Neural networks are powerful tools in natural language processing (NLP). In addition, they can also learn the language of DNA and help in genome annotation. Annotated genes, in turn, play a key role in finding the causes and developing treatments for many diseases.
I have been finishing my studies while working at Solita and got the opportunity to do my master’s thesis in the ivves.eu research program in which Solita is participating. The topic of my thesis consisted of language, genomics and neural networks, and this is a story of how they all fit into the same picture.
When I studied Data Science at the University of Helsinki, courses in NLP were my favorites. In NLP, algorithms are taught to read, generate, and understand language, in both written and spoken forms. The task is difficult because of the characteristics of the language: words and sentences can have many interpretations depending on the context. Therefore, the language is far from accurate calculations and rules where the algorithms are good at. Of course, such challenges only make NLP more attractive!
Neural networks
This is where neural networks and deep learning come into play. When a computational network is allowed to process a large amount of text over and over again, the properties of the language will gradually settle into place, forming a language model. A good model seems to “understand” the nuances of language, although the definition of understanding can be argued, well, another time. Anyways, these language models taught with neural networks can be used for a wide variety of NLP problems. One example would be classifying movie reviews as positive or negative based on the content of the text. We will see later how the movie reviews can be used as a metaphor for genes.
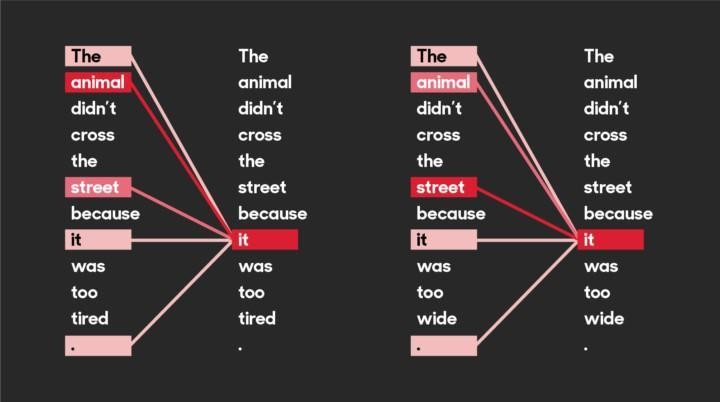
In recent years, a neural network architecture called transformers has been widely used in NLP. It utilizes a method called attention, which is said to pay attention to emphases and connections of the text (see the figure below). This plays a key role in building the linguistic “understanding” for the model. Examples of famous transformers (other than Bumblebee et al.) include Google’s BERT and OpenAI’s GPT-3. Both are language models, but transformers are, well, transformable and can also be used with inputs other than natural language.
An example of how transformers self-attention “sees” the connections in a sentence. The difference of the last word completely changes what the word “it” most refers to.
DNA-language
And here DNA and genomes come into the picture (also literally in the picture below). You see, DNA has its own grammar, semantics, and other linguistic properties. At its simplest, genes can be thought of as positive movie reviews, and non-coding sequences between genes as negative reviews. However, because the genomes of organisms are part of nature, genes are a little more complex in reality. But this is just one more thing that language and genomics have in common: the rules do not always apply and there is room for interpretation.
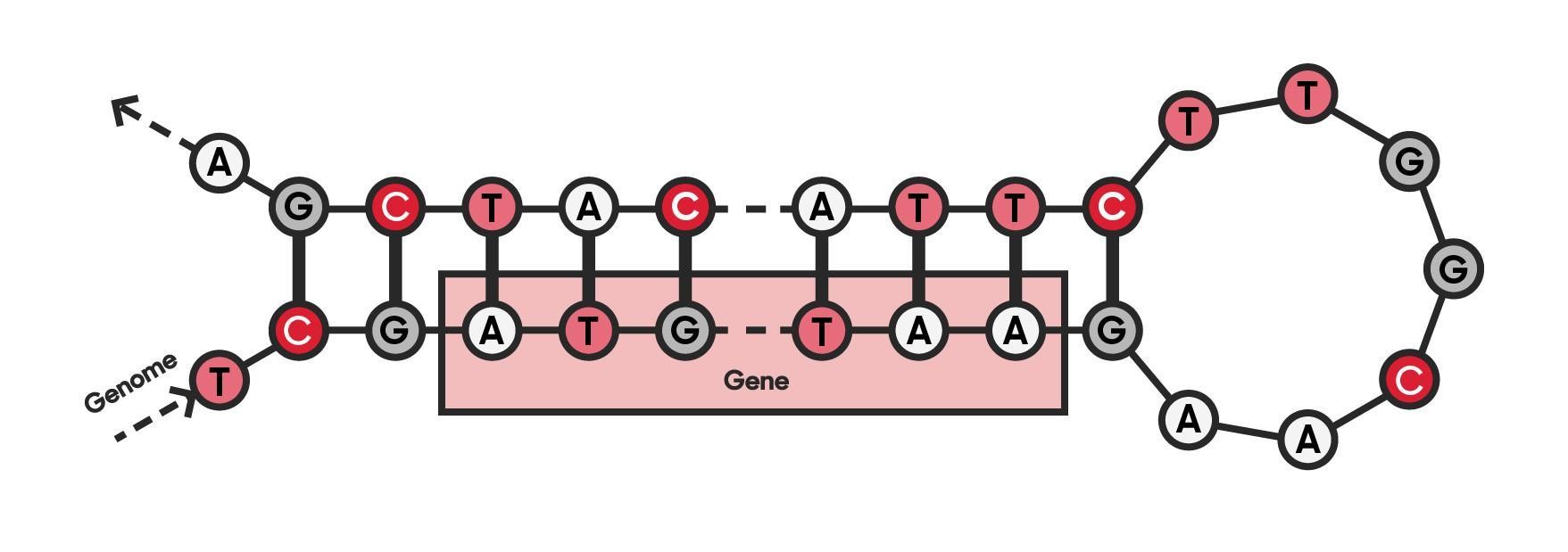
Simplification of a genome and a gene. Genomic data is a long sequence of characters A, T, C, and G representing four nucleotide types. Genes are coding parts of the genome. At their simplest, they consist of start and end points and the characters between them.
Since both text and genomic data consist of letters, it is relatively straightforward to teach the transformer model with DNA sequences instead of text. Like the classification of movie reviews in an NLP-model, the DNA-model can be taught to identify different parts of the genome, such as genes. In this way, the model gains the understanding of the language of DNA.
In my thesis, I used DNABERT, a transformer model that has been pre-trained with a great amount of genomic data. I did my experiments with one of the most widely known genomes, E. coli bacterium, and fine-tuned the model to predict its gene locations.
Example of my experiments: the Receiver operating characteristic (ROC) curves helped me to find the most optimal input length for the genome data. Around 100 characters led to the highest curve and thus the best results, whilst 10 was obviously too short and 500 too long.
After finding the most optimal settings and network parameters, the results clearly showed the potential. Accuracy of 90.15% shows that the model makes “wise” decisions instead of just guessing the locations of the genes. Therefore the method has potential to assist in the basic task of bioinformatics: new genomes are sequenced at a rapid pace, but their annotation is slower and more laborious. Annotated genes are used, for example, to study the causes of diseases and to develop treatments tailored to them.
There are also other methods for finding genes and other markers in DNA sequences, but neural networks have some advantages over more traditional statistics and rule based systems. Rather than human expertise in genomics, the neural network based method relies on the knowledge gathered by the network itself, using a large amount of genomic data. This saves time and expert hours in the implementation of the neural network. The use of the pre-trained general DNA language model is also environmentally friendly. Such a model can be fine-tuned with the task-specific data and settings in just a few iterations, saving computational resources and energy.
There is a lot of potential in further developing the link between transformer networks and DNA to study what else the genome language has to tell us about the life around us. Could this technology contribute to the understanding of genetic traits, the study of evolution, the development of medicine or vaccines? These questions are closely related to the healthcare field, in which Solita has strong expertise, including in research. If you are interested in this type of research, I and other Solita experts will be happy to tell you more!
This tutorial is a hands-on tutorial for Snowflake external functions and shows how you can translate and categorize your Snowflake data using Amazon Translate and Amazon Comprehend services. This tutorial will translate Finnish product comments to English and analyze them.
Kirjoittaja:Mika Heino Data Architect, Snowflake Tech Lead
This the second part of the external functions blog post series and teaches how you can trigger Amazon services like Translate and Comprehend using Snowflake external functions. I will also explain and go through the limits of external functions in this blog post.
In the first blog post, I taught how you can set up your first Snowflake external function and trigger simple Python code inside AWS Lambda. In case external functions are a new concept for you, I suggest reading the first blog post before diving into this.
External functions limitations
Previously I left the limitations of external functions purposely out, but now when we are building something actually useful with them, you should understand the playground what you have and what are the boundaries.
Let’s start with the basics. As all the traffic is going through AWS API Gateway, you’re bound to the limitations of API Gateway. Max payload size for AWS API Gateway is 10MB and that can’t be increased. Assuming that you will call AWS Lambda through API Gateway, you will face the Lambda limits, which are maxed to 6MB per synchronous requests. Depending on the use-case or the data pipeline you’re building, there are workarounds, for example, ingesting the raw data directly through S3.
Snowflake also sets limitations; for example, the remote service at a cloud provider, in our case AWS, must callable from a proxy service. Limitations include that external functions must be scalar functions which mean single value for each input row. It doesn’t though mean that you can’t process only one row at the time. The data is sent as a JSON body which can contain multiple “rows”. Additional limitations set by Snowflake is that Snowflake optimizer can’t be used with external functions, external functions can’t be shared through Secure Data Sharing and you can’t use them in DEFAULT clause of a CREATE TABLE statement or with COPY transformations.
Things to consider
The cloud infrastructure, AWS in this case, sets also limitations or rather things to consider. How does the underlying infrastructure handle your requests? You should think how your function scales, acts on concurrency cases and how reliable it is. Doing a simple function which is called by a single developer usually functions without any issues, but you must design your function in a way that it works with multiple developers who are calling the function numerous times within hour contrasted to the single call which you made during development.
Concurrency is an even more important issue as Snowflake can parallelize external function calls. Can the function you wrote handle multiple parallel calls at once or does it crash? Another thing to understand is that with multiple parallel calls, you end up in a situation where the functions are in different states. This means that you should not write function where the result depends upon the order in which user’s rows are processed.
Error handling is also a topic which should not be forgotten. Snowflake external functions understand only HTTP 200 status code. All other status codes are considered as an error. This means that you need to build the error-handling to the function itself. External functions also have poor error messages as stated above. This means that you need to log all those “other than 200 status codes” to somewhere for later analysis.
Moneywise you’re also on the blindside. Calling out Snowflake SQL function hides all the costs what are related to the AWS services. An external function which is implemented poorly can lead to high costs.
Example data format
External functions call the resources by issuing HTTP POST request. This means that the sent data must be in a specific format to work. The returned data must also conform to a specific format. Due to these factors, the data sent and returned might look unusual. For example, we must always send integer value with the data. This value appears as a row number for the 0-based index. The actual data is converted to JSON data types, i.e.
Numbers are serialized as JSON numbers.
Booleans are serialized as JSON booleans.
Strings are serialized as JSON strings.
Variants are serialized as JSON objects.
All other supported data types are serialized as JSON strings.
It’s essential also to recognise that this means that dates, times, and timestamps are serialized as strings. Each row of data is a JSON array of one or more columns and can sent data can be compressed COMPRESSION syntax with CREATE EXTERNAL FUNCTION -SQL clause. It’s good to though understand that Amazon API Gateway automatically compresses/decompresses requests.
What are Amazon Translate and Amazon Comprehend?
As Amazon advertises, Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation. What does that truly mean? It means that AWS Translate is a fully automated service where you can transmit text data to Translate API and you get the text data translated back in the chosen language. Underneath the hood, Amazon uses its own deep learning API to do the translation. In our use case, Amazon Translate is easy to use as the Translate API can guess the source language. Normally you would force the API to translate text from French to English, but with Translate API, we can set the source language to ‘auto’ and Amazon Translate will guess that we’re sending them French text. This means that we only need minimal configuration to get Translate API to work.
Amazon Translate can even detect and translate Finnish language, which is sometimes consider a hard language to learn.
For demo purposes Translate billing is also a great fit, as you can translate 2M characters monthly in your first 12 months, which start from your first translation. After that period the bill is 15.00$ per million characters.
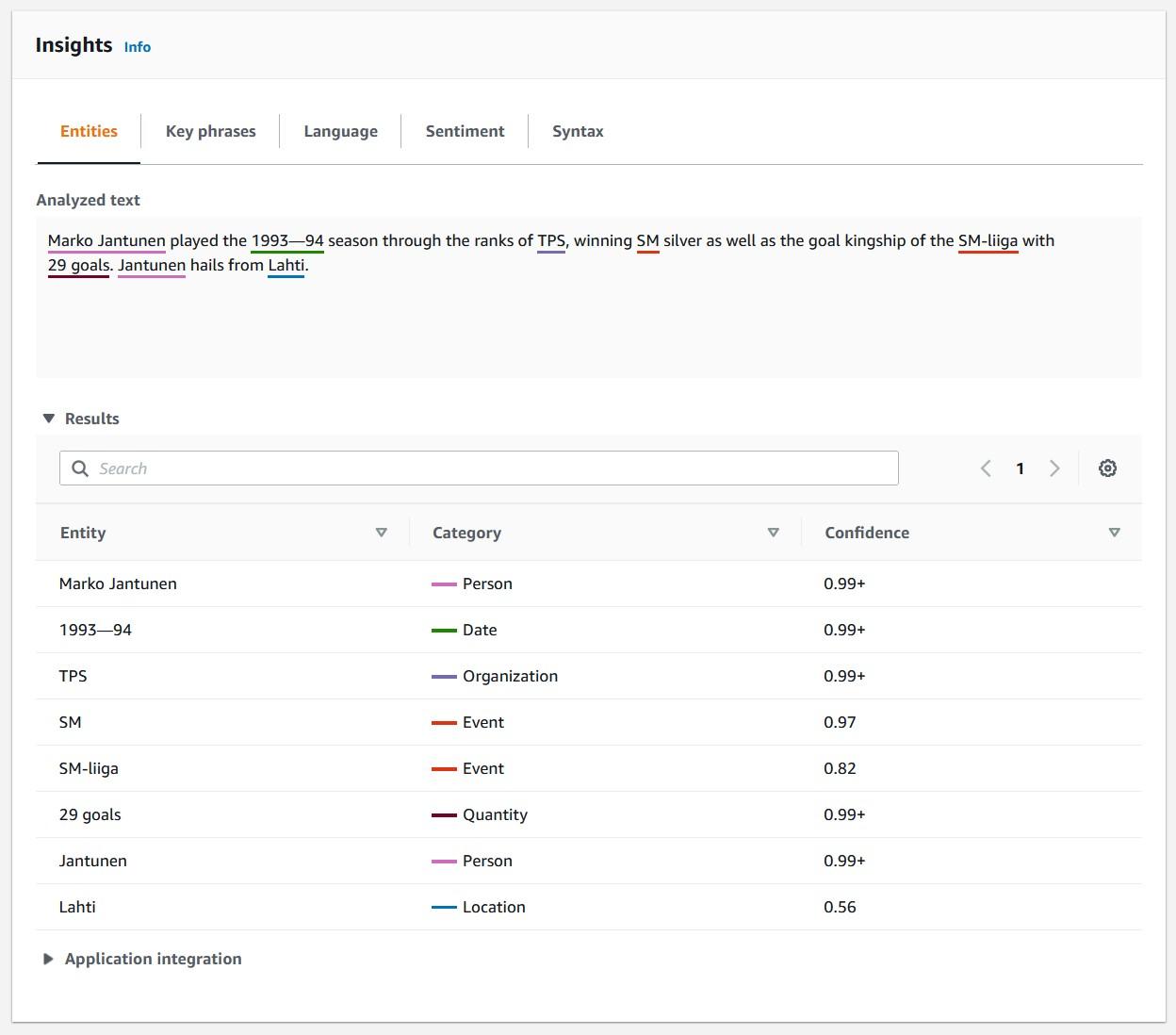
Amazon Comprehend is also a fully managed language processing (NLP) service that uses machine learning to find insights and relationships in a text. You can use your own models or use built-in models to recognize entities, extract key phrases, detect dominant languages, analyze syntax, or determine sentiment. Like Amazon Translate, the service is called through an API.
As Finnish is not supported language for Amazon Comprehend, the translated text is run through the Comprehend API to get insights.
Example – Translating product comments made in Finnish to English with Amazon Translate and Snowflake external functions
As we have previously learned how to create the connection between Snowflake and AWS, we can focus on this example on the Python code and external function itself which is going to trigger the Amazon Translate API. As with all Amazon services, calling Translate API is really easy. You only need to import the boto3 class and use the client session to call the translate service.
After setting up the translate, you call the service with a few mandatory parameters and you’re good to go. In this example, we are going to leverage the Python -code, which was used in the previous blog post.
Instead of doing simple addition of string to the input, we’re going to pass the input to Translate API, translate the text to English and get the result back in JSON -format for later use. You can follow the instructions in the previous example and replace the Python -code with this new code stored in my Github -account.
After changing the Python -code, we can try it right away, because the external function does not need any change and data input is done in the same way as previously. In this case, I have created a completely new external function, but it works in a similar way as previously. I have named my Lambda -function as translate and I’m calling it with my Snowflake lambda_translate_function as shown.
Calling the function is easy as we have previously seen, but when we call the Translate API directly we will the get full JSON answer which contains a lot of data which we do not need.
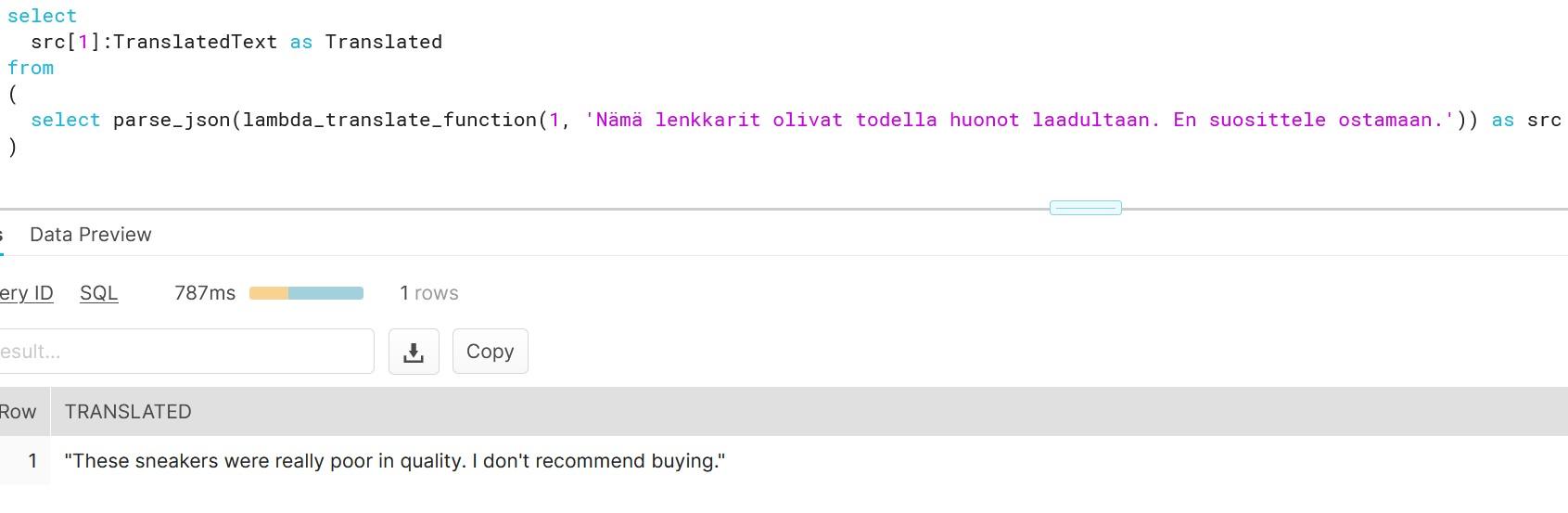
Because of this, we need to parse the data and only fetch the translated text.
As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
Example – Categorizing product comments with Amazon Comprehend and Snowflake external functions
Extending the previous example, we have now translated the Finnish product comment to English -language. We can extend this furthermore by doing sentiment analysis for the comment using Amazon Comprehend. This is also straight forward job and requires only you to either create a new Python function which calls the Comprehend API or modify the existing Python code for demo purposes.
To detect sentiment we use the similarly named sub-class and provide the input source language and text to analyze. You can use the same test data which was used with Translate demo and with the first blog. Comprehend will though give NEUTRAL -analysis for the test data.
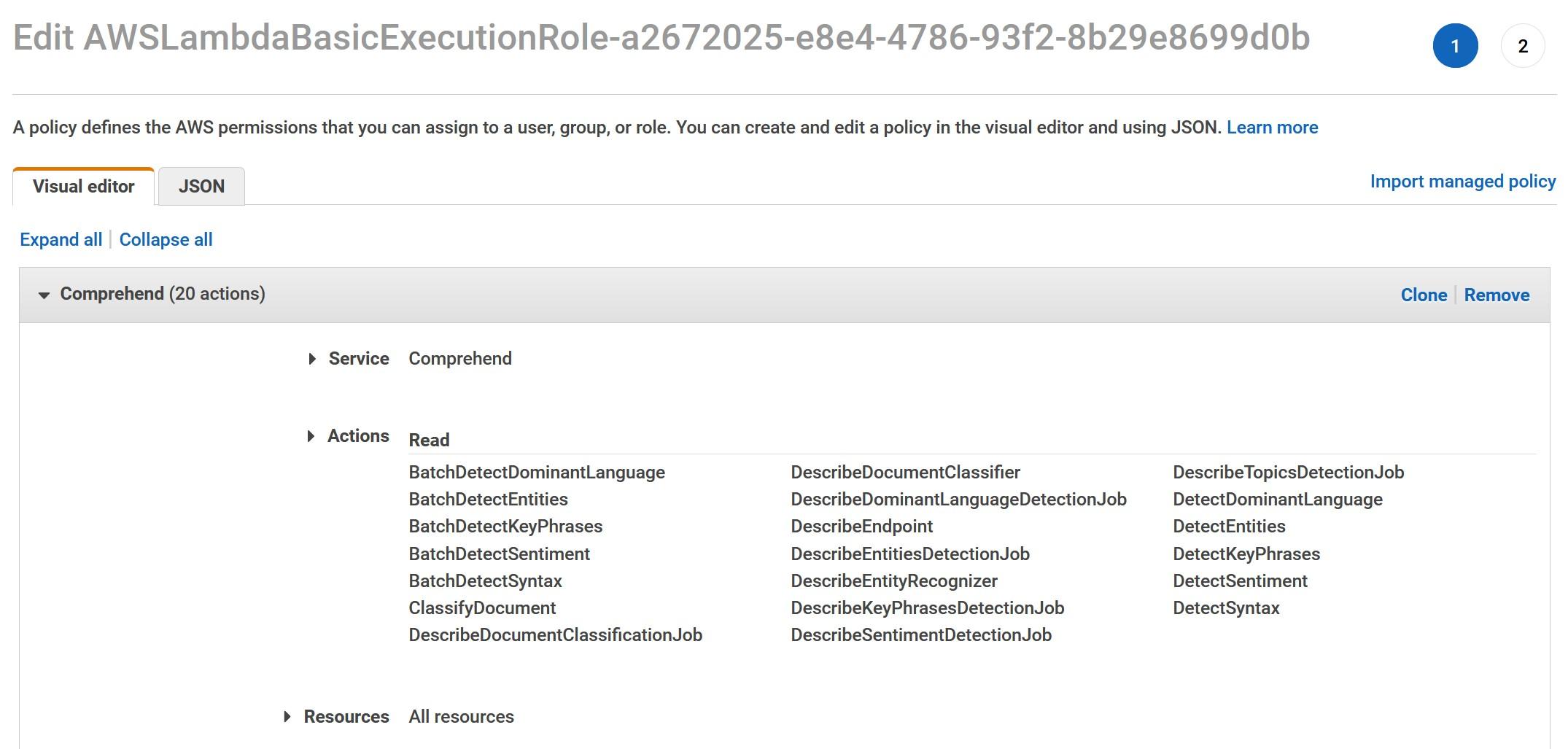
Before heading to Snowflake and trying out the new Lambda -function, go to IAM -console and grant enough rights for the role that Lambda -function uses. These rights are used for demo purposes and ideally only read rights for DetectSentiment action are enough.
These are just example rights and do contain more than are needed.
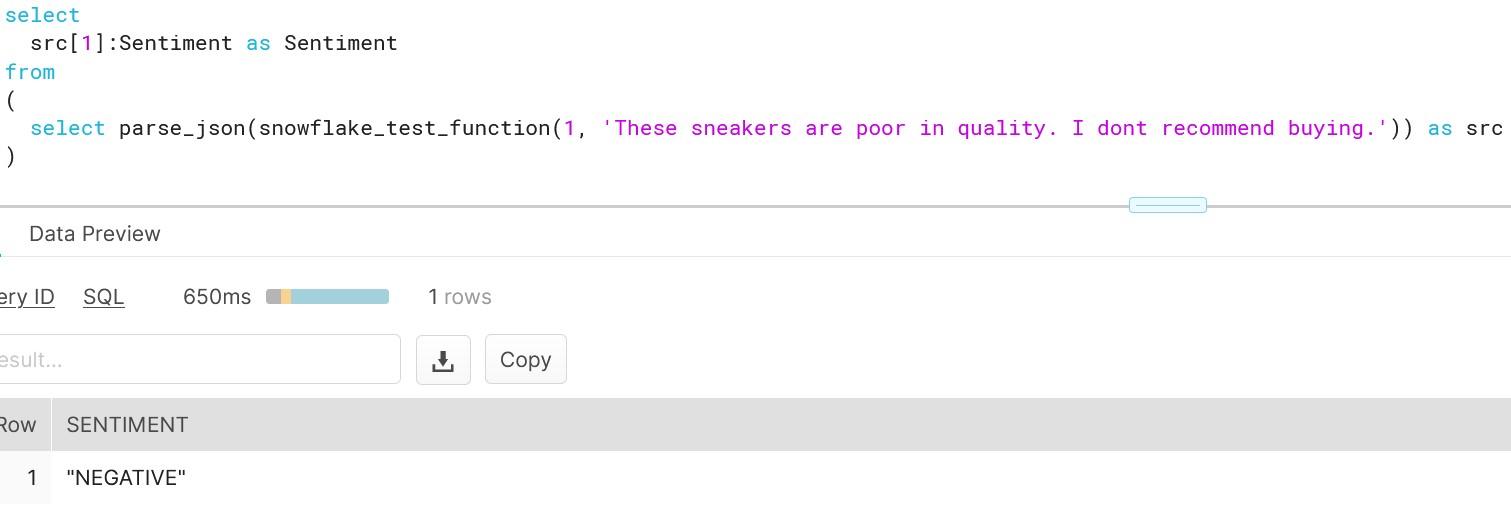
Once you have updated the IAM role rights, jump into the Snowflake console and try out the function in action. As we want to stick with the previous demo data, I will translate the outcome of the previous translation. For demo purposes, I have left out the single apostrophe as those are used by Snowflake.
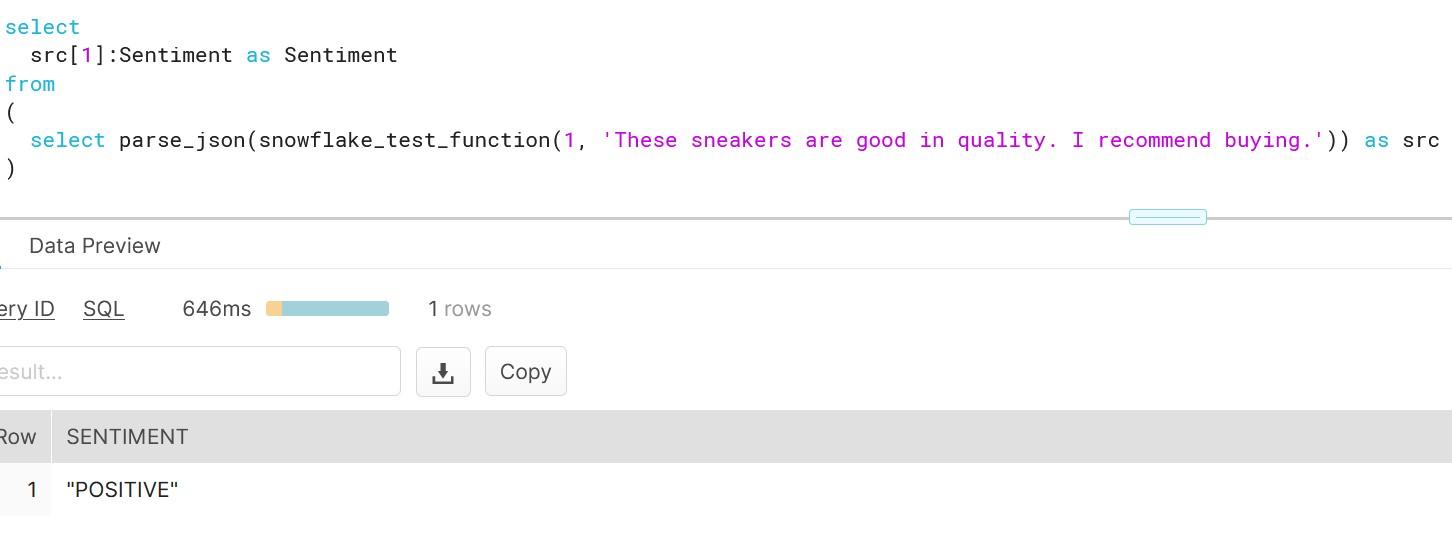
As you can see, getting instant analysis for the text was right. To be sure that we getting correct results, we can test out with new test data i.e. with positive product comment.
As you can, with Snowflake external functions it’s really easy to leverage Machine Learning, Natural Language Processing or AI -services together with Snowflake. External functions are new feature so this means that this service will only grow in the future. Adding Azure and Google compatibility is already on the roadmap, but in the meantime, you can start your DataOps and MLOps journey with Snowflake and Amazon.






 As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.
As you can see, creating functions which do more than simple calculations is easy with external functions. We could gather a list of product comments in multiple languages and translate them into one single language for better analysis e.g. understanding in this case that Finnish comment means that snickers sold are rubbish in quality.