AI Act is coming. Is your organisation ready?
The EU regulation on ethical and robust AI solutions called the AI Act is fast approaching. The idea behind this regulation is to enable the development of artificial intelligence while ensuring that human rights are considered and accounted for in the development. The current estimated timeline is to reach an agreement about the content of the AI Act with all member states by the end of this year and have it in effect soon after. The broad strokes of this regulation are already known. My advice for all organisations is to start preparing for this now.
Two ways to prepare for the AI Act
The first thing is to become educated on what this regulation is and make sure everyone in your organisation creating, developing, and deciding on AI projects is also aware of it. This relates to the reasons behind it, the broad strokes of the regulation itself, and how to prepare for it.
The second aspect focuses on preparing the AI solutions in the development pipeline and in production to comply with the regulation as well as also looking at the development culture in the organisation so new AI solutions can be compliant by design. We at Solita have developed a client-tested tool and framework to help with this.
I will also look more closely at both topics next.
Get educated: how we got here and where’s here?
News of companies running into ethical and legal problems with artificial intelligence has made headlines for years with increasing numbers. In 2016 The COMPAS risk assessment recidivism algorithm used by the U.S. court system was assessed to be very biased. Microsoft unveiled the Tay chatbot only to take it offline within 16 hours due to inflammatory and offensive tweets. In 2018 Amazon shut down their recruitment AI for sexist results and in 2019 Apple credit card ran into problems when it offered smaller lines of credit to women than to men.
These and similar issues as well as the rise in popularity of this technology quickly put this topic on the tables of regulators to regulate AI in a way to make it align with legal, ethical, and safety guidelines in the European Union.
The rise in popularity of generative AI, with f.ex. Midjourney and ChatGPT, has required discussions on the content and wording of the AI Act late in this process.
In June 2018 the European Commission established an expert group to create Ethics Guidelines for Trustworthy Artificial Intelligence. The group emphasized three key components for the development of AI. Firstly, AI solutions should be lawful, adhering to existing laws and regulations related to, for instance, product development, data usage, and discrimination. Secondly, AI should be ethical, respecting principles of human autonomy, prevention of harm, fairness, and explicability. Lastly, AI systems should be technically robust, safe, and secure, and consider their social environment. Particular attention should be given to vulnerable and historically disadvantaged groups and situations characterized by power or information imbalances.
In April 2021 the European Commission proposed the first EU regulatory framework for AI. Their priority was to make sure that AI systems used in the EU are safe, fair, transparent, traceable, non-discriminatory, overseen by people, and environmentally friendly. This proposed framework is the basis of the AI Act. Since June 2023, the regulation has transitioned to the phase where EU countries are forming the final wording of the regulation.
General principles of this regulation is that all AI systems are safe, protect privacy, transparent, and non-discriminate, as well as having proper data management.
The plan is to reach an agreement by the end of this year with Generative AI causing plenty of discussions this spring.
The regulation takes a use case-based approach categorizing AI applications into four risk levels, which are low, limited, high and unaccepted risk. Low-risk applications, such as email spam filters and predictive maintenance systems, are not heavily regulated but still encouraged to be robust. Limited risk applications, including chatbots, are subject to transparency obligations. Users must be aware that they are interacting with AI and should have the option to discontinue use while at the same time receiving the service.
Generative AI can be at different risk levels. If used in low-risk application, it needs to be transparent in disclosing AI-generated content for users, prevent the generation of illegal content, and publish summaries of copyrighted data used in training. Currently, the larger foundational models still somewhat lack these aspects as Stanford University discovered earlier this year. The companies providing general-purpose foundational models AIs like GPT have requirements stated if they are to operate within EU.
High-risk applications are such that the system poses a significant risk of harm to the health, safety, or fundamental rights of natural persons or the environment and are subjected to strict obligations throughout their lifecycle. These use cases are defined as AI systems in law enforcement, migration and border control, recommender systems of large online platforms, justice administration and democratic processes, education, employment, essential private and public services, and critical infrastructure. These systems require comprehensive risk assessments and mitigation, data governance practices, transparency and provision of information about it being an AI system. They also require a fundamental rights impact assessment and monitoring environmental impact.
The unaccepted risk and hence prohibited use cases pose clear threats to people’s safety, livelihoods, and rights. Examples include biometric classification of individuals based on sensitive characteristics, real-time remote biometric identification and retrospective identification from recordings, proactive policing activities, emotion recognition systems in f.ex. law enforcement and education, and establishing large-scale facial recognition databases. These will not be allowed within the EU.
Get prepared: finding and fixing potential issues
While education on the regulation is still happening, the review of AI use cases in development and production should take place. This involves all solutions that are being designed, are in development, or are in production. For each, an assessment should be done on their risk level according to the regulation and the priority for business of each solution. This is a fairly simple operation of having current the AI Act guidelines and looking through each use case to which category they are most likely to land in. Legal advice can be sought to offer guidance in cases that could be seen one way or the other. For solutions in production that are already GDPR compliant and not high-risk, the chances are that required chances are small.
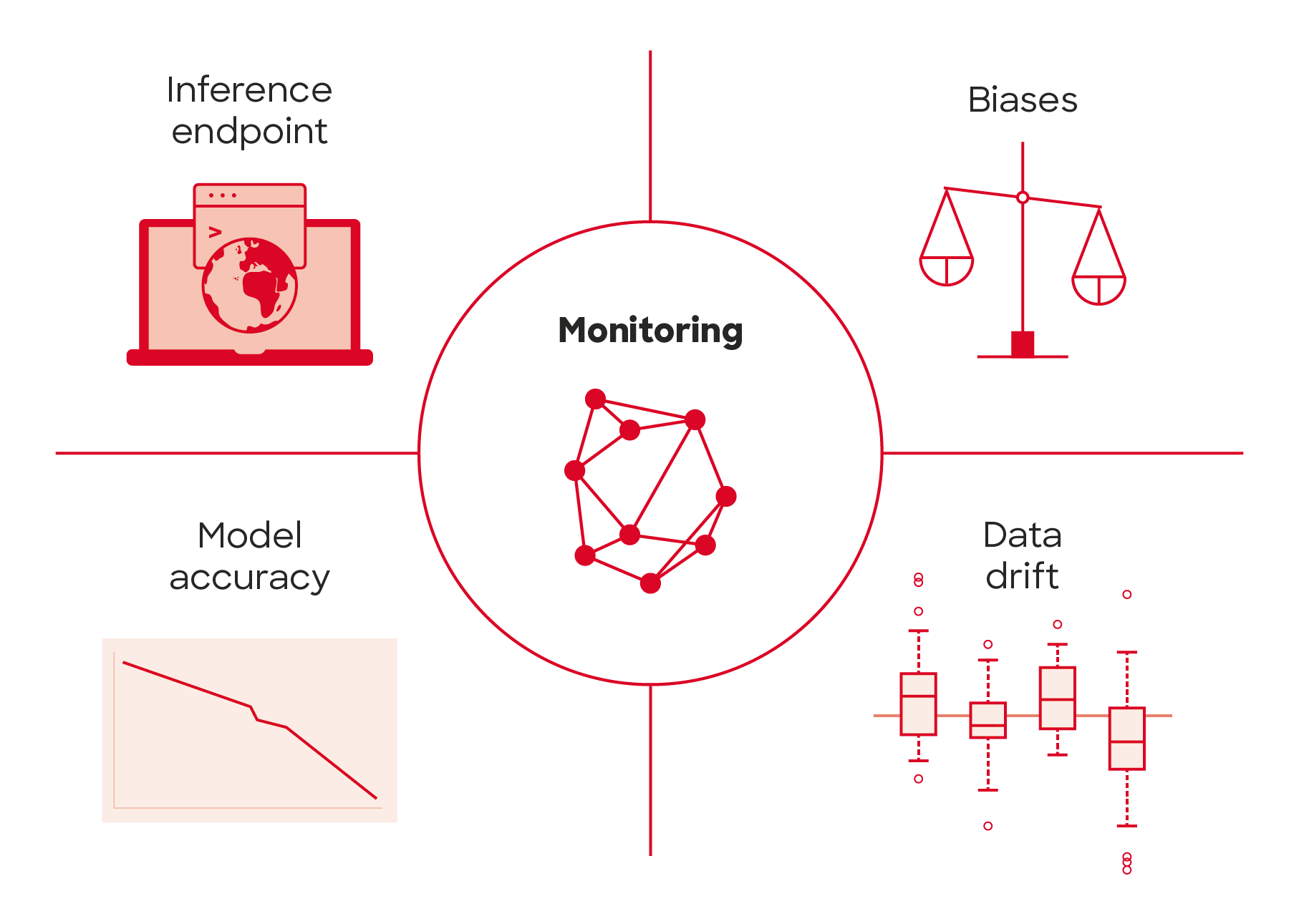
After each solution has been classified to a risk level, the characteristics of each solution need to be investigated regarding the AI Act risk assessment classification. We have developed a customer-tested framework and tool for this at Solita. The list of things to look at is very different in a low-risk application to that of a high-risk application. I recommend starting with the business-critical applications first. The idea here is to foresee possible issues with complying with the regulation and react to them in descending order of priority.
One thing each organisation should consider. If you are using an AI system offered from outside the EU, but used inside the EU, it’s advisable to prepare for some interruption of service. Systems offered outside the EU might not all choose to comply with the regulation but will instead opt out and not offer their services inside the EU, or they might take their service offline while building compliance with the new regulation. The more critical the AI system is to the company, the more important it is to take this into account in time.
Review the development and maintenance pipeline
While reviewing each use case is important, it is important also to start building or strengthening processes that ensure compliance with the regulation now and in the future so AI solutions can be compliant by design. Our framework serves this process well. The tool allows a company to look at their AI development processes, as well as each model, to easily document the current ways of working, identify any issues needing further development, and a way to document progress against identified gaps. We are closely following the development of the regulation and developing the framework accordingly.
Build a roadmap and implement it
Once use cases have been identified and the ways of working assessed, the next phase is to develop a roadmap in order of priority to fix any identified issues before they cause problems. Our framework helps with this. In limited to no-risk use cases it is useful to already start building transparency of an AI model being used and start building opt-out methods if not already present. Also, and especially in high-risk use cases, building a method of redress and obtaining explanations of the decisions made by the AI system, is very important.
For any use case that can be considered high risk, a more thorough investigation should be already started that documents carefully the system and its development and provides users and affected parties with the necessary information on the solution. The Solita framework makes this process easier. For the forbidden use cases, if they exist, it is necessary to think about the end of life of these solutions.
Act now
The AI Act is coming, and it is coming soon. I recommend starting to prepare for it now, and, if necessary, seek out ML engineers, responsible AI experts, and designers with thorough knowledge and understanding of this topic area to help to educate staff and build a roadmap for compliance with each AI solution in the development pipeline or in production. When the regulation comes into effect, I suspect many organizations will wake up to the need to do something as they did when GDPR came into effect and consultancies capable of helping them will be fully booked quickly. As the main parts of this regulation are already well known, my advice is to start preparing for this now. We’re always happy to help with client-tested tools to do so.
Oh, by the way, the Data Act, AI liability act, and Cyber Resiliency Act are coming too. Luckily, we’re looking at those too when we build our tools and frameworks.