

Metadata driven development realises “smart manufacturing” of data ecosystems – Part 1
Business Problem
A lot of companies are making a digital transformation with ambitious goals for creating high value outcomes using data and analytics. Leveraging siloed data assets efficiently is one of the biggest challenges in doing analytics at scale. Companies often struggle to provide an efficient supply of trusted data to meet the growing demand for digitalization, analytics, and ML. Many companies have realised that they must resolve data silos to overcome these challenges.
Business Solution
Metadata enables finding, understanding, management and effective use of data. Metadata should be used as a foundation and as an accelerator for any development of data & analytics solutions. Poor metadata management has been one of the key reasons why the large “monolith” data warehouses have failed to deliver their promises.
Data Development Maturity Model
Many companies want to implement a modern cloud-based data ecosystem. They want to migrate away from the old monolith data warehouses. It is important to know the history of how the monoliths were created to avoid repeating the old mistakes.
The history of developing data ecosystems – data marts, lakes, and warehouses – can be illustrated with the below maturity model & analogy to car manufacturing.
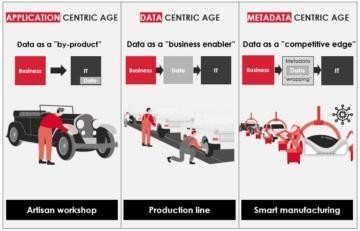
1. Application Centric Age
In the application centric age, the dialogue between business & IT related mostly to functionality needs. Realising the functionality would require some data, but the data was treated just as a by-product of the IT applications and their functionality.
Artisan workshop – created customised solutions that are tuned for a specific use case & functionality – like custom cars or data marts – which were not optimised from data reuse (semantics & integrity etc.) point of view.
Pitfalls – Spaghetti Architecture
Projects were funded, planned, and realised in organisational/ departmental silos. Data was integrated for overlapping point solutions for tactical silo value. Preparation of data for analytics is about 80% of the effort and this was done repeatedly.
As a consequence of lack of focus on data, the different applications are integrated with “point-to-point” integrations resulting in so-called “spaghetti architecture”. Many companies realised that this was very costly as IT was spending a very large part of their resources in connecting different silos with this inefficient style.

2. Data Centric Age
In the data centric age companies wanted to share data for reuse. They wanted to save costs, improve agility, and enable business to exploit new opportunities. Data became a business enabler and a key factor into the dialogue between business & IT. Data demand & supply needed to be optimised.
Companies also realised that they need to develop a target architecture – like enterprise data warehouse (EDW) – that enables them to provide data for reuse. Data integration for reuse required common semantics & data models to enable loose coupling of data producers and data consumers.
Pitfalls – Production line for “monolith” EDW
Many companies created a production line – like chain production or waterfall data program – for building analytical ecosystems or EDWs. Sadly, most of these companies got into the data centric age with poor management of metadata. Without proper metadata management the objective of data reuse is hard to achieve.
There are a lot of studies that indicate that 90% of process lead time is spent on handovers between responsibilities. Within data development processes metadata is handed over between different development phases and teams spanning across an entire lifecycle of a solution.
In waterfall development splits the “production line” into specialised teams. It includes a lot of documentation overhead to orchestrate the teams and many handovers between the teams. In most cases metadata was left in different silo tools and files (Excel & SharePoint). Then the development process did not work smoothly as the handovers lacked quality and control. Handing over to an offshore team added more challenges.
Sometimes prototyping was added, which helped to reduce some of these problems by increasing user involvement in the process.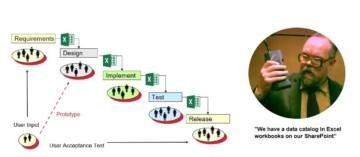
Waterfall development model with poor metadata management
The biggest headache is however the ability to manage the data assets. Metadata was in siloed tools and files, there were no integrated views of the data assets. To create integrated views the development teams invented yet another Excel sheet.
- Poor metadata management made it very hard to:
- understand DW content without the help of experts
- create any integrated views of the data assets that enable reusing data
- analyse impacts of the changes
- understand data lineage to study root causes of problems
Because of slow progress these companies made a lot of shortcuts (technical debt) that started violating the target architecture, which basically meant that they started drifting back to the application centric age.
The beautiful data centric vision resulted in a lot of monolithic EDWs that are hard to change, provide slow progress and have increasing TCO. They have become legacy systems that everyone wants to migrate away.
3. Metadata Centric Age
Leading companies have realised that one of the main pitfalls of the data centric age was lack of metadata management. They have started to move into the “metadata centric age” with a fundamental way of working change. They apply metadata driven development by embedding usage of collaborative metadata capabilities into the development processes. All processes are able to consume and contribute into a common repository. Process handovers are simplified, standardised, integrated, and even automated.
Metadata driven development brings the development of modern data warehouses into the level of “smart manufacturing”.
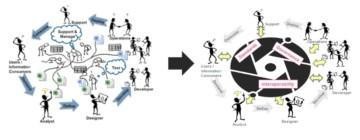
Metadata enables collaboration around shared knowledge
Smart manufacturing enables us to deliver high quality products with frequent intervals and with batch size one. Smart manufacturing uses digital twins to manage designs, processes, and track quality of the physical products. It also enables scaling because knowledge is shared even between distributed teams and manufacturing sites.
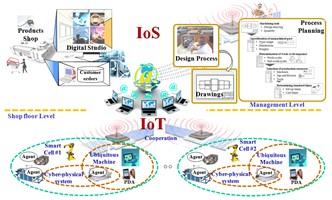
Metadata driven development uses metadata as the digital twin to manage data product designs and the efficiency of the data supply chain. Common metadata repository which is nowadays branded as Data Catalog centralises knowledge, reduces dependency on bottleneck resources and enables a scalable development.
Metadata driven data supply chain produces data products through a life cycle where the artefacts evolve through conceptual, logical, physical, and operational stages. That also reflects the metadata needs in different stages.
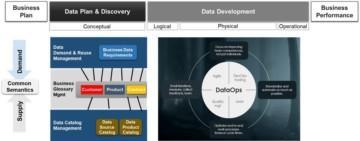
Data Plan & Discovery act as a front end of the data supply chain. That is the place where business plans are translated into data requirements and prioritised into a data driven roadmap or backlog. This part of the data supply chain is a perfect opportunity window for ensuring cross functional alignment and collaboration using common semantics and a common Data Catalog solution. It gives a solid start for the supply of trusted data products for cross functional reuse.
Once the priority is confirmed and the feasibility is evaluated with data discovery, we have reached a commitment point from where the actual development of the vertical slices can continue.
DataOps automation enables smart manufacturing of data products. It enables highly optimised development, test and deployment practices required for frequent delivery of high-quality solution increments for user feedback and acceptance.
DataOps enables consistent, auditable, repeatable & scalable development. More teams – even in distributed locations – can be added to scale development. Solita has experience of forming agile teams that each are serving a certain business function. The team members are distributed into multiple countries, but they all share the same DataOps repository. This enables transparent & automatically documented architecture.
Learn more about Solita DataOps with Agile Data Engine (ADE):
Future-proof your data delivery http://www.agiledataengine.com/
Learn more about Solita experiences with Data Catalogs:
https://www.solita.fi/en/data-catalogs/
Stay tuned for more blogs about “Smart Manufacturing”.
This blog is the first blog in the series. It focused on the maturity model and explained how the large monolith data warehouses were created. It just briefly touched on the metadata driven development. There is a lot more to tell in that.