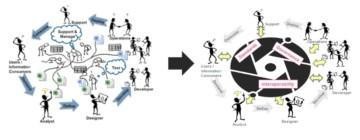
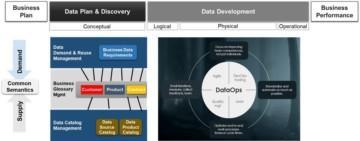
Metadata driven development realises “smart manufacturing” of data ecosystems – blog 3
This is the third part of the blog series.
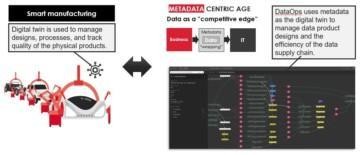
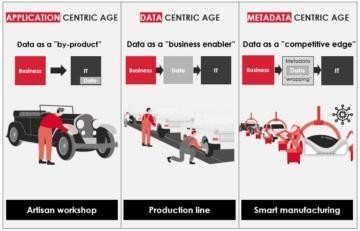
The 1st blog focused on the maturity model and explained how the large monolith data warehouses were created. The 2nd blog focused on metadata driven development or “smart manufacturing” of data ecosystems.
This 3rd blog will talk about reverse engineering or how existing data assets can be discovered to accelerate the development of new data products.
Business Problem
Companies have increasing pressure to start addressing the data silos to reduce cost, improve agility & accelerate innovation, but they struggle to deliver value from their data assets. Many companies have hundreds of systems, containing thousands of databases hundreds of thousands of tables, millions of columns, and millions of lines of code across many different technologies. The starting point is a “data spaghetti” that nobody knows well.
Business Solution
Metadata discovery forms the foundation for making fact-based plans, decisions and actions required to improve, leverage, and monetize data assets. Metadata driven development can use fact-based knowledge delivered by metadata discovery. It can leverage the most valuable data assets and provide delivery with dramatic improvement to quality, cost & speed.
How to efficiently resolve a “data spaghetti”?
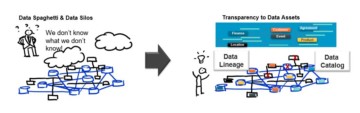
Are you planning changes in your architecture? Do you need a lot of time from the experts to evaluate the impact of the changes? Do you have a legacy environment that is costly & risky to maintain, and nobody knows well? How do you get an accurate and auditable blueprint of it to plan for changes?
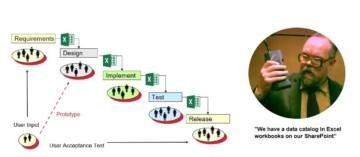
You may have experience in a data development project, where it took a lot of meetings and analysis to determine the correct data sources and assets to be used for the business use case. It was hard to find the right experts and then it was hard to find availability from them. Frequently there are legacy systems that nobody knows anymore as the experts have left the company. Very often legacy environments are old and not well documented.
A manual approach for discovering data assets means slow progress

Due to complexity, time and resource constraints manual documentation is likely to have a lot of pitfalls and shortcuts that introduce risks to the project. Manual documentation is likely to be outdated already when finished. It is inaccurate, non-auditable and non-repeatable.
Unfortunately, often the scale of the problem is not understood well. Completely manual approaches have poor chances to succeed. It is like trying to find needles in a haystack.
More automation and less dependency on bottleneck resources are needed for an efficient resolution of a “data spaghetti”. In our industry, this area is widely called data discovery. In this blog, we talk about metadata discovery because we want to bring attention to applying metadata driven automation to make data discovery more efficient and scalable.
A data discovery needs to start with an automated metadata discovery, which enables scale and can point the “hotspots” for scoping of the most critical data assets for doing data discovery.
In data discovery, we discover the data/content itself typically by doing data profiling. Data profiling will show if the data quality is fit for the intended usage. Data profiling is data intensive and analysing vast amounts of production data is not always feasible due to negative performance impacts. Data discovery can only be applied with the most critical data assets because security and privacy become bottlenecks in accessing many data sources.
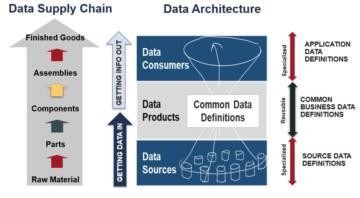
An efficient Data Supply Chain needs to be able to unlock value from existing data assets
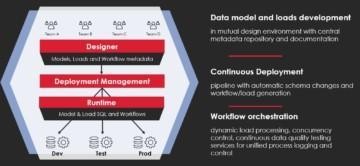
Data Supply Chain focuses on creation and improvement of data driven business solutions. It can be called forward engineering. The efficiency of Data Supply Chain is very dependent on knowledge of existing data assets that can be reused, or preferred data sources and data assets to be refined to meet the business data requirements.
Metadata discovery is used for cataloguing or documenting existing data assets. It can be called as reverse engineering as it is like discovering of an architecture blueprint of the existing data ecosystem.
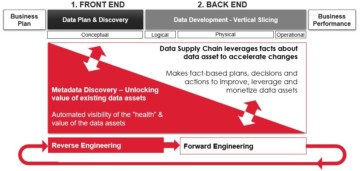
Even if the Data Supply Chain applies metadata driven development and the resulting data products are catalogued for future reuse, there is always a large set of data assets in the data ecosystems that nobody knows well. This is where reverse engineering can help.
Reverse engineering is a term that might not be that familiar to many of the readers. Think of a data ecosystem where many of the solutions have been created a long time ago. People who have designed and implemented these solutions – using forward engineering – have left the company or some of the few remaining ones are very busy and hard to access. The documentation is no longer up-to-date and not at the level that you would need. Reverse engineering means that you are lifting the “blueprint” of the ecosystem into a right level to discover the most valuable assets and their dependencies to evaluate any change impacts. Then you are carving out from the legacy environment the original design that has been the basis for data storages and data interfaces.
Automated metadata discovery can help you discover and centralize knowledge that the company may have lost.
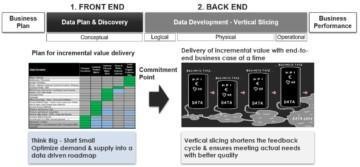
This interplay between reverse engineering – discovering As-Is data assets – and forward engineering – planning, design, and creation of To-Be data products – is always existing in data development. There are hardly any greenfield development cases, which solely focus on forward engineering. There is always a legacy data ecosystem that contains valuable data assets that needs to be discovered. It is very much needed in all cases where the existing data architecture is changed or with any migrations.
Think if you have an accurate blueprint of the legacy environment which will enable you to reduce migration scope, cost, and risk by 30%. That alone can justify solutions that can do automated metadata discovery. Many banks have used automated metadata discovery for documenting old mainframes that have been created decades ago. They have requirements to show data lineage to the regulators.
This blog is going to make a deeper dive into reverse engineering, which has not been in focus of the previous blogs. Reverse engineering would mean in manufacturing the same as doing migration of the supply chain into using a digital twin. This would involve creating an understanding of the inventory, product configurations at different levels the manufacturing process and tools to translate raw materials to finished goods. One such application is Process Mining. The key difference is that it is based on data – not metadata. Another key difference is:
Data is an exceptional business asset: It does not wear out from use and in fact, its value grows from reuse.
Data fabric – Emerging metadata driven capabilities to resolve data silos
The complete vision presented in these blogs matches very well with Gartner’s Data Fabric:
“A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets (reverse engineering) to support the design, deployment and utilization of integrated and reusable data across all environments (forward engineering)”
Gartner clients report approximately 90% or more of their time is spent preparing data (as high as 94% in complex industries) for advanced analytics, data science and data engineering. A large part of that effort is spent addressing inadequate (missing or erroneous) metadata and discovering or inferring missing metadata.
Automating data preparation to any degree will significantly increase the amount of analysis and outcome development (innovation) time for experts. Decreasing preparation time by just 8% almost doubles innovation time. (The State of Metadata Management: Data Management Solutions Must Become Augmented Metadata Platforms)
“Future is already here. It is just not evenly distributed.” By William Gibson. Gartner’s Data Fabric is still quite visionary and on top of the hype curve. There are not many products in the market that can realize that vision. The happy news is that we have seen some parts of the future. In this blog we can shed some light into this vision from our experience.
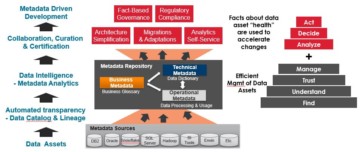
Data Dictionaries
Connectivity and automated technical metadata ingestion from variety of data sources
Metadata discovery starts by identifying prioritised data sources to be ingested based on business drivers. What is technical metadata? It is the metadata that has been implemented in a database or in a piece of software. Technical metadata is quite usually database, tables, and columns or files & fields. It is also the code that moves data from one table to another or from one platform to another.
Automated data lineage
Data lineage shows how the data is flowing through the ecosystem. It includes the relationships between technical metadata. Doing a data lineage requires that the solution can “parse” a piece of code to understand the input tables/files it reads from and then what is the output tables/files it writes into. This way the solution can establish lineage across different platforms.
Sometimes that the code is parametrized, and the actual code is available only at the run time. This means that the lineage is built using processing/query logs, which is called operational metadata.
Automated transparency – Augmented data cataloguing
Data cataloguing means that we can map business terms with technical metadata. Augmented data cataloguing means that we leverage Machine Learning (ML) based automation to improve the data cataloguing efforts. That can be achieved with both top-down and bottom-up approaches.
Bottom-up – Automated inferencing of relations between business terms and technical metadata. For example: “SAP fields are abbreviated in German. How to map an SAP field against an English vocabulary? You follow data lineage towards consumption where you find some more understandable terms that enable infer the meaning of a field in SAP”.
Solutions use ML for these inferences and the result gives a probability of the discovered relationship. When a data steward confirms the relationship then ML learns to do more accurate proposals.
Top-down – Semantic discovery using business vocabularies, data models & training data means that you have a vocabulary that you use for classifying mapping assets. The solutions use typically some training data sets that help to identify typical naming patterns of data assets that could match with the vocabulary. This method is used in particular for identifying and classifying PII data.
Analytics activates metadata – It creates data intelligence
Data intelligence term is a bit like business intelligence that has been used with data warehousing. Metadata management is a bit like data warehousing. There is a common repository to which metadata is ingested, standardized, and integrated.
Reaching transparency is not enough. There is too much metadata to make the metadata repository actionable. Activating metadata means leveraging analytics identify the most valuable or risky data assets to focus on.
Analytics on metadata will start showing the “health” of the data assets – overlaps, redundancies, duplicates, assets that nobody uses, or which are used heavily.
Gartner focuses on usage analytics, which is a very immature area with the products in the market. Usage analytics leverages Operational Metadata, which provides tracking and logging of data processing & usage.
Here are examples of use cases that can leverage usage analytics:
- Enables governance to focus on data assets that have the most value & risk for business usage
- Guides priority to assignment of term definitions, managing assets, classifications, quality, and usage
- High usage of private data brings focus of evaluation if data is used for the right purpose by the right people
- Enables ranking of application, databases, and tables value based on usage, for example when doing migration planning
- High usage is an indication that many users trust and find benefits of data – evaluate which of the optional data sources is a good candidate for golden source
- Enables to free up space – Clean up unused data – Enables to decommission unused applications, databases & tables
- Guides business & data placement optimization across all platforms – Identify the best use of platform or integration style for business needs based on data usage patterns & size
- Reveal shadow IT because it could show the data lineage from consumption towards data sources. There could be surprising sources being used by BI services. These in turn would be security & privacy concerns.
- Can also show to larger user community the most popular reports, queries, analytics, data sets
Collaboration, Curation and Certification
Collaboration around metadata driven Data Supply Chain has been discussed in the previous blogs. This chapter gives a short summary.
Centralizing knowledge for distributed people, data & ecosystems accelerates & scales the “Data Supply Chain”
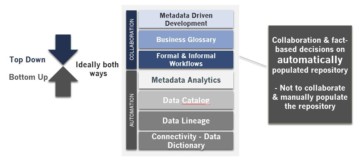
Bottom-up – Automation is key for being able to centralize vast amounts of knowledge efficiently.
The repository is populated using intelligent automation including ML, then the results provided (proposals with probabilities) by automation are curated by data stewards and the ML learns to do more accurate proposals. Analytics enables focus on assets that demand decisions, actions, and improvements.
Top-down – Business driven implementation is a must. Business buy-in is critical for success.
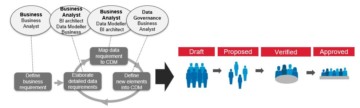
Creating transparency to data assets cannot be completely automated. It requires process, accountability, and behaviour changes. It requires common business data definitions, rules & classifications etc. It needs to be supported with a metadata solution that enables collaboration & workflows.
Top-down, business driven plan, governance and incremental value delivery is needed. Bottom-up discovery needs to be prioritized based on business priorities. Common semantics is the key for managing demand and supply of data to an optimized data delivery roadmap.
Getting people activated around the centralized knowledge is a key success factor. This can happen through formal accountabilities and workflows where people are leveraging fact-based knowledge to collaborate, curate and certify reusable data assets / products and business glossary. It can happen through informal collaboration, crowd sourcing & voting or in general by activating people in sharing their “tribal” knowledge.
Data Supply Chain leverages facts about data assets to accelerate changes.
Metadata discovery can help a lot with efficiency of Data Supply Chain. It makes fact-based plans, decisions, and actions to improve, leverage and monetize data assets. It enables to focus & prioritize plans and actions on data assets that have the most value & risk for business usage. Facts about “health” of the data assets can help to justify and provide focus for practical data architecture and management improvements:
- Who is getting value from which data? Which data can be trusted and should be reused?
- What data assets/data flows are non-preferred/redundant/non-used etc.?
- Which data assets should be cleaned-up/minimized, migrated, and decommissioned?
- What is the impact of the proposed changes?
Recommendation Engine
“The data fabric takes data from a source to a destination in the most optimal manner, it constantly monitors the data pipelines to suggest and eventually take alternative routes if they are faster or less expensive — just like an autonomous car.” Demystifying the Data Fabric by Gartner
Recommendation engine is the most visionary part of Gartner’s Data fabric. Gartner’s recommendation engine leverages discovered metadata – both technical and operational – and makes recommendations for improving the efficiency of the development of new data pipelines & data products.
Recommendation engine is like a “Data Lineage Navigator”.
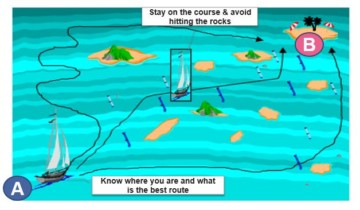
- It can analyse all alternative paths between navigation points A and B
- It will understand the complexity of the alternative paths – roads and turning points.
- Number of relationships between selected navigation points A and B
- Relationships & transformations are classified into complexity categories.
- Identify major intersections / turning points.
- Identify relationships with major transformations – these could contain some of the key business rules and transformations that can be reused – or avoided.
- Identify roads with heavy traffic.
- Identifies usage and performance patterns to optimize the selection of the best path.
Many of the needed capabilities for realizing this vision are available, but we have not run into a solution that would have these features. Have you seen a solution that resembles this? Please let us know.
Back down to earth – What should we do next?
This blog has provided a somewhat high-fly vision for many of the readers. Hopefully, the importance of doing metadata discovery using Data Catalogs has become clearer.
Data Catalogs provide the ability to create transparency in existing data assets, which is a key for building any data-driven solutions. Transparency creates the ability to find, understand, manage, and reuse data assets. This in turn enables the scaling of data-driven business objectives.
Data cataloguing should be used at the forefront when creating any data products on Data Lake, DW or MDM platforms. It is especially needed in the planning of any migrations or adaptations.
Maybe as a next step also your company is ready to select a Data Catalog?
The Data Catalog market is a very crowded market. There are all kinds of solutions. All of them have their strengths and weaknesses. Some of them are good with top-down and some bottom-up approaches. Both approaches are needed.

Data Catalog market is very crowded
We find quite often customers that have chosen a solution that does match to their needs and typically there are hard leanings with automation – especially with data lineage.
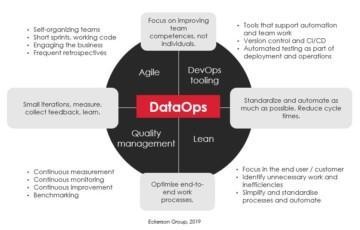
We at Solita have a lot of experience with Data Catalogs & DataOps. We are ready to assist you in finding the solution that matches your needs.
Learn more about Solita DataOps with Agile Data Engine (ADE):
Future-proof your data delivery http://www.agiledataengine.com/
Learn more about Solita experiences with Data Catalogs:
https://www.solita.fi/en/data-catalogs/
Series of blogs about “Smart Manufacturing”.
This blog is the 3rd and final blog in the series:
The 2nd blog focused on metadata driven development or “smart manufacturing” of data ecosystems.
This 3rd blog focused on reverse engineering or how existing data assets can be discovered to accelerate the development of new data products.