

How to manage your SQL Server and Snowflake hybrid environment EDW with Agile Data Engine
Problem description
Agile Data Engine (ADE) is designed to work with a single target cloud data warehouse, but sometimes you need to keep some of your data in an on-premises environment for example for regulatory reasons. You might not be able to open connections to your on-premises infrastructure, but would like to keep both on-prem and cloud data warehouses managed in a single design infrastructure. Following is presented the high-level diagram of the environment in question. We are focusing on creating a system where ADE can be used to also develop an on-prem environment in addition to the main cloud data warehouse.
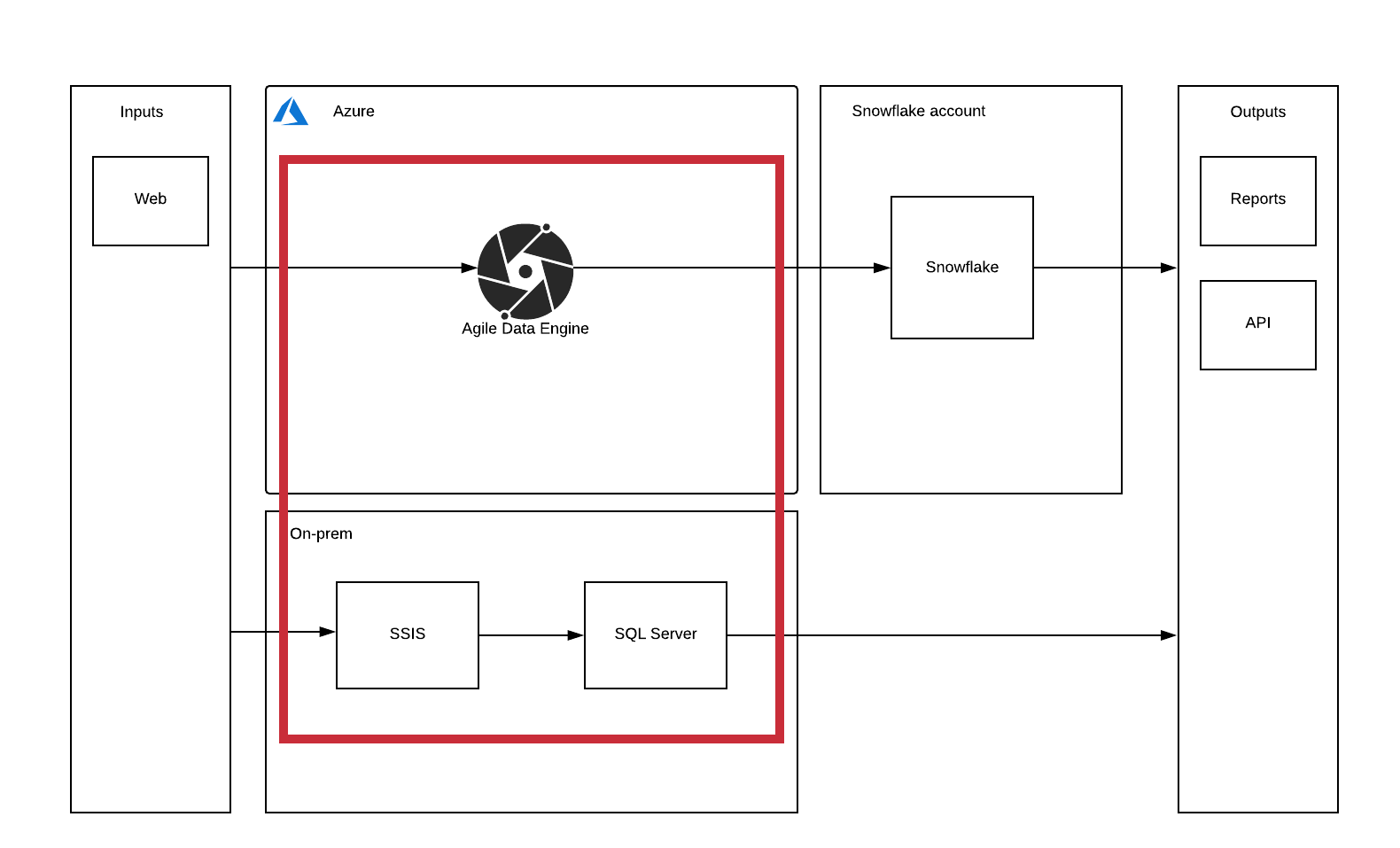
The premisses for this blog post are:
- You have ADE edition with SQL Server export
- The on-prem database is SQL Server
- You have Azure Blob storage and Azure DevOps usable
- Can be switched to other build and sharing locations quite easily
Reference architecture
In this blog post, we will go through a reference architecture where you have Azure as the cloud provider and SQL Server as the local database. The architecture presented here is not completely automated as it requires manual work at least in retrieving the SQL scripts from ADE. But as the on-premises system is secondary from the ADE development point of view, the number of objects should be small compared to the whole structure and developers can easily know what should be transferred to the on-prem environment.
NOTE: If you don’t want to create on-prem tables to the cloud data warehouse, keep them in a separate package that you don’t deploy.
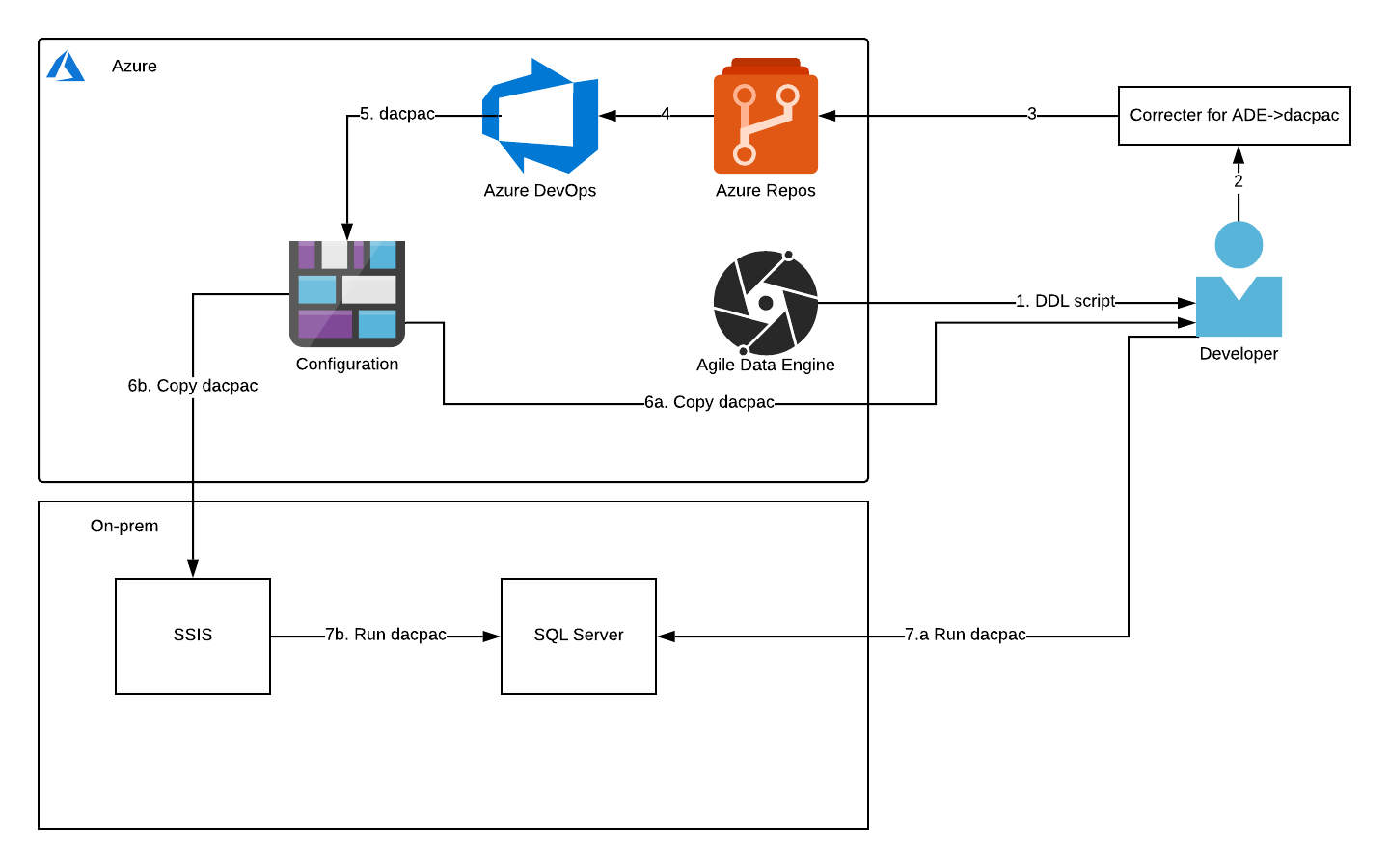
The steps of the diagram are explained in the following chapters. The first step is in Retrieval of SQL from ADE, second and third in Correcting the data to be built to DACPAC, fourth and fifth in Building DACPAC, and lastly both sixth and seventh in Executing the DACPAC.
Retrieval of SQL from ADE
Normally ADE runs the necessary SQLs on your behalf to the target database in the correct SQL dialect. But, ADE also has a feature to export the SQL scripts in the same or different dialects for manual inspection and testing. This is possible because ADE stores metadata and creates the SQL scripts as the last step. We are using this feature to get SQL scripts in a different dialect than the cloud data warehouse. First, go to the entity page that you want to export. From the SQL export options select SQL Server and check the box to create procedure versions of the loads.
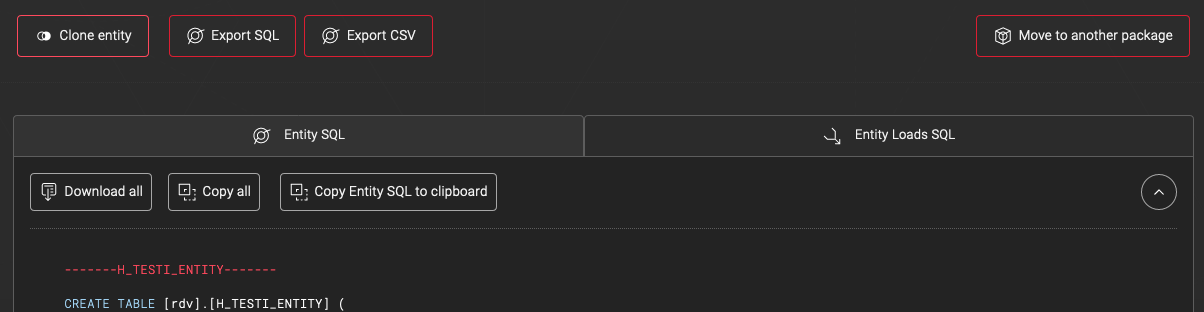
Copy the generated SQL to separate files that are named based on the table/view/load names. Keep the files in folders based on schema and type. See the following example folder structure.
. ├── test-project.sqlproj ├── README.md └── database ├── rdv │ ├── procedures │ │ └── load_h_author_from_source_entity_01.sql │ ├── rdv.sql │ └── tables │ ├── h_author.sql │ ├── l_author_book.sql │ └── s_author.sql └── staging ├── staging.sql ├── tables ├── books.sql
ADE has a tagging functionality to help with managing large amounts of packages and entities inside the packages. Tags can be used to filter lists of both packages and entities. Tags are automatically created for words in description fields starting with a hashtag. In the hybrid situation, the tagging feature can be optionally used to mark which entities are deployed to on-prem and writing in the description field when the deploy was done.
![]()
Correcting the data to be built to DACPAC
Let’s start with a brief explanation of DACPAC. DACPAC is Microsoft data-tier application (DAC) package. It is meant to contain all database and instance objects used for an application. Database objects mean for example tables and view when the instance objects include users. In our use case, it is used to deploy database object changes to SQL Server by comparing the structure of DACPAC to the target database.
The creation of DACPAC is done by building the Visual Studio data-tier application defined by the project file and included SQL scripts. Small changes are needed to be made to SQLs generated by ADE and also to the project file for the DACPAC build to succeed with all necessary files.
SQL changes
DACPAC generation requires that all separate commands have GO commands between them. For field comments, ADE generates separate EXEC commands that need to be separated.
Project file changes
The *.sqlproj needs to be updated with new files and folders for them to be included in the DACPAC. This happens by adding under <ItemGroup> element a new <Folder Include=”<FOLDERPATH>” /> and <Build Include=”<FILEPATH>” />. In the case of SQLs being updated inside already existing files, no project file changes are needed.
<ItemGroup> <Folder Include="database" /> <Folder Include="database\rdv\procedures" /> <Folder Include="database\staging" /> <Folder Include="database\staging\tables" /></ItemGroup> <ItemGroup> <Build Include="database\rdv\rdv.sql" /> <Build Include="database\rdv\procedures\load_h_author_from_source_entity_01.sql" /> <Build Include="database\staging\staging.sql" /> <Build Include="database\staging\tables\books.sql" /> </ItemGroup>
Building DACPAC
Building is done in Azure DevOps using the MSBuild component. Then the required information is copied to the artifact folder for the upload step. The demo setup uses a bash script to upload to blob storage with a Shared Access Signature (SAS) token, but if possible AzureFileCopy component should be used.
NOTE: The SAS token should be stored separately from the pipeline in a secure variable, an environment variable is used for demo purposes.
pool: name: Azure Pipelines demands: msbuild steps: - task: MSBuild@1 displayName: 'Build solution *.sqlproj' inputs: solution: '*.sqlproj' - task: CopyFiles@2 displayName: 'Copy Files to: $(Build.ArtifactStagingDirectory)' inputs: Contents: | **\*.DACPAC **\*.publish.xml TargetFolder: '$(Build.ArtifactStagingDirectory)' - bash: | FOLDER="$(Build.ArtifactStagingDirectory)/bin/Debug/" az storage blob upload -c test-blob -n test-project.DACPAC -f$FOLDER/test-project.DACPAC displayName: 'Bash Script' env: AZURE_STORAGE_CONNECTION_STRING: BlobEndpoint=<ENDPOINT-WITH_TOKEN>

Executing the DACPAC
There are two options for executing the DACPAC. One is for the developer to download the file from blob-storage and run it against the target database with for example Azure Data Studio (requires microsoft.schema-compare extension). This option requires that there is network connectivity to the target database for example through a VPN tunnel.
The second option is to have an execution tool in the on-prem environment like SSIS. The tool can download the blob file and execute it against the target database. It is recommended to have some kind of manual approval before running the file against the production database. In addition to normal production safety measures, the reason here is that DACPAC does not guarantee that it will do the same steps every time, instead it relies on the comparison between DACPAC and the target database.

Operations
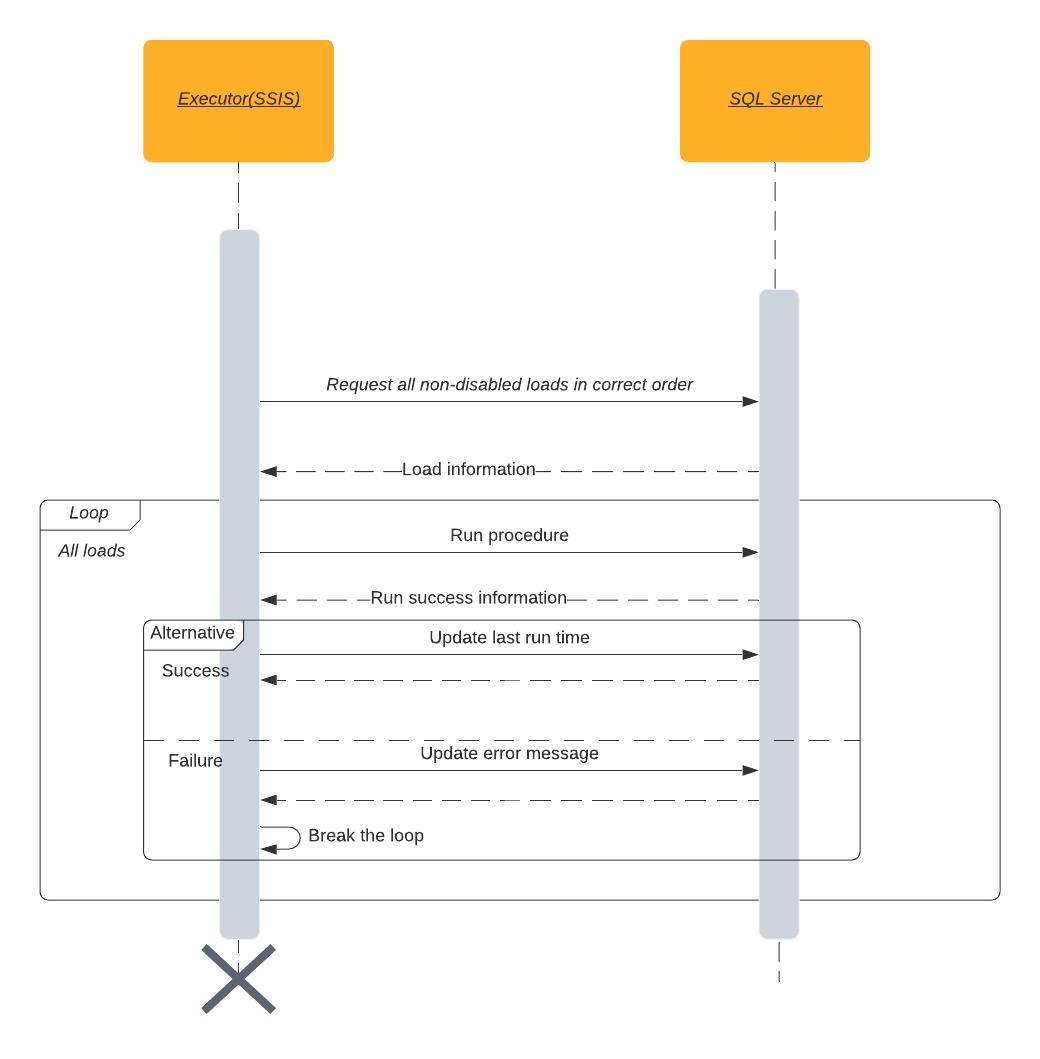
The DDL transfer process can be used for transferring load steps as SQL Server procedures. As no on-prem connection was allowed from ADE in our use case, the load executing elements need to be found from the on-prem environment. One possibility for this is SSIS. The executor can be directed by configuration in a metadata table inside the target environment. The metatable has information on what procedures to run and when. The following sequence diagram explains at a high level the process of executing load steps.
Summary
In this blog post, we went through an example architecture of a hybrid EDW setup with the Agile Data Engine. We looked at the technical level on how to use SQL export functionality in Agile Data Engine and DACPAC to move DDL scripts from Agile Data Engine to on-prem SQL Server. The operations side depends heavily on the existing on-prem infrastructure and was, therefore, only lightly touched.