MLOps: from data scientist’s computer to production
Operationalizing data platforms, DataOps, has been among the hottest topics during the past few years. Recently, also MLOps has become one of the hottest topics in the field of data science and machine learning. Building operational data platforms has made data available for analytics purposes and enabled development of machine learning models in a completely new scale. While development of machine learning models has expanded, the processes of maintaining and managing the models have not followed in the same pace. This is where the concept of MLOps becomes relevant.
What is MLOps?
Machine learning operations, or MLOps, is a similar concept as DevOps (or DataOps), but specifically tailored to needs of data science and more specifically machine learning. DevOps was introduced to software development over a decade ago. DevOps practices aim to improve application delivery by combining the entire life cycle of the application – development, testing and delivery – to one process, instead of having a separate development team handing over the developed solution for the operations team to deploy. The definite benefits of DevOps are shorter development cycles, increased deployment velocity, and dependable releases.
Similarly as DevOps aims to improve application delivery, MLOps aims to productionalize machine learning models in a simple and automated way.
As for any software service running in production, automating the build and deployment of ML models is equally important. Additionally, machine learning models benefit from versioning and monitoring, and the ability to retrain and deploy new versions of the model, not only to be more reliable when data is updated but also from the transparency and AI ethics perspective.
Why do you need MLOps?
Data scientists’ work is research and development, and requires essentially skills from statistics and mathematics, as well as programming. It is iterative work of building and training to generate various models. Many teams have data scientists who can build state-of-the-art models, but their process for building and deploying those models can be entirely manual. It might happen locally, on a personal laptop with copies of data and the end product might be a csv file or powerpoint slides. These types of experiments don’t usually create much business value if they never go live to production. And that’s where data scientists in many cases struggle the most, since engineering and operations skills are not often data scientists’ core competences.
In the best case scenario in this type of development the model ends up in production by a data scientist handing over the trained model artifacts to the ops team to deploy, whereas the ops team might lack knowledge on how to best integrate machine learning models into their existing systems. After deployment, the model’s predictions and actions might not be tracked, and model performance degradation and other model behavioral drifts can not be detected. In the best case scenario your data scientist monitors model performance manually and manually retrains the model with new data, with always a manual handover again in deployment.
The described process might work for a short time when you only have a few models and a few data scientists, but it is not scalable in the long term. The disconnection between development and operations is what DevOps originally was developed to solve, and the lack of monitoring and re-deployment is where MLOps comes in.
How can MLOps help?
Instead of going back-and-forth between the data scientists and operations team, by integrating MLOps into the development process one could enable quicker cycles of deployment and optimization of algorithms, without always requiring a huge effort when adding new algorithms to production or updating existing ones.
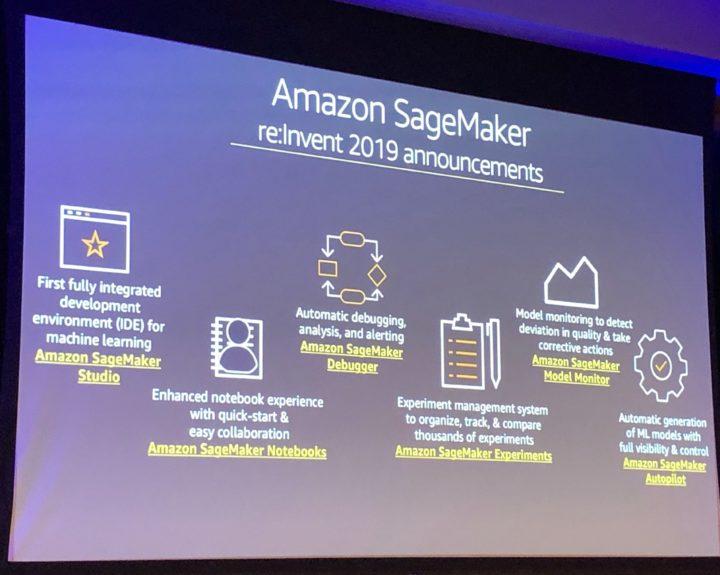
MLOps can be divided into multiple practices: automated infrastructure building, versioning important parts of data science experiments and models, deployments (packaging, continuous integration and continuous delivery), security and monitoring.
Versioning
In software development projects it is typical that source code, its configurations and also infrastructure code are versioned. Tracking and controlling changes to the code enables roll-backs to previous versions in case of failures and helps developers to understand the evolution of the solution. In data science projects source code and infrastructure are important to version as well, but in addition to them, there are other parts that need to be versioned, too.
Typically a data scientist runs training jobs multiple times with different setups. For example hyperparameters and used features may vary between different runs and they affect the accuracy of the model. If the information about training data, hyperparameters, model itself and model accuracy with different combinations are not saved anywhere it might be hard to compare the models and choose the best one to deploy to production.
Templates and shared libraries
Data scientists might lack knowledge on infrastructure development or networking, but if there is a ready template and framework, they only need to adapt the steps of a process. Templating and using shared libraries frees time from data scientists so they can focus on their core expertise.
Existing templates and shared libraries that abstract underlying infrastructure, platforms and databases, will speed up building new machine learning models but will also help in on-boarding any new data scientists.
Project templates can automate the creation of infrastructure that is needed for running the preprocessing or training code. When for example building infrastructure is automated with Infrastructure as a code, it is easier to build different environments and be sure they’re similar. This usually means also infrastructure security practices are automated and they don’t vary from project to project.
Templates can also have scripts for packaging and deploying code. When the libraries used are mostly the same in different projects, those scripts very rarely need to be changed and data scientists don’t have to write them separately for every project.
Shared libraries mean less duplicate code and smaller chance of bugs in repeating tasks. They can also hide details about the database and platform from data scientists, when they can use ready made functions for, for instance, reading from and writing to database or saving the model. Versioning can be written into shared libraries and functions as well, which means it’s not up to the data scientist to remember which things need to be versioned.
Deployment pipeline
When deploying either a more traditional software solution or ML solution, the steps in the process are highly repetitive, but also error-prone. An automated deployment pipeline in CI/CD service can take care of packaging the code, running automated tests and deployment of the package to a selected environment. This will not only reduce the risk of errors in deployment but also free time from the deployment tasks to actual development work.
Tests are needed in deployment of machine learning models as in any software, including typical unit and integration tests of the system. In addition to those, you need to validate data and the model, and evaluate the quality of the trained model. Adding the necessary validation creates a bit more complexity and requires automation of steps that are manually done before deployment by data scientists to train and validate new models. You might need to deploy a multi-step pipeline to automatically retrain and deploy models, depending on your solution.
Monitoring
After the model is deployed to production some people might think it remains functional and decays like any traditional software system. In fact, machine learning models can decay in more ways than traditional software systems. In addition to monitoring the performance of the system, the performance of models themselves needs to be monitored as well. Because machine learning models make assumptions of real-world based on the data used for training the models, when the surrounding world changes, accuracy of the model may decrease. This is especially true for the models that try to model human behavior. Decreasing model accuracy means that the model needs to be retrained to reflect the surrounding world better and with monitoring the retraining is not done too seldom or often. By tracking summary statistics of your data and monitoring the performance of your model, you can send notifications or roll back when values deviate from the expectations made in the time of last model training. 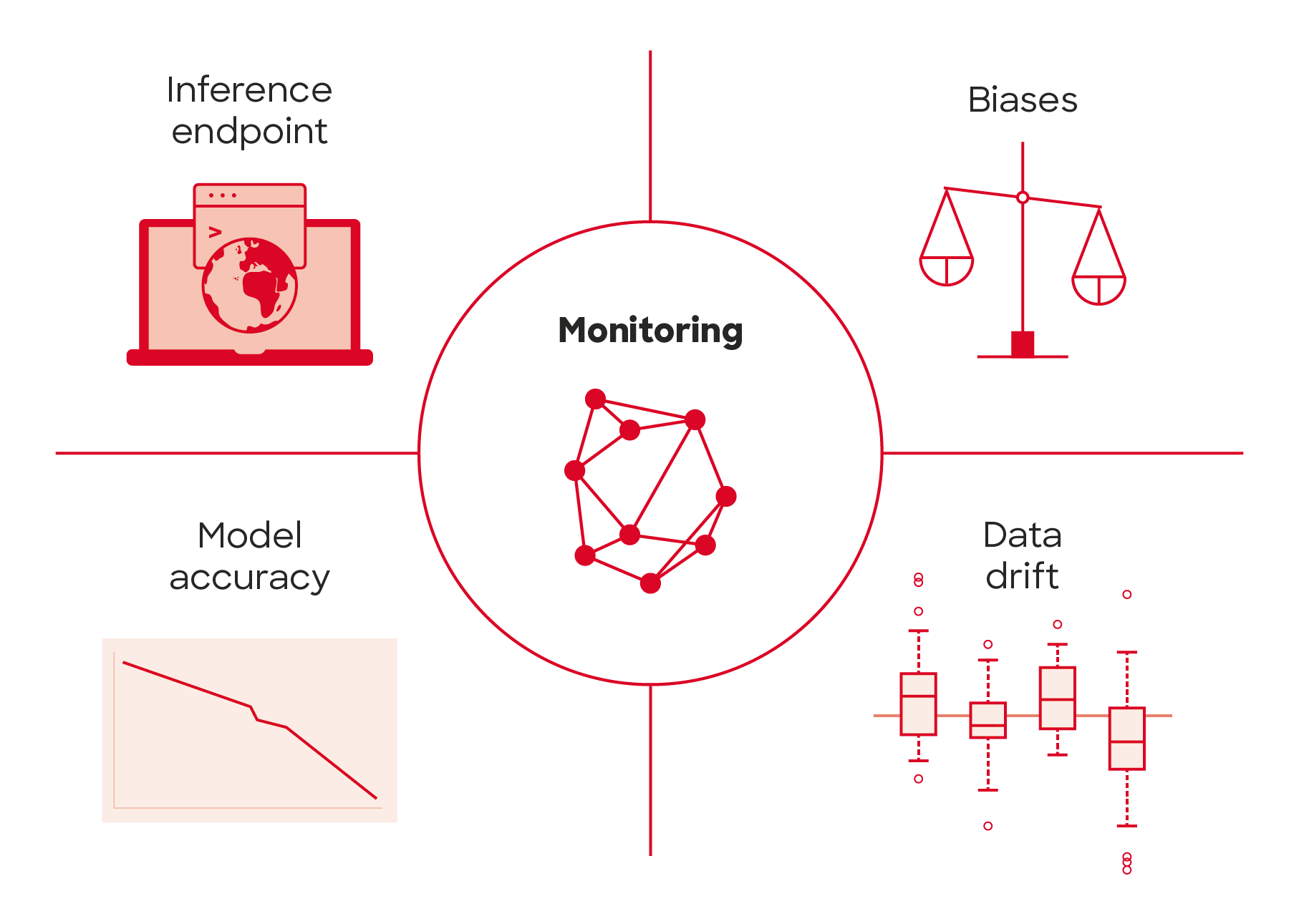
Applying MLOps
Bringing MLOps thinking to the machine learning model development enables you to actually get your models to production if you are not there yet, makes your deployment cycles faster and more reliable, reduces manual effort and errors, and frees time from your data scientists from tasks that are not their core competences to actual model development work. Cloud providers (such as AWS, Azure or GCP) are especially good places to start implementing MLOps in small steps, with ready made software components you can use. Moreover, all the CPU / GPU that is needed for model training with pay as you go model.
If the maturity of your AI journey is still in early phase (PoCs don’t need heavy processes like this), robust development framework and pipeline infra might not be the highest priority. However, any effort invested in automating the development process from the early phase will pay back later and reduce the machine learning technical debt in the long run. Start small and change the way you develop ML models towards MLOps by at least moving the development work on top of version control, and automating the steps for retraining and deployment.
DevOps was born as a reaction to systematic organization needed around rapidly expanding software development, and now the same problems are faced in the field of machine learning. Take the needed steps towards MLOps, like done successfully with DevOps before.