

FastText in a text classification project
Describing the business need for text mining
Companies applied funding with this kind of form.
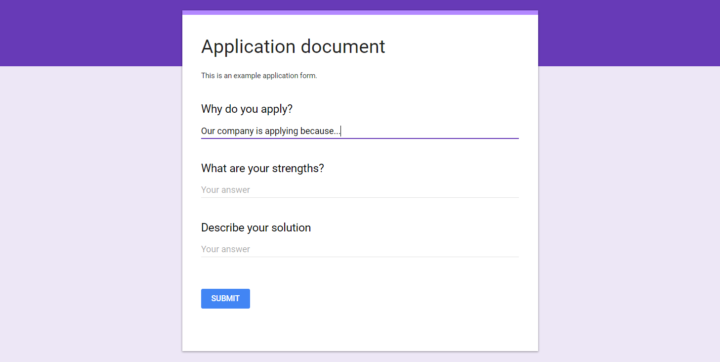
The documents were classified in a several categories by the application handler in the process management software.
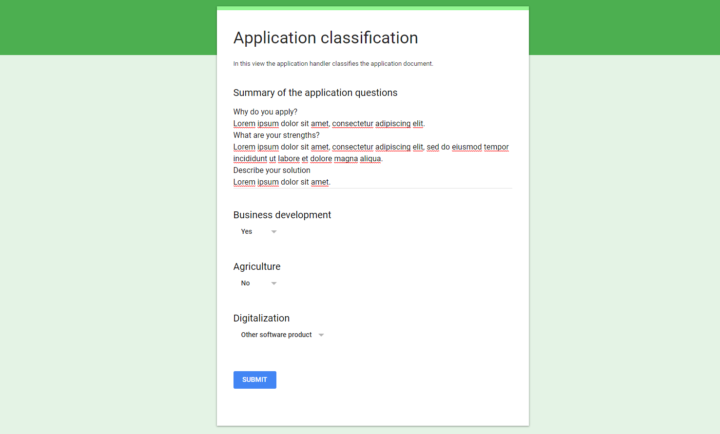
The manual process was not only time consuming, but also frustrating. Reporting was the primary reason for the classification.
Text data is often the most sensitive data
We had two primary ways of getting data.
Customer’s software was developed by Solita’s team. This made it easy to access the SQL database of the testing environment. As a result, we had all numerical and structured data in our hands. Numerical data was useful for application risk prediction, but we needed text data for document classification.
The text data was encrypted in the test database. This meant that we needed a way to securely import the plain language text data from the production SQL database.
There is a good reason why the access to text data should not be easy. Text data might contain sensitive information such as personal data or business secrets.
Selecting FastText as our text mining tool
My personal experience from text mining and classification was very thin. After discussions with the team we decided to go with the FastText package. It has been designed for simple text classification by Facebook.
FastText is quite easy command line tool for both supervised and unsupervised learning. We used a python package which apparently don’t support all original features such as nearest neighbor prediction [link].
For supervised prediction you create individual text files for training and testing data [link]. After files are created, training the neural network behind FastText takes just a few lines of code. We used the supervised method to classify the applications.
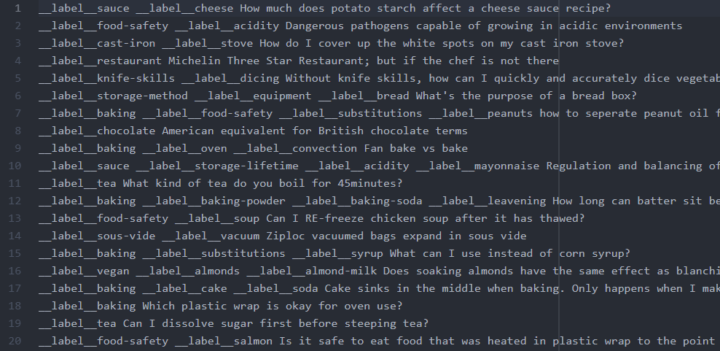
For unsupervised analysis you can just dump a bunch of text to a file to create word vectors [link]. Word vectors are useful for finding words similar to each other.
While English has either singular or plural format such as dog or dogs, Finnish language has koira, koirat, koirani, koiranne, koirienne, koirilatammekohan… There are literally tens of variations for each word. FastText is especially great for languages like Finnish where suffixes at the end of each word vary depending on the context. This is because in addition of creating features from word counts FastText can also take into account combinations of words as well as sub-word character sequences.
A model per category using a document as an observation
Each application had multiple text fields and multiple categories to automatically predict. How to approach the complex problem?
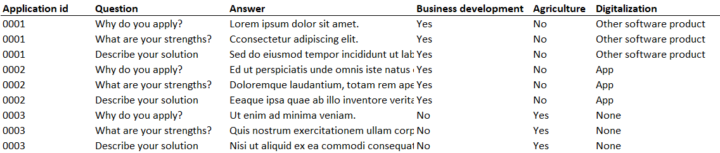
We decided to bundle all applicable text fields from the applications together. Another option would have been to make predictions for each combination of application and text field, and then select the class with most “votes” from text field predictions.

We left out text fields such as team description. Those fields did not bring significant information for the classification.
Trying to understand the labeling principles of FastText made us scratch our heads. The initial idea was to create a single classification model. That model would have included all related labels in a single training row.
In theory this could lead to a situation where all top predictions are from the same category such as Digitalization. As we wanted to get the most probable prediction from each category, we decided to train individual model per category (Business development, Agriculture and Digitalization).
FastText supervised algorithm accuracy
The labels inside categories were unequally balanced. Some categories had even tens of labels with very few observations.
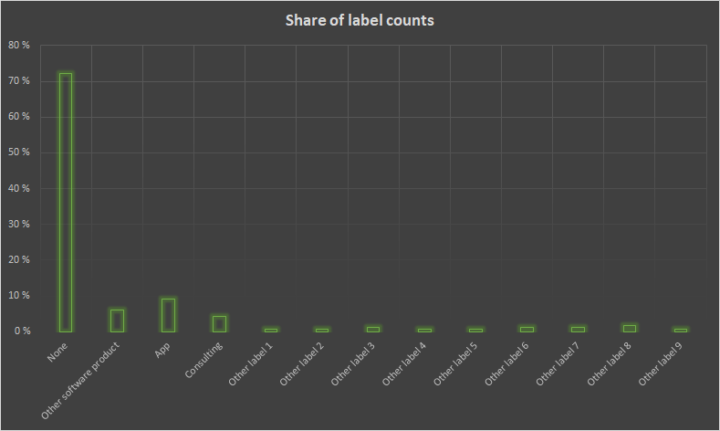
Class imbalance meant that prediction accuracy reached 50% to 90% for some categories by simply guessing the most frequent label. We took this as our base line.
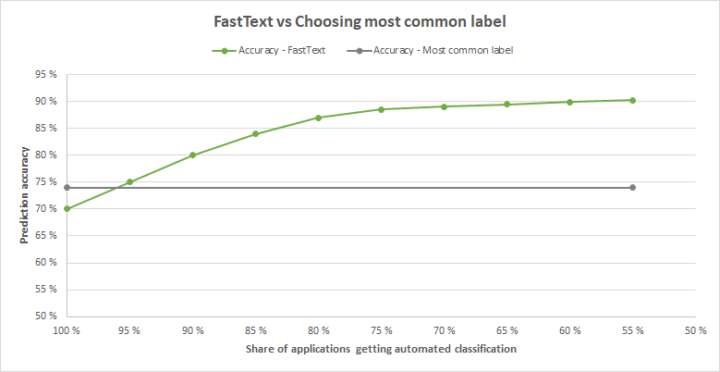
Eventually our model-per-category-strategy produced a few percentage units higher accuracies than choosing the most common label. This only happened after we decided to return the weakest predictions back to manual processing. The probability of prediction’s correctness was automatically given by FastText.
In our case it was enough to beat the naive strategy of choosing the most common label.
Summarizing the FastText classification experiment
Apparently the application handlers don’t pay too much attention about which label they choose. This made us question the whole process. What is the value of reports that are based on application handler’s hunch? And if the labeling criteria are not uniform, how could a machine find any patterns?
Let’s say there are 2000 annual applications. One of the labels gets selected 30 times per year. Binomial probability calculation reveals that 95% confidence interval for 30 labels is actually from 20 to 40. A decision maker might think that a series of 20, 30 and 40 during a three year range indicates ascending trend for the label. But in reality, it’s just a matter of random variation. In one of the categories 15 out of 20 labels had this few or less observations.
FastText favored more common labels as it increased the overall accuracy. This came with the cost that some labels never got predictions.
When the solution has ran in production for a while, it is time to see if the handlers ever make the effort to correct the machine’s initial recommendation. If not, some labels will never end up to the reports.
There are endless number of solutions to automate such document classification. In our project the fast testing cycle to try different approaches was the key. The goal was not to make perfect, but improve the existing situation.
Whatever the prediction accuracy will be, this kind of text mining experiment provides valuable information for the organization.


