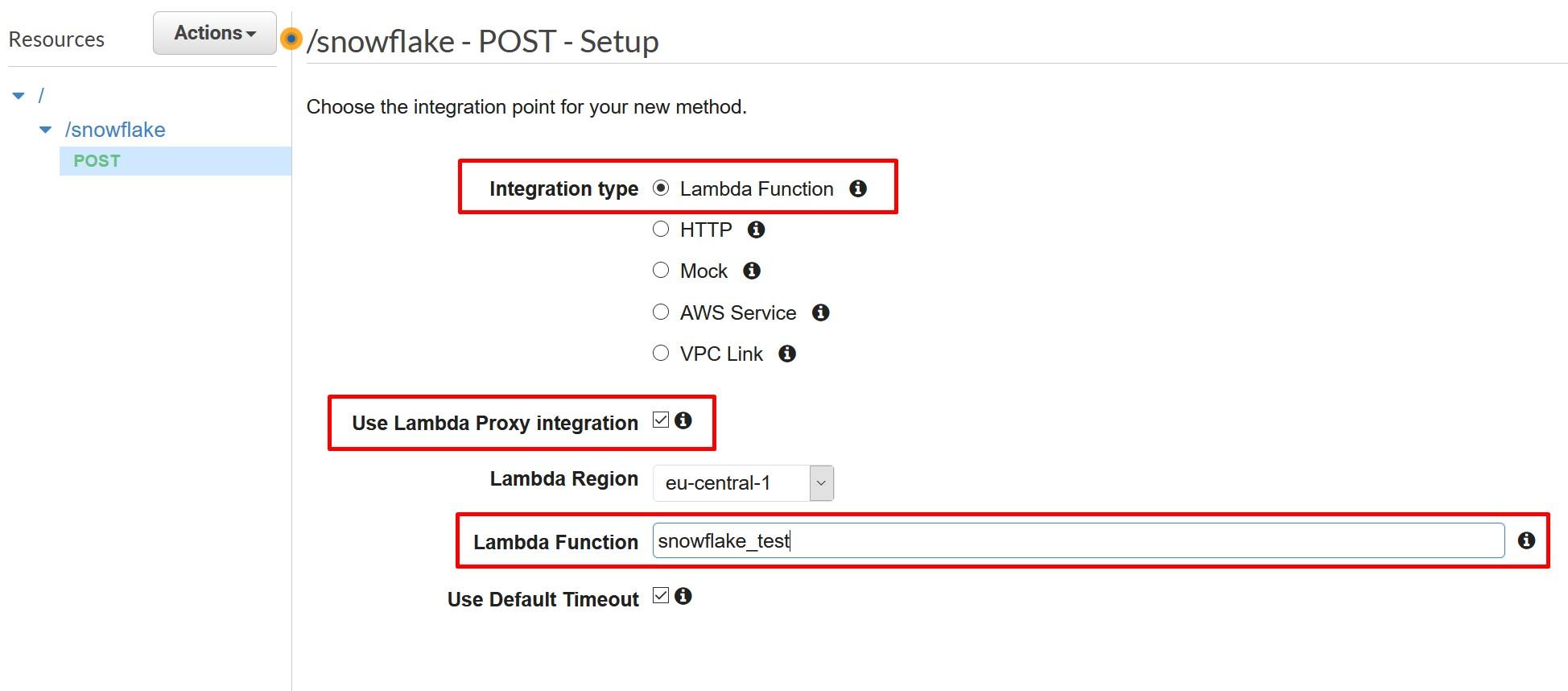
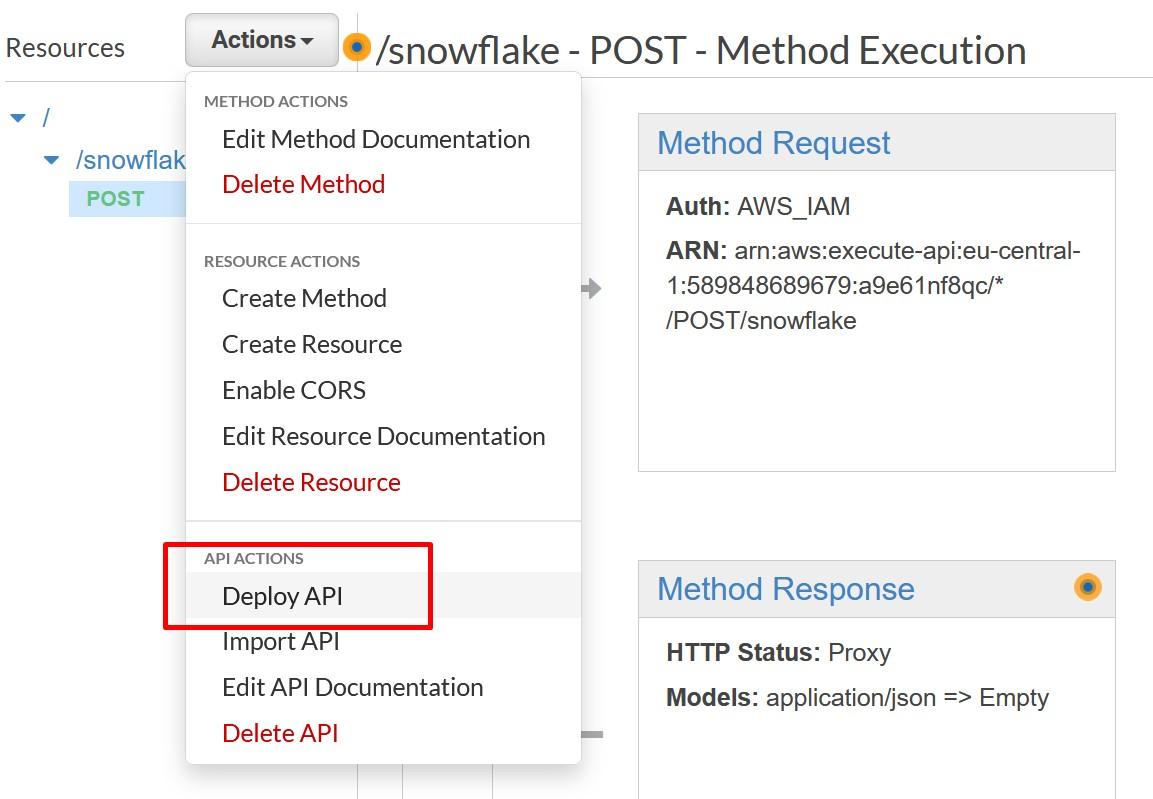
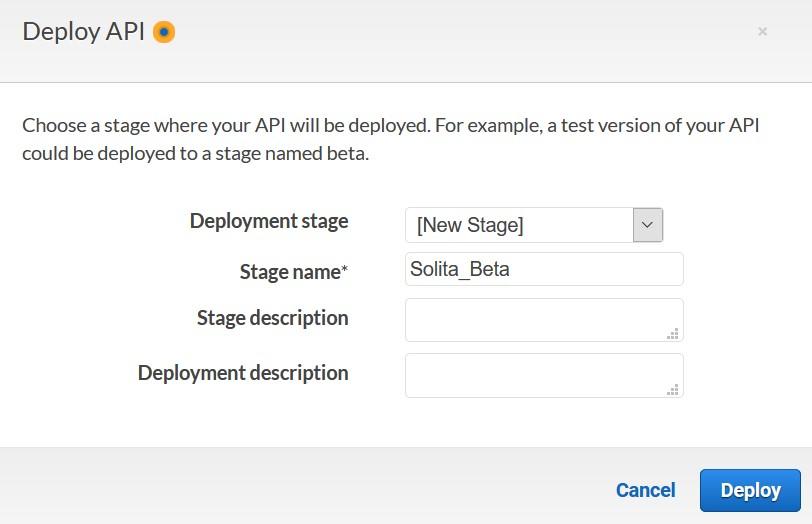
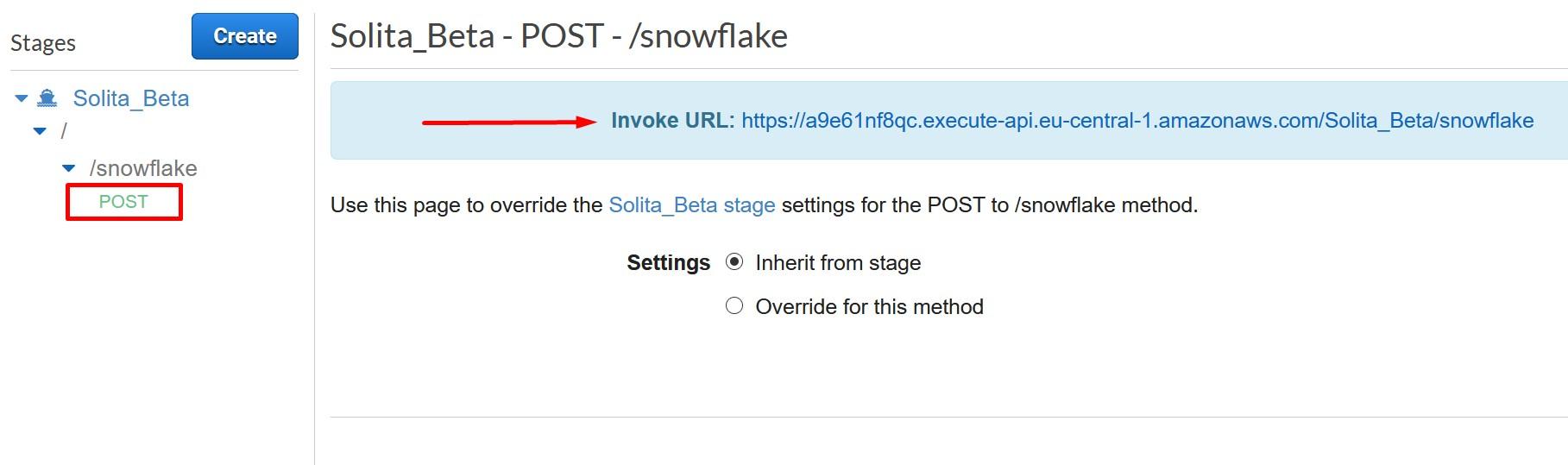
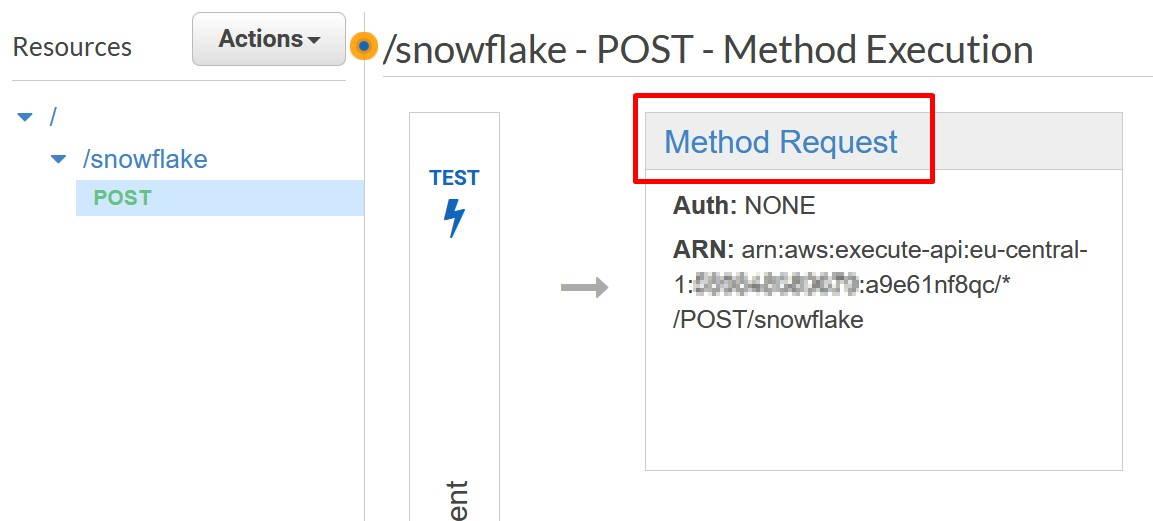
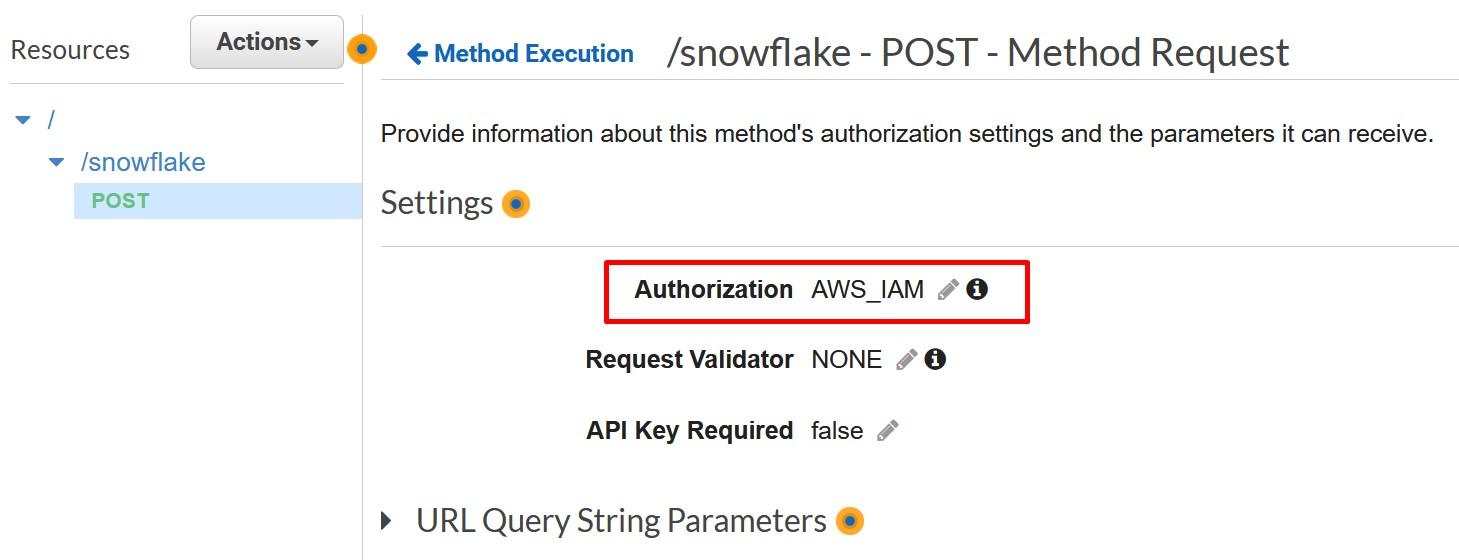
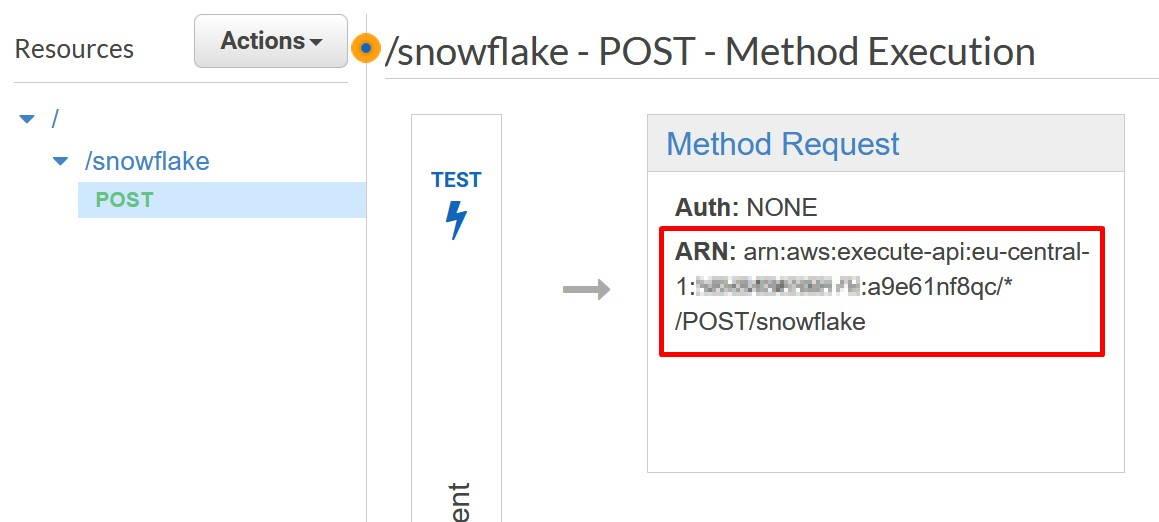
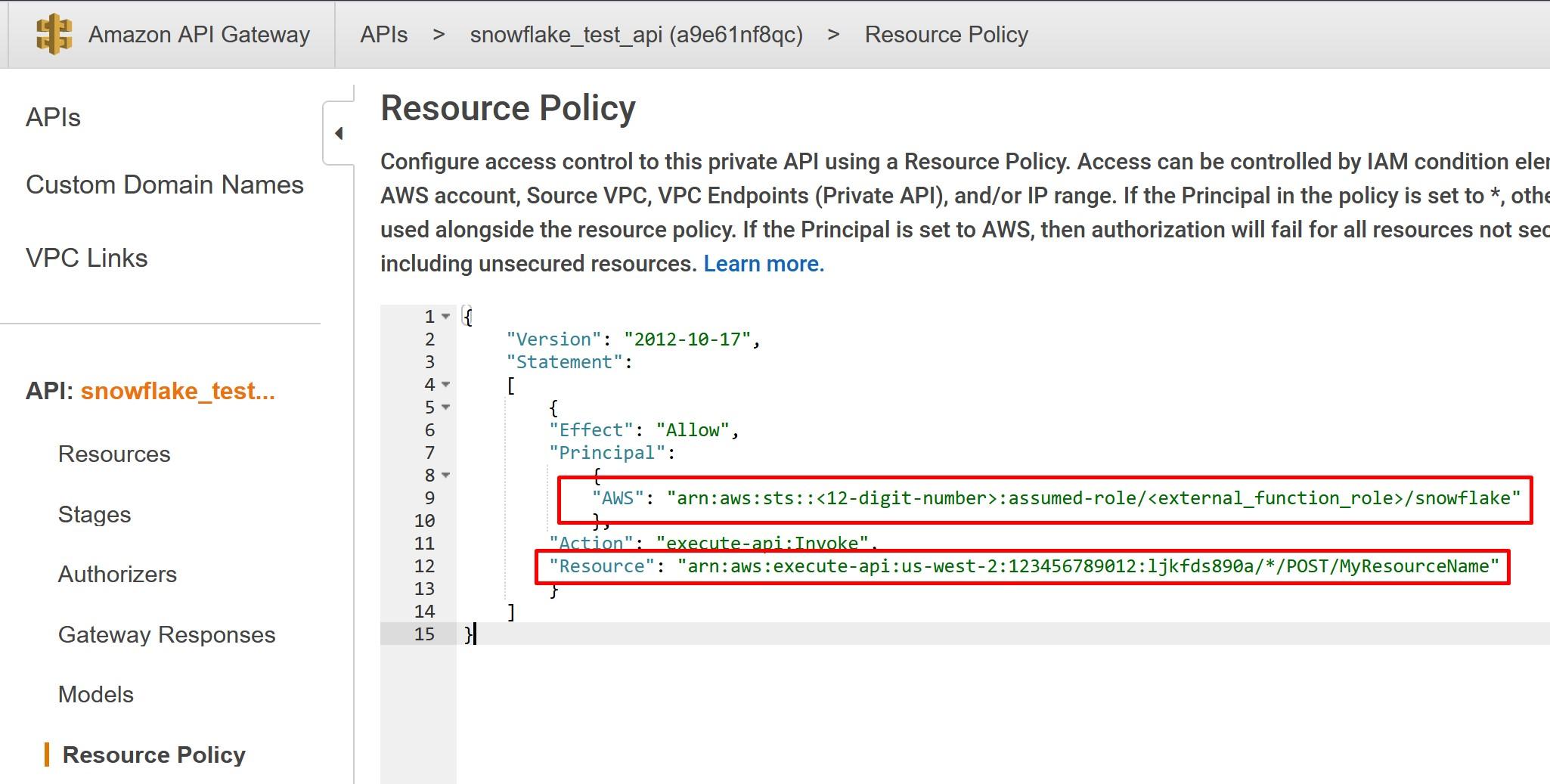

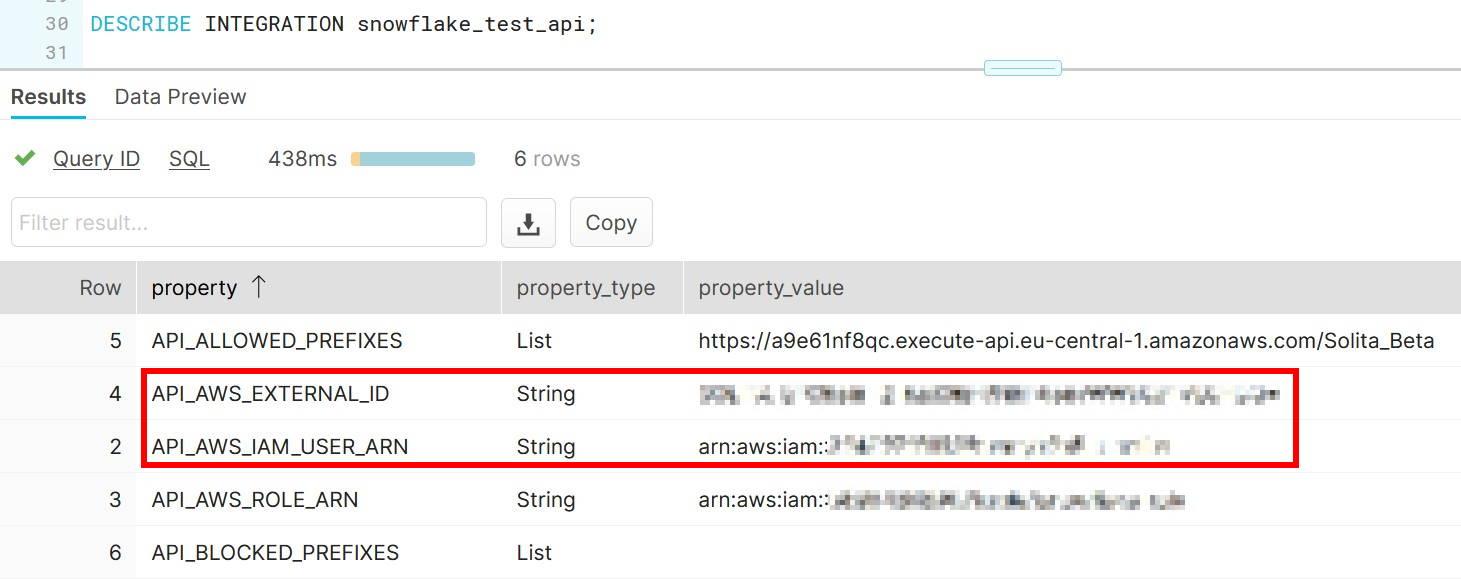
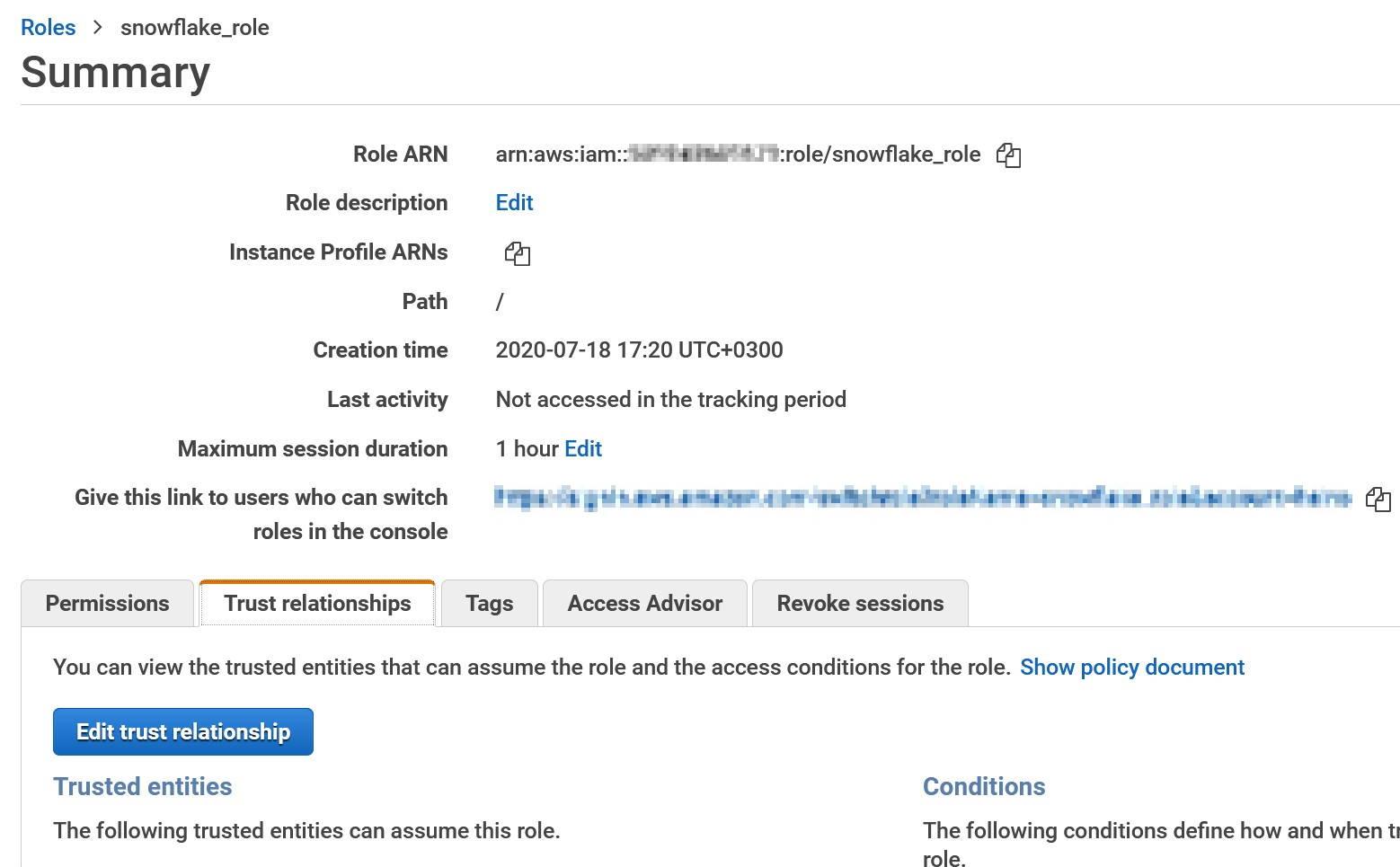
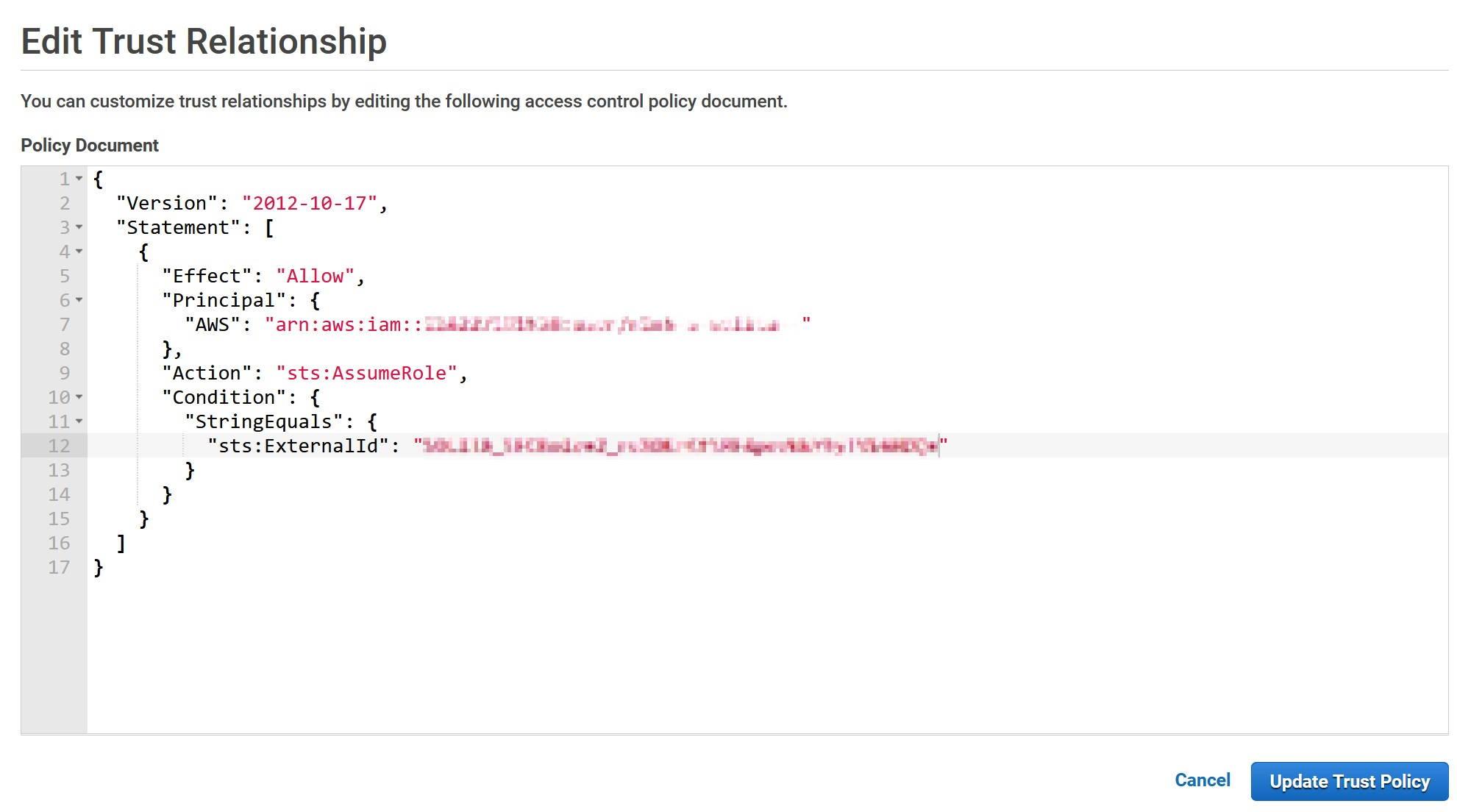

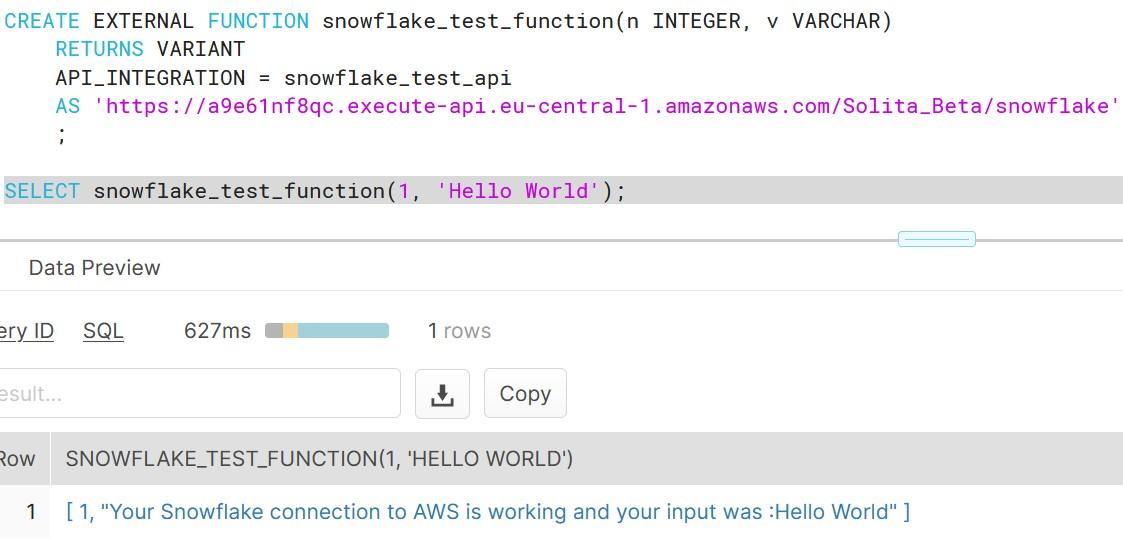


 More information: https://docs.snowflake.com/en/sql-reference/external-functions.html
More information: https://docs.snowflake.com/en/sql-reference/external-functions.html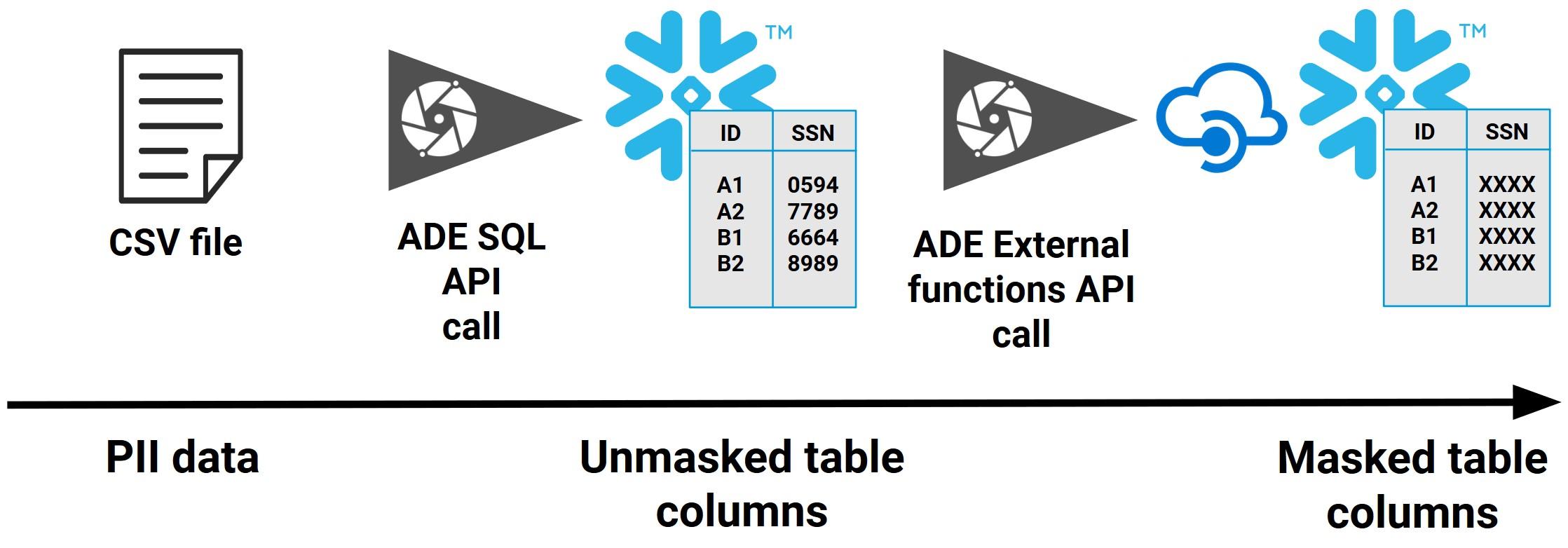






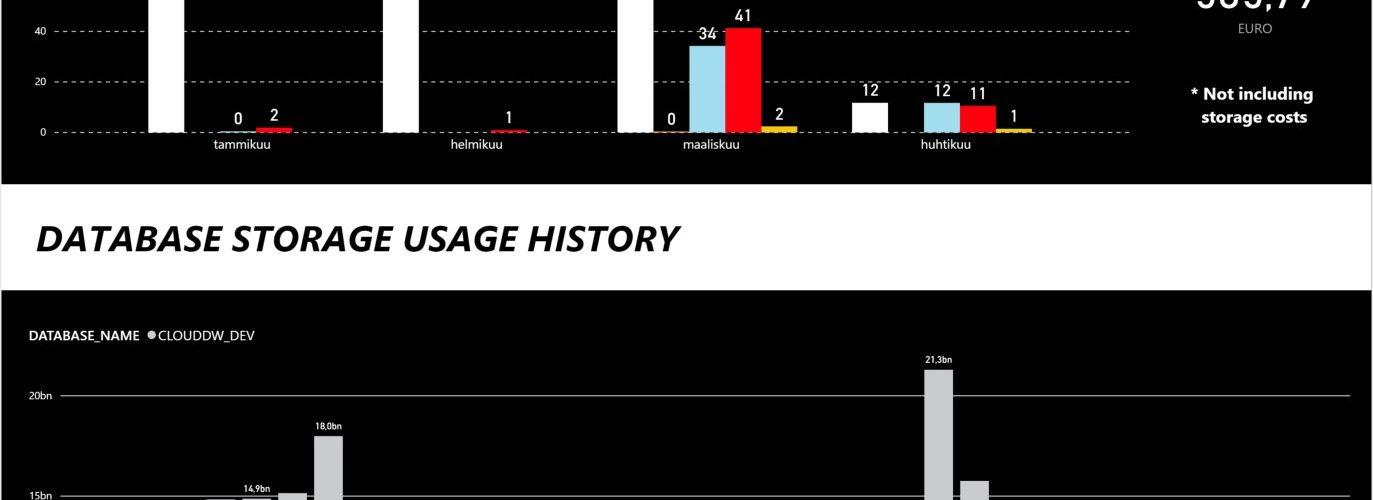

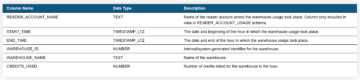
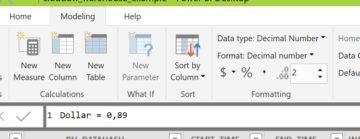
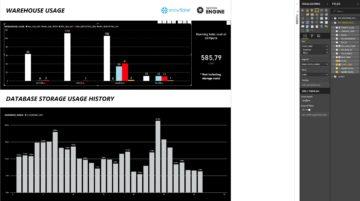
 The cost of warehouses are stored inside WAREHOUSE_METERING_HISTORY -table in CREDITS_USED column, but the Snowflake credits need to be converted into dollars and euro’s and grouped accordingly.
The cost of warehouses are stored inside WAREHOUSE_METERING_HISTORY -table in CREDITS_USED column, but the Snowflake credits need to be converted into dollars and euro’s and grouped accordingly.