

Data mesh – the new paradigm you might want to mess with
What is Data Mesh?
We dove into the rapidly developing world of data engineering and dug a little deeper into a trendy topic called data mesh. For the first time, data mesh was introduced in 2019 by Zhamak Dehghani on a highly appreciated blog site by Martin Fowler.
Data lakes and similar monolithic data architectures have been the most common place for organizations to store data. Over time, these have demonstrated their limitations when it comes to scalability and cost [1]. Data engineering usually comes few years after its bigger brother – software engineering. It may just be that the data industry follows the path to abandon monolithic architectures, thus creating new decentralized data architectures to scale with.

To break the ice, we will briefly go through the basic concept around data mesh. Data mesh builds its existence on four principles, and these principles aim to explain the core standpoint. These principles gather together domain-oriented data ownership and architecture, data as a product thinking, data as platform capabilities in a self-service solution, and federated computational governance model keeping decision making as domain specified as possible. These principles embrace the change towards distributed data architecture, where domain teams can scale while developing services and data products. It is important to understand that data mesh is not a technological transformation [1]. Data mesh challenges the organizational and cultural operating models.
Tackling the issues:
Data mesh consists in the implementation of an architecture where data is intentionally distributed among several mesh nodes, in such a way that there are no chaos or data silos to block rapid scaling. Figure 2 shows us the basic concept of a distributed architecture, similar to the popular microservices represented in the software world. However, this requires high data literacy, clear domain definitions, and a good understanding of data ownership to scale your data business even further. We took a closer look at our case organizations and their capabilities to apply the decentralized model.
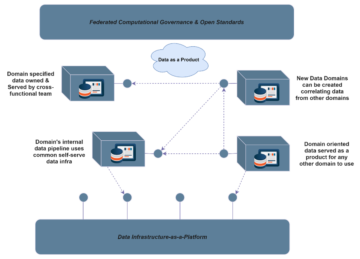
Data mesh and its almost revolutionary suggestions towards data management and monolithic solutions challenge the traditional standpoints. Professionals who have worked within data management, analytics, and data systems may find these suggestions bold. Highlighting the distributed camp, hear me out first, and then decide which camp is for you, or maybe even something between them.
A social technical approach that interests me
Writing a thesis together with an organization is a massive opportunity.
I personally learned a lot and grew as a professional during our research journey. Thanks to my supervisors, this research was tackled with a courageous attitude and a passion for new things in the world of data.
The research itself:
Data mesh is a new thing, based on many battle-tested concepts from the development world, but it’s not studied in any formal context. We wanted to understand to what kind of organizations it is a good fit for and what could be blocking its adaptation. We did this by interviewing 7 different size companies from different domains and backgrounds.
A total of seven interviews were conducted for the implementation of the research. These case companies represent a wide scale of different industries that have a significant impact in Finland. Case organizations represent the following industries: Wood/Forest industry, Telecommunications, Oil refining & Renewable products, Energy generation, Waste recycling, and Construction industry. The variety of different industries and data management solutions formed a strong scheme to create insights on the suitability of the data mesh framework.
These major Finnish companies with a great view into their own industry and data-driven thinking were chosen for the theme interview process. They all are challenging their industry to develop further, as well as their own ways of working with data. All these companies have a specific way of demanding, producing, and consuming the available data. Case organizations were asked a set of questions including topics such as domain definition, ways of working, maturity level, data ownership, and data as a product.
Now we can dive a little deeper into the interviews. Two out of seven organizations already had decentralized data architecture and they described their journey with distribution in the following fashion:
“We are currently fully decentralized. A common so-called “data handbook” is required for multiple data teams across domains. Business areas have benefitted directly from having decentralized teams. There must be an opportunity to make creative solutions”. (Case Organization 3).
“Decentralization has brought data closer to business. As a result, responsibility is given to business data experts. Our operations are more streamlined, and you don’t have to ask every single thing from a centralized data unit.” (Case Organization 5).
These answers tie up some evidence that distributed data teams and architecture benefits organizations throughout their journey to more efficient data utilization. All seven organizations agreed that distributed architecture would increase their maturity level across the organization, and they would be able to create more straightforward processes for data product development. In most case organizations, data ownership seemed to be a common question mark and data mesh could be one solution for more explicit ownership across all the domains.
Distribution isn’t a new thing for enterprises to optimize their functions. Human resources and IT departments are classic instances of commonly distributed units. Data teams are overall very agile and adaptive towards new trends and features to advance ways of working.
“Data mesh is not a new model; it is now rebranded” (Case Organization 3).
While reading articles, blogs, or whitepapers about data mesh and distributed architecture, you can always see someone saying that their organization has done things this way and adapted certain methods years ago. Organizations doing this previously might be true, but data mesh includes precisely designed patterns that must match.
According to this research, organizations struggle with different data management challenges. Bottlenecks are a typical way to describe a part of the process which slows down the production line. Different bottlenecks pointed out during our interviews were: Slow development, amount of data sources (or lack of them), data teams, the complexity of substance systems, huge amount of raw data, data quality, and workload (backlog challenges). These bottlenecks are a good example of organizations having a variety of different roadblocks. Data mesh aims to solve at least a few of them [2].
Graph 1 ties together key points that challenge the use of data mesh. Having a clear domain definition ended up being one of the most important aspects of this research. All of the case organizations recognized the importance of a clear domain definition. Ambiguous domain understanding can block the distribution that data mesh requires.
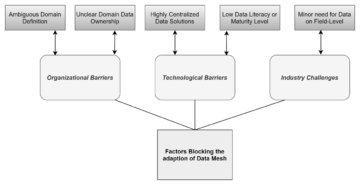
Key takeaways
Overall, multidimensional organization models and higher complexity of data domains seem to create a better breathing ground for data mesh principles and implementation.
Even before this research, we had some insight that larger organizations with complex domains would fit data mesh better. Our results most definitely support this finding, and we can safely say that data mesh has certain organizational standards it requires to be completely efficient. However, data mesh is still looking for its litmus test to prove the full potential behind it [2].
Although, this doesn’t prevent organizations with a few questions marks lying around to be unsuitable for data mesh principles. This research gathered together a few points that should be taken into consideration before moving towards data mesh.
Hence, we can state that data mesh has a stormy future ahead, and it should not be disregarded by any organization willing to scale with data. This new data paradigm shift could just be the one for your organization.
Lastly, I would like to express my greatest appreciations to the wonderful people from Solita I had the privilege to work with during my master’s thesis journey, Vesa Hammarberg, Antti Loukiala, and Lasse Girs.
If you are interested in data mesh solutions in Solita, please feel free to contact simo.hokkanen@solita.fi.
References:
[1] Dehghani Zhamak, Data Mesh principles and Logical Architecture. Martin Fowler’s Blog, 2020 https://martinfowler.com/articles/data-mesh-principles.html as of February 15th, 2021.
[2] Hokkanen Simo, Utilization of Data Mesh Framework as a Part of Organization’s Data Management. University of Eastern Finland, Master’s Thesis, 2021.