

AWS re:Invent 2022 re:Cap
After two years of virtual events and uncertainty in travel restrictions, this year it finally looked possible to attend the biggest AWS event on-site too, so I definitely wanted to take the opportunity to head to Las Vegas once again. I have been to two AWS conferences before (re:Invent in 2018 and re:Inforce in 2019), so I already had some idea of what to expect from the hectic week. You can read more about what to expect and tips and tricks for attending from the previous blog posts, as most of them applied this year too and the conference itself hasn’t changed that much from previous years. In this blog post, I’m going to summarize all the different sessions that I attended during the week to give you an idea of what’s happening during this massive and long event.

Pre-planning and scheduling
re:Invent is always a huge conference and this year made no exception. With over 50,000 participants and 2600 sessions to choose from over five days, there’s a lot of content for almost everything AWS related. With the massive scale of the conference comes some challenges related to finding relevant content. There are different types of sessions available, with breakout sessions being lecture-type presentations that will be published to YouTube later on. Therefore, I tried to focus on reserving seats to more interactive, Q&A focused Chalk Talks and hands-on workshops, as those are only available at the event itself.
This year, reserving seats to the sessions went pretty smoothly, but once again the calendar and session finder were quite lacking in helpful features that would make the process a lot easier. For example, you can’t easily search for sessions that would fit your calendar at the location your previous session ended, but have to go through the session list manually with some basic filters. Also, since there are many different venues and traveling between venues takes a lot of time, you would want to minimize the amount of venues per day, but for some reason the sessions I wanted to go to were scattered all over the campus. So initially, my calendar looked pretty unrealistic, as sessions were in multiple different locations throughout the days. Therefore I ended up just focusing on a couple of longer workshops per day, and favoriting a bunch of sessions in the same location as the previous or next session. This way, I could easily have a “Plan B” or even a “Plan C” when trying to find a walk-up spot for some of the sessions.
However, this meant that my calendar for the week ended up looking like this:

Overall, the scheduling experience was still a bit lacking compared to the excellent quality of the conference otherwise. But at least this time in the end I managed to get in to pretty much all of the sessions I wanted to, and the schedule worked out pretty well in practice too, as you could utilize the free time between sessions with all the nice things happening around (content hub, labs, jam lounge) and just walking around the huge expo area (talking to AWS staff, vendors and also collecting some nice swag)
Notes from the sessions
Here are some short recaps on the different sessions that I attended during the week.
Day 0 – Sunday
The whole Solita crew attending the event started the journey with the same flight, but after some unfortunate flight delays, we were split to different connecting flights in Dallas and finally arrived to Las Vegas in late Saturday night after 22 hours of traveling and a lot of waiting.
For some reason, the traditional Midnight Madness event with the first announcements was not held this year, so Sunday was quite relaxed with some strolling around while trying to deal with jet lag. Badge and hoodie pickup points opened on Sunday, so that was pretty much the only official agenda for the day. In the evening we had dinner with the whole Solita crew attending the event this year.

Day 1 – Monday
Hackathon: GHJ301-R – AWS GameDay: The New Frontier
Day one started early at 8:30 AM with one of the most interesting sessions available – the GameDay Hackathon where teams of four compete against each other in a gamified learning experience. Because there was no reserved seating available for this year’s GameDay sessions, I wanted to make sure to get there in time. And due to some jet lag, a brisk morning walk was also a good way to wake up. In the end, I was there way too early as there wasn’t a huge queue to get in like I had thought and the room didn’t even get full.
The concept of GameDay was a bit different this year, as there were independent quests and challenges instead of one unifying challenge. In 2018, the theme was microservices and trying to keep the services up and running while something unexpected occurred. That required a bit more teamwork, as now you could just focus on working on one challenge at a time individually.
There were also some bonus quests added during the session, and even Jeff Barr made a quick visit on stage announcing a trivia bonus quest. In the end, our team finished 10th out of roughly 40 participating teams, but we could’ve had a lot more points if we had done some of the challenges in a different order, as there were some that were generating a lot more points based on the time they were completed.
Overall, it was a fun learning experience once again, as you get to solve some puzzles and try new services in a more hands-on way than in a workshop.



Workshop: AIM312-R – Build a custom recommendation engine in 2 hours with Amazon Personalize
Next up was a 2 hour workshop focused around recommendations using Amazon Personalize. I have previously tinkered with the service right when it launched, and it was a bit limited in features back then. Over the years they have added some new things like promotions, campaigns and metrics, but if you are trying to do anything more complicated, you might quickly run into the limits of the service.
The title of the workshop was a bit misleading, since the actual model used for recommendations was already pre-built and would take way longer than 2 hours to complete even with the small dataset that was used in the workshop.

Session: BOA304 – Building a product review classifier with transfer learning
I had scheduled a second workshop for the afternoon but it would have been on the other side of the campus, so I opted for staying near Venetian so that I could visit the Expo area too. Found a breakout session with an interesting topic so I decided to join it as a walk-up. The very quick 20 minute session was about using a pre-built model from Hugging Face in Sagemaker and doing some transfer learning for building a simple helpful/not helpful classifier for Amazon.com product reviews.

Chalk Talk: DAT301 – Use graphs to perform fraud analysis with Amazon Neptune and Neptune ML
I also managed to get in a chalk talk as a walk-up without any queueing(!). Apparently graph databases are still not that widely used. It was an interesting session though, and with chalk talks you get a lot more opportunities for interacting with and asking questions from the presenters.
Neptune ML seems like a pretty nice wrapper for Sagemaker, but it looked like you needed to use property graphs (Gremlin or openCypher) instead of RDF (SPARQL). The upcoming Graph Explorer looked nice compared to the current very limited visualization tools available using Neptune Notebooks. Some pretty good conversation sparked from questions from the audience regarding data modeling in graph databases.

After the sessions on Monday evening, AWS Nordics hosted a welcoming reception in one of the restaurants located inside Venetian, the main conference hotel. It was quite packed, but it was nice to meet new people from other companies in Finland.
Day 2 – Tuesday
Keynote: Adam Selipsky’s keynote
To save some time on traveling between venues and waiting in queues, I opted to watch the Tuesday morning’s main keynote from an overflow space located at my hotel. Loads of new announcements and customer cases were shared once again. The biggest data related announcements were probably OpenSearch Serverless, the “zero-ETL” integration of Athena and Redshift, general availability of Redshift streaming ingestion from Spark, and Datazone, a new data catalog and governance tool which I hoped to learn more about in a new launch session, but unfortunately there weren’t any available and even the blog post was quite vague on details.

Workshop: LFS303 – Finding data in a life science data mesh
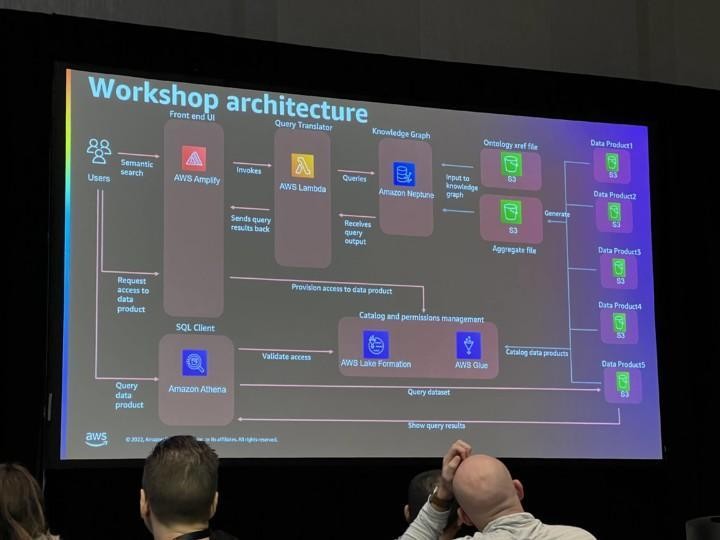
The first workshop on Tuesday focused on creating a data mesh setup with multiple different health care data sets in S3 that were cataloged using Lake Formation and crawled using Glue. Information about the data sets was then converted into RDF Triples and loaded into Amazon Neptune so that graph traversal queries can be done and medical codes can be combined with the hierarchical medical code ontology data set to create a knowledge graph where you can find out the data sets where the data you are looking for is located in, using differently formatted medical codes. Then you can use Lake Formation to provide fine grained access to the data and Athena to query the actual data.
This was a pretty good and informative workshop with some similarities to one use case in my current project too (Neptune and hierarchical ontologies), and I learned something new from Lake Formation which I hadn’t used before too.

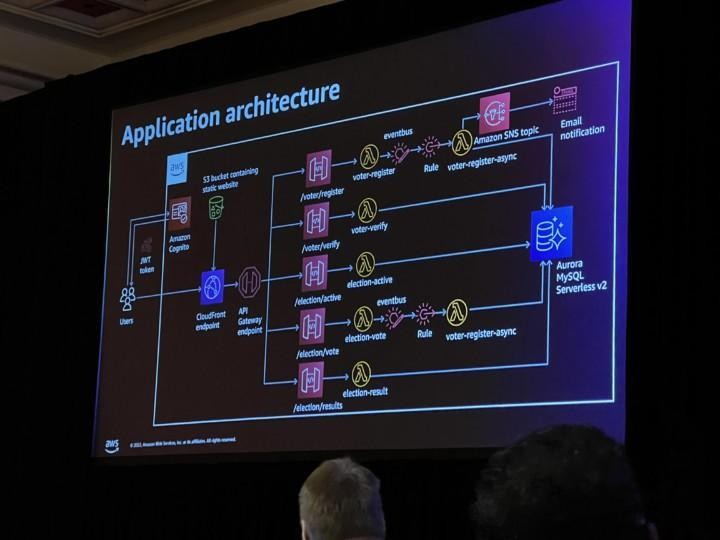
Workshop: DAT310-R – Develop event-driven applications using Amazon Aurora Serverless v2
The agenda for the second workshop of Tuesday was building a simple voting web application using serverless components (Aurora Serverless, Lambda, API Gateway and Cloudfront) and auto-scaling, with authentication using Cognito. The use case was quite basic, so nothing too special was done in this workshop, but it was still nice to see how quickly Aurora is able to auto-scale when the load increases or decreases, while latencies to the web application remain low.

Session: CMP314 – How Stable Diffusion was built: Tips and tricks to train large AI models
There wasn’t any space for two chalk talks that I tried to join as a walk up (without reservation), so instead I went to listen to a session on how the text-to-image ML model Stable Diffusion was trained instead. It was fun to hear from the challenges that training that massive of a model has and the infrastructure around it, even though this massive ML model training is probably something I won’t be doing anytime soon.

After the sessions on Tuesday night there were some sponsored restaurant reception events at the venues, and in addition to that I attended an event hosted by Databricks at Topgolf. It was a fun experience to try some rusty golf swings on a gamified driving range while meeting new people and discussing what they are doing using AWS services.
Day 3 – Wednesday
Workshop: BOA325-R – Building a serverless Apache Kafka data pipeline
On Wednesday morning Swami Sivasubramanian hosted a keynote focusing on data & machine learning. I had booked a workshop at the same time, so I tried to follow the keynote while waiting for the workshop to start. Some new features for existing products were announced, for example Spark support for Athena and Geospatial ML for Sagemaker.
The actual workshop was focused on building a quite simple data pipeline with a Fargate task simulating generating clickstream events, sending them to Kafka which triggered a Lambda to convert the events to a CSV format and upload that to S3. Converted files were then visualized in QuickSight.


Workshop: ANT312 – Streaming ingestion and ML predictions with Amazon Redshift
Second workshop of the day focused on the new-ish streaming ingestion and ML features of Redshift. First streaming data was loaded from Kinesis to Redshift using the new Streaming Ingestion feature where you don’t need to use Firehose and S3 but you can just define the Kinesis stream as an external schema and create a materialized view for the stream data. Kafka (MSK) streams were supported too. After configuring the streaming data as a materialized view and loading some historical data, Redshift ML was used to build a XGBoost binary classification model for finding fraudulent transactions directly from the stream based on history data. Quicksight was then used for visualizing the data and to create a dashboard for the fraudulent transactions.


Also had some extra time between workshops and didn’t have any room to join nearby workshops or chalk talks as a walk-in, so went to the overflow content hub to briefly listen to some on-going sessions regarding EKS and Well-Architected Framework.
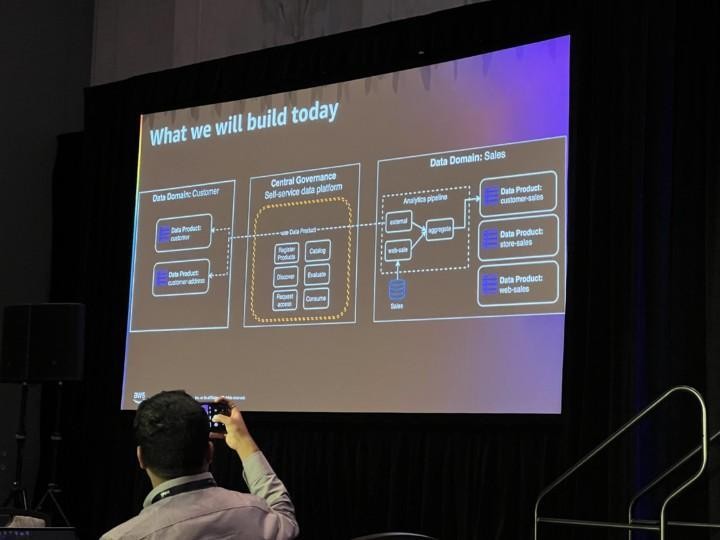
Workshop: ANT310-R – Build a data mesh with AWS Lake Formation and AWS Glue
Third and last workshop of the day focused on creating a quite complex data mesh setup based on AWS Analytics Reference Architecture using Lake Formation, Glue, CDK and Athena. Basically it was about sharing your own data set to a centrally governed data catalog with some Named/Tag based access control, and then accessing data from other accounts in the data catalog and combining them in queries using Athena.

Day 4 – Thursday
Hackathon: GHJ206-R – AWS Jam: Data & Analytics
Thursday morning started with some jamming instead of the Werner Vogels keynote that was happening at the same time. I glanced through the announcements from the keynote afterwards, and at least Eventbridge Pipes and Application Composer looked like interesting announcements.
This year there were also separate Jam events in addition to the Jam Lounge at the Expo area, where you could again complete different challenges during the whole week. The separate Jam events were only three hours long and teams of four competed in completing challenges while collecting points, similarly to this year’s GameDay. The Jam event I was most interested in was focusing on Data & Analytics, with challenges ranging from using Amazon Rekognition for facial image recognition to creating real time data analytics pipeline using Kinesis Data Streams and Kinesis Data Analytics Studio.
Luckily we got some very talented people in our team and we managed to complete almost all of the challenges. In the end, we finished first out of 50 participating teams and won the jam, and got some nice prizes for the effort too. It was a close competition and we managed to climb to the first position only in the very last minutes. Overall it was again an intense but fun experience and I managed to learn some new things regarding Sagemaker and Kinesis.


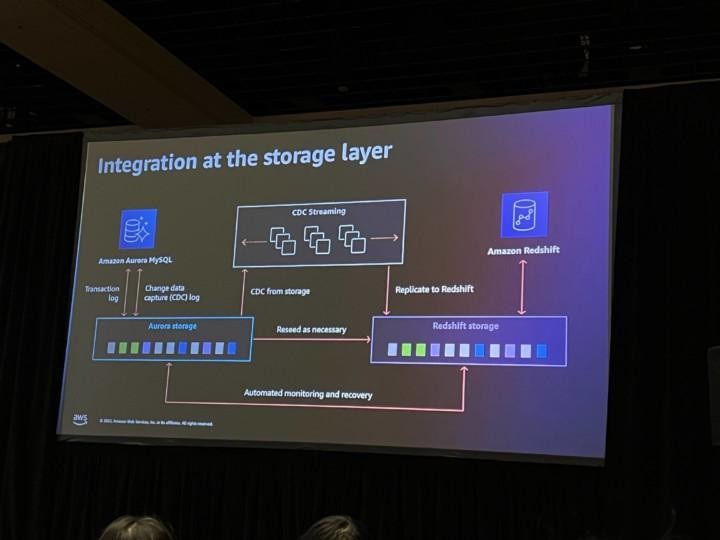
Session: DAT328 – Enabling operational analytics with Amazon Aurora and Amazon Redshift
There were a couple of new launch sessions added to the catalog after the keynotes, and this time I managed to get a seat in a couple of them. This session focused on the “zero-ETL” linking of Amazon Aurora and Amazon Redshift, where Aurora data will be automatically synced to Redshift without having to write any code. Basically you first needed to configure the integration using the Aurora console, and after that a new database was added to Redshift. After that, an initial export was done, CDC logging was enabled in Aurora and future changes will be synced automatically to Redshift to the newly created database. Currently the feature only supports Aurora MySQL and is available in preview only. It also seemed to lack any features for example for filtering the synchronization to use only a specific table or multiple tables in Aurora.

Workshop: CON402-R – Concepts to take your Kubernetes operations and scale to the next level
Last workshop of the week was focused on some best practices for scaling, security and observability inside EKS. It’s still quite cumbersome and slow to set up and the developer experience for Kubernetes still isn’t great. Cluster autoscaling was done using Karpenter, security was improved using IAM role based access control and pod level security, observability was done using CloudWatch Container Insights, OpenTelemetry and X-Ray.


Chalk talk: AIM341-R – Transforming responsible AI from theory into practice
Last chalk talk of the day was an interactive discussion on how to build responsible ML models, which aspects to take into account and how to make ML models more explainable. Would have liked to see more concrete examples on how to take all those things into account at the model level.


Thursday night was the re:Play night. Before the main event, there was also a AWS Certified Reception pre-party held at at a local bowling alley with also other fun and games. The main event took place at the nearby Festival Grounds and it was a great night filled with music, good food, drinks and meeting up with colleagues and new people, with Martin Garrix and Thievery Corporation headlining the two live music stages. This time it took quite a lot of time to get in and out of the party, as wait times for shuttles were long and traffic was slow.



Day 5 – Friday
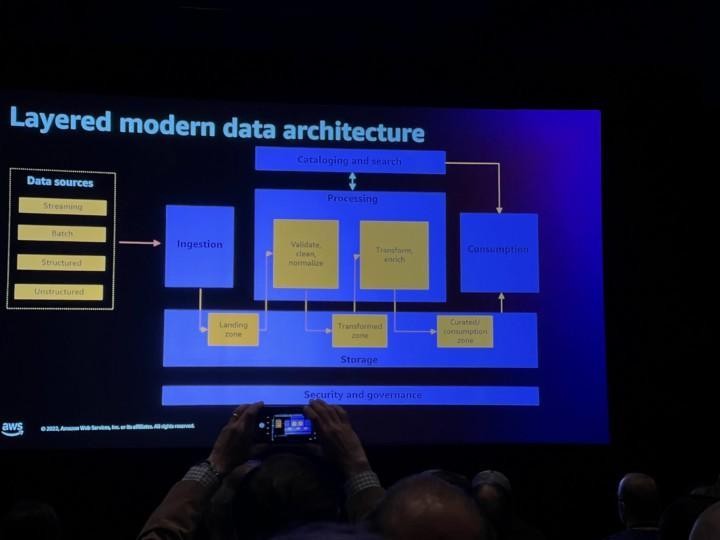
Session: ARC313-R -Building modern data architectures on AWS
Even though most of the content at re:Invent happens between Monday and Thursday, there were still a couple of sessions held on Friday morning too. This session was quite an information dump showcasing the multiple different AWS resources available for reference architectures for different data use cases and data platforms. Focused on six different layers: ingestion, storage, cataloging, processing, consumption and governance, with providing reference architectures and services to use for each of those. What also became clear with this session is that AWS has quite a lot of overlapping services these days, and the ones you should use depend quite a lot on your use case.

Session: API206 – Amazon EventBridge Pipes simplifies connecting event-driven services
Last session of the week was a brief overview and demo on the new EventBridge Pipes feature announced at Werner’s keynote on Thursday. It provides a simple way to integrate different AWS services without writing extra code. It looks pretty easy to use for simple use cases, where you might need to do some filtering for Kinesis streams or call a Lambda for transforming data, and then passing on the data to another service like SQS. They wanted it to work kind of like UNIX pipes, but for AWS services.


Conclusions
Overall, re:Invent 2022 was again a great learning experience and an exhausting but rewarding week. The days were long but there’s so much new to learn and things happening all the time that the week just flew by very quickly. It was great to finally attend a large conference after a couple of years of online-only events which just don’t work the same way in terms of learning and networking in my opinion. You could easily spend the whole week just in the expo area talking to different vendors and AWS staff, and still learn a lot without even attending the sessions.
Even though the conference is massive in its scale, almost everything worked smoothly without any major issues. I’d still agree with pretty much all of the conclusions from my previous blog post again, and re:Invent is definitely a conference worth attending even though it is a pretty big investment timewise. Hopefully I’ll get the chance to attend it again some time in the future.
Also keep an eye out for upcoming re:Invent blog posts in our Dev and Cloud blogs too.
