

Metadata driven development realises “smart manufacturing” of data ecosystems – blog 2
The first part of this blog series introduced a maturity model that illustrated the history of developing data ecosystems – data marts, lakes, and warehouses – using an analogy to car manufacturing. It explained how the large monolith data warehouses were created. It just briefly touched on the metadata driven development.
This blog drills down to the key enablers of metadata driven data supply chain that was introduced in the last blog. The blog has 2 main chapters:
- The Front End – Data Plan & Discovery
- The Back End – Data Development with Vertical Slices & DataOps automation
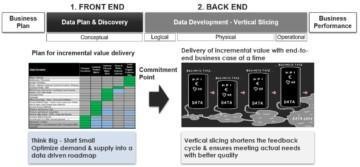
Metadata driven data supply chain produces data products through a life cycle where the artefacts evolve through conceptual, logical, physical, and operational stages. That also reflects the metadata needs in different stages.
Data plan for incremental value delivery – The front end of the data supply chain leverages data catalogs to optimise data demand and supply into a data driven roadmap.
Delivery of incremental value – The back end of the data supply chain delivers business outcomes in vertical slices. It can be organized into a data product factory that has multiple, cross functional vertical slice teams that deliver data products for different business domains.
Vertical slicing enables agility into the development processes. DataOps automation enables smart manufacturing of data products. DataOps leverages metadata to centralize knowledge for distributed people, data & analytics.
Business Problems with poor metadata management
As a result of building data ecosystems with poor metadata management companies have realised large monolith data warehouses that failed to deliver the promises, and now everyone wants to migrate away from them. There is a high risk that companies end up building new monoliths unless they change the way of developing data ecosystems fundamentally.
Business Solution with metadata driven development
Metadata enables finding, understanding, management and effective use of data. Metadata should be used as a foundation and as an accelerator for any development of data & analytics solutions. Metadata driven development brings the development of modern data warehouses into the level of “smart manufacturing”.
1. Front end – Data Plan & Discovery
Data Plan & Discovery act as a front end of the data supply chain. That is the place where business plans are translated into data requirements and prioritised into a data driven roadmap or backlog.
This is the place where a large scope is broken into multiple iterations to focus on outcomes and the value flow. We call these vertical slices at Solita. This part of the data supply chain is a perfect opportunity window for ensuring a solid start for the supply of trusted data products for cross functional reuse. It is also a place for business alignment and collaboration using common semantics and a common data catalog.
Common semantics is the key for managing demand and supply of data

Common semantics creates transparency to business data requirements and data assets that can be used to meet the requirements. Reconciling semantic differences and conflicting terms enables efficient communication between people and data integrations between systems.
Common semantics / common data definitions enable us to present data demand and supply using common vocabulary. Common semantics also enables decoupling data producers and data consumers. Without it companies create point-to-point integrations that lead to well known “spaghetti architecture”.
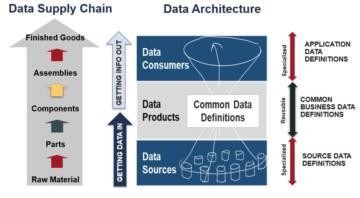
Data products is gaining significant interest in our industry. There seems to all kinds of definitions for data products. They come in different shapes and forms. Again, we should learn from manufacturing industry and apply it for data supply chain.
Flexible data architecture is built on stable, modular design of data products.
Modular design has realized mass customisation in manufacturing industry. Reusing product modules has provided both economies of scale and the ability to create different customer specific configurations for increased value for customers. Here is a fantastic blog about this.
Reuse of data is one of the greatest motivations for data products because that is the way to improve speed and scale data supply capability. Every reuse of data product means 70% cost saving and dramatic improvement in speed & quality.
An efficient data or digitalization strategy needs to include a plan for developing a common business vocabulary that is used for assignment of data domain level accountabilities. The common business vocabulary and the accountabilities are used to support design and creation of reusable data products on data platforms and related data integration services (batch, micro services, API, messaging, streaming topics) for sharing of the data products.
An enterprise-wide vocabulary is a kind of “North Star” vision that no company has ever reached, but it is a very valuable vision to strive for, because cost for integrating different silos is high.
Focus on common semantics does not mean that all data needs to be made available with common vocabulary. There will always be different local dialects and that is OK. What seems today like a very local data need may tomorrow become a very interesting data asset for a cross functional use case, then governance needs to act on resolving the semantic differences.
Data demand management is a great place to “battle harden” the business vocabulary / common semantics
Too often companies spend a lot of time on corporate data models and common vocabulary but lack a practical usage of them in the data demand management.
Data demand management leverages the common semantics to create transparency to business data requirements. This transparency enables us to compare data requirements of different projects to see project dependencies and overlaps. These data requirements are prioritised into a data roadmap that translates data demand into an efficient supply plan that optimises data reuse and ensures incremental value delivery.

Data catalogs play a key role in achieving visibility to the data assets that can be used to meet business needs. Data reuse is a key for achieving efficiency and scaling of the data supply chain.

Embedding data catalog usage into the data supply chain makes the catalog implementation sustainable. It becomes a part of normal everyday processes and not as a separate data governance activity.
Without a Data Catalog the front end of the data supply chain is typically handled with many siloed Excel sheets covering different areas like – requirements management & harmonization, high level designs and with source-target mappings, data sourcing plans, detailed designs & mappings, and testing plans etc.
Collaborative process for term harmonisation follows business priority
Data governance should not be a police force that demands compliance. Data Governance should be business driven and proactively ensuring efficient supply of trusted data for cross functional reuse.
Data governance should actively make sure that the business glossary covers the terms needed in the data demand management. Data governance should proactively make sure that the data catalog contains metadata of the high priority data sources so that the needed data assets can be identified.
Data governance implementation as an enterprise-wide activity has a risk of becoming academic.
Business driven implementation approach creates a basis for deploying data governance operating models incrementally into high priority data domains. This can be called “increasing the governed landscape”.
Accountable persons are identified, and their roles are assigned. Relevant change management & training are held to get the data stewards and owners aware of their new roles. Understanding is increased by starting to define data that needs to be managed in their domains and how that data could meet the business requirements.
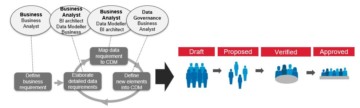
Common semantics is managed both in terms of formal vocabulary / business glossary (sometimes called Corporate Data Model (CDM)) as well as crowd sourcing of the most popular terms. Anyone can propose new terms. Data Governance should identify these terms and formalise them based on priority.
Commitment Point – Feasibility of the plan is evaluated with data discovery
Data plan is first done at the conceptual level to “minimise investment for unknown value”. Conceptual data models can support this activity. Only when the high priority vertical slices are identified it makes sense to drill down to the next level of detail in the logical level. Naturally, conceptual level means that there could be some risks with the plan. Therefore, it makes sense to include a data discovery for early identification of risks in the plan.
Data discovery reduces risks and wasting effort. The purpose is to test with minimal investment hypothesis & business data requirements included in the business plan by discovering if data provides business value. Risks may be top-down resulting from elusive requirements or bottom-up resulting from unknown data quality.
This is also a place where some of the data catalogs can support as they include data profiling functionality and data samples that help to evaluate if data quality is fit for the intended purpose.
Once the priority is confirmed and the feasibility is evaluated with data discovery, we have reached a commitment point from where the actual development of the vertical slices can continue.
2. Back end – Data Development with Vertical Slices & DataOps automation
Vertical slicing means developing an end-to-end data pipeline with fully implemented functionality – typically BI/analytics – that provides business value. Vertical slicing enables agility into data development. The work is organised into cross functional teams that apply iterative, collaborative, and adaptable approaches with frequent customer feedback.
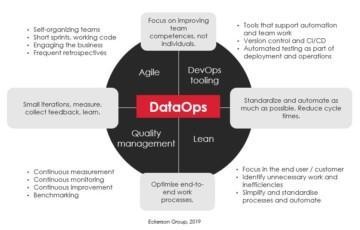
DataOps brings the development of modern data warehouses into the level of “smart manufacturing”.
Smart manufacturing uses digital twin to manage designs, processes, and track quality of the physical products. Smart manufacturing enables to deliver high quality products with frequent interval and with batch size one. It also enables scaling to physically distributed production cells because knowledge is shared with the digital twin.
DataOps uses metadata as the digital twin to manage data product designs and the efficiency of the data supply chain. DataOps centralizes knowledge, which enables to scale data supply chain to distributed people, who deliver high quality data products in frequent time interval.
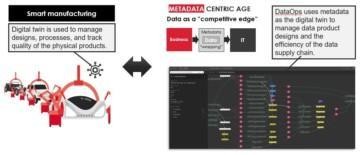
DataOps automation enables smart manufacturing of data products. Agile teams are supported with DataOps automation that enables highly optimised development, test and deployment practices required for frequent delivery of high-quality solution increments for user feedback and acceptance. DataOps enables to automate large part of the pipeline creation. Focus of the team shifts from basics to ensuring that the data is organized for efficient consumption.
DataOps enables consistent, auditable & scalable development. More teams – even in distributed locations – can be added to scale development. The team members can be distributed into multiple countries, but they all share the same DataOps repository. Each team works like a production cell that delivers data products for certain business domain. Centralized knowledge to enables governance of standards and interoperability.

DataOps automation enables accelerated & predictable business driven delivery
Automation of data models and pipeline deployment removes manual routine duties. It frees up time for smarter and more productive work. Developer focus shifts from data pipeline development to applying business rules and presenting data as needed by the business consumption
Automation enables small, reliable and delivery of high-quality “vertical slices” for frequent review & feedback. Automation removes human errors and minimises maintenance costs.
Small iterations & short cycle times – We make small slices and often get feelings of accomplishment. The work is much more efficient and faster. When we deploy into production sometimes the users ask if we started developing this.
DataOps facilitates a collaborative & unified approach. Cross functional teamwork reduces dependency on individuals. The team is continuously learning towards wider skill sets. They become high performers and deliver with dramatically improved quality, cost, and speed.
Self-organizing teams – More people can make the whole data pipeline – the smaller the team the wider the skills.
DataOps centralises knowledge to scale development. Tribal knowledge does not scale. DataOps provides a collaborative environment where all developers are consuming and contributing to a common metadata repository. Every team member knows who, what, when, and why of any changes made during the development process and there is no last-minute surprise causing delivery delays or project failure.
Automation frees up time for smarter and more productive work – Development with state-of-the-art technology radiates positive energy in the developer community
DataOps enables rapid responses to constant changes. Transparent & automatically documented architecture ensures that any technical depth or misalignment between teams can be addressed by central persons like data architect. Common metadata repository supports automated and accurate impact analysis & central management of changes in the data ecosystem. Automation ensures continuous confidence that the cloud DW is always ready for production. Changes in the cloud DW and continual fine tuning are easy and without reliance on manual intervention.
Continuous customer feedback & involvement – Users test virtually continuously, and the feedback-correction cycle is faster
Solita DataOps with Agile Data Engine (ADE)
Agile Data Engine simplifies complexity and controls the success of a modern, cloud data warehouse over its entire lifecycle. Our approach to cloud data warehouse automation is a scalable low-code platform balancing automation and flexibility in a metadata-driven way.
We automate the development and operations of Data Warehouse to ensure that it delivers continuous value and adapts quickly and efficiently to changing business needs.
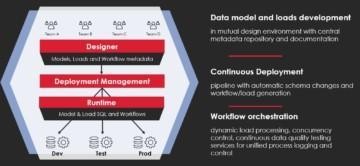
Designer
Designer is used by the users for designing the data warehouse data model and load definitions. It is also the interface for the users to view the graphical representations of the designed models and data lineages. The same web-based user interface and an environment shared by all data & analytics engineering teams.
Deployment Management
Deployment Management module manages the continuous deployment pipeline functionality for data warehouse solution content. It enables continuous and automated deployment of database entities (tables, views), data load code and workflows into different runtime environments.
Shared repository
Deployment Management stores all metadata changes committed by the user into a central version-controlled metadata repository and manages the deployment process.
Metadata-driven code generation
The actual physical SQL code for models and loads is generated automatically based on the design metadata. Also, load workflows are generated dynamically using dependencies and schedule information provided by the developers. ADE supports multiple cloud databases and their SQL dialects. More complex custom SQL transformations are placed as Load Steps as part of metadata, to gain from the overall automation and shared design experience.
Runtime
Runtime is a module used for operating the data warehouse data loads and deploying changes. Separate runtime required for each warehouse environment used in data warehouse development (development, testing and production). Runtime is also used as a workflow and data quality monitoring and troubleshooting the data pipelines.
Learn more about Solita DataOps with Agile Data Engine (ADE):
Future-proof your data delivery http://www.agiledataengine.com/
Learn more about Solita experiences with Data Catalogs:
https://www.solita.fi/en/data-catalogs/
Stay tuned for more blogs about “Smart Manufacturing”.
This blog is the 2nd blog in the series. The 1st blog focused on the maturity model and explained how the large monolith data warehouses were created. This 2nd blog focused on metadata driven development or “smart manufacturing” of data ecosystems. The 3rd blog will talk about reverse engineering or how existing data assets can be discovered to accelerate development of new data products. There is a lot more to tell in that.