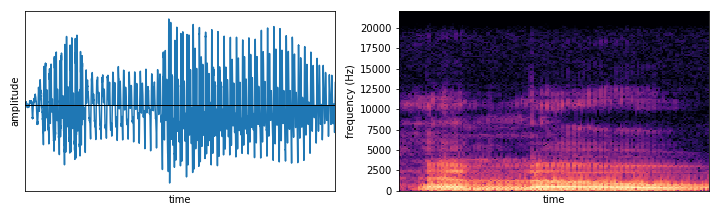
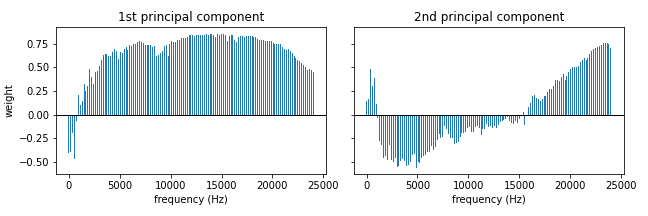
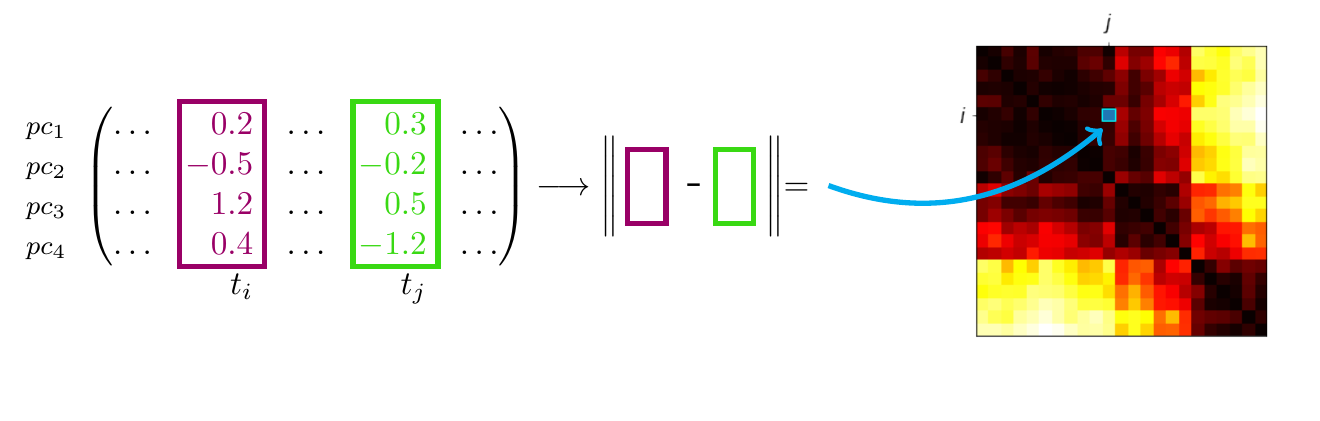
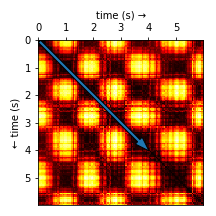
Timeseries forecasting often requires significant mathematical knowledge and domain experience. This area of machine learning is often only accessible to experts, however, Amazon Forecast provides a simple and intuitive interface for creating complex machine learning models.
Timeseries forecasting is the process of looking at historical data to make predictions about the future. Companies can use these predictions to extract actionable insights that drive innovation. Often, the mechanisms behind the transformation of raw data into business value is a mystery to non-specialists. This is because timeseries forecasting requires expert knowledge of algorithms and mathematical concepts such as calculus. This is a domain reserved for the highly trained specialists, often not accessible to the average user. However, with the development of Amazon Forecast this could be changing.
Amazon Forecast is a fully managed service that simplifies the process of timeseries forecasting by hiding the inner complexity from the users. The user simply has to provide an input data, Forecast then automatically applies and selects the most optimal machine learning algorithm for the data to generate accurate predictions with little to no user intervention. This system is known as a ‘Black Box Method’, where a user can conduct complex modelling tasks without worrying about the low-level calculus and algorithms.
This movement of machine learning from experts to general users marks a significant paradigm shift known as AutoML (Automatic Machine Learning).
Within this blog Amazon Forecast will be explored from the perspective of a non-expert general user to assess how easy it is to get started producing accurate future predictions. In other words, can someone who is not a professional machine learning specialist produce professional models?
What we will predict
In this hypothetical scenario we work for an electricity provider and have been tasked with building a model to predict future electricity consumption for our customers. The input data we have been provided contains measurements for electricity consumption (Kw) every hour for 370 different clients from January 2014 – November 2014. This dataset contains 2,707,661 observations. We will build a model to predict the electricity consumption for the 1st of October 2014, so 24 hours into the future for every customer.
Creating the electricity forecast
Unfortunately, Forecast is not able to clean and prepare your input data, you must ensure the data is prepared beforehand. This is the only technical step that is required in the forecasting process. In this instance, we prepare the dataset to match the schema requirements of Forecast as shown in the table below. Once prepared the data must be stored in an S3 as a CSV.
Client
Timestamp
Consumption
Client_1
2014-01-01 01:00:00
23.64
Client_0
2014-0101 02:00:00
9.64
As a general user we can achieve everything we need to generate a forecast within the Forecast Console. This is a no-code user interface in the form of a Dashboard. Within this dashboard we can manage all aspects of the forecasting process, this process is implemented in 3 easy steps:
First, you import your Target time series data. This is simply the process of telling Forecast where to find your prepared data in S3 and how to read the contents (schema).
Next, you use this Target time series to create a predictor. A predictor is a Forecast model trained on your timeseries. This is where the AutoML aspects of Forecast are truly utilised. When training a predictor in a typical timeseries forecast, the user would need to identify the optimal algorithm to train the model and then optimise this model. Within Forecast, all of these steps are done automatically using back testing. Back testing is the process of retaining a portion of the training data to train on all the algorithms to find the best fit.
Finally, with the model trained, we can generate a forecast. This is as simple as a few clicks on the dashboard. This will generate future predictions of energy consumption for every hour for every customer.
Now, with zero coding or expert input we have generated an advanced forecast utilising cutting-edge deep learning machine learning algorithm. If it appears very simple, that’s because it is. The dashboard was designed to be simple and easy to use. For more advanced users Python can be used to connect to Forecast where you gain significantly more control over the process. But as a general user such control is not necessary.
Visualise and export the electricity consumption predictions
For this section we will visualise the forecasted predictions for customer 339, found in the graph below. As we actually have the real observed values for the 1st of October 2014, we can compare our predictions with the actual observed electricity consumption.
In the graph the darker blue line represents the real values. We can also see a red line and a light blue area. This blue area is known as the 80% confidence interval, indicating that we are 80% confident that the real value will lie somewhere within this area. The red line, p50 value (median forecast) can be considered as an indication of the ‘most likely outcome’.
As we can see, our forecast appears to be very accurate in predicting the electricity consumption for this customer, with the predicted values closely following the observed values. In practice, these forecasts could be used in a variety of ways. For example, we could share this forecast with the customer, who can then adjust their consumption patterns to reduce energy usage during peak hours and thus lower energy bills. For the energy provider, these forecasts could be used in load management and capacity planning.
Conclusion
The main purpose of Forecast and AutoML is to allow non-experts to develop machine learning models without the required expertise. AutoML also enables experienced data scientists by reducing time spent optimising models. Forecast achieves both, as I, a non-expert, was able to develop an advanced forecasting model without any interaction with the complex underlying mechanisms. It is clear Forecast extends the power of time series forecasting to non-technical experts, empowering them to make informed decisions from machine learning insights.
EU regulation called AI Act is fast approaching and will regulate how artificial intelligence is used in the EU. This blog post looks at what each organisation should be doing to be prepared in time for this.
Kirjoittaja:Satu Korhonen ML engineer, who is focused in creating safe, secure, and sustainable ML solutions that bring long-term business value to organisations.
The EU regulation on ethical and robust AI solutions called the AI Act is fast approaching. The idea behind this regulation is to enable the development of artificial intelligence while ensuring that human rights are considered and accounted for in the development. The current estimated timeline is to reach an agreement about the content of the AI Act with all member states by the end of this year and have it in effect soon after. The broad strokes of this regulation are already known. My advice for all organisations is to start preparing for this now.
Two ways to prepare for the AI Act
The first thing is to become educated on what this regulation is and make sure everyone in your organisation creating, developing, and deciding on AI projects is also aware of it. This relates to the reasons behind it, the broad strokes of the regulation itself, and how to prepare for it.
The second aspect focuses on preparing the AI solutions in the development pipeline and in production to comply with the regulation as well as also looking at the development culture in the organisation so new AI solutions can be compliant by design. We at Solita have developed a client-tested tool and framework to help with this.
I will also look more closely at both topics next.
Get educated: how we got here and where’s here?
News of companies running into ethical and legal problems with artificial intelligence has made headlines for years with increasing numbers. In 2016 The COMPAS risk assessment recidivism algorithm used by the U.S. court system was assessed to be very biased. Microsoft unveiled the Tay chatbot only to take it offline within 16 hours due to inflammatory and offensive tweets. In 2018 Amazon shut down their recruitment AI for sexist results and in 2019 Apple credit card ran into problems when it offered smaller lines of credit to women than to men.
These and similar issues as well as the rise in popularity of this technology quickly put this topic on the tables of regulators to regulate AI in a way to make it align with legal, ethical, and safety guidelines in the European Union.
The rise in popularity of generative AI, with f.ex. Midjourney and ChatGPT, has required discussions on the content and wording of the AI Act late in this process.
In June 2018 the European Commission established an expert group to create Ethics Guidelines for Trustworthy Artificial Intelligence. The group emphasized three key components for the development of AI. Firstly, AI solutions should be lawful, adhering to existing laws and regulations related to, for instance, product development, data usage, and discrimination. Secondly, AI should be ethical, respecting principles of human autonomy, prevention of harm, fairness, and explicability. Lastly, AI systems should be technically robust, safe, and secure, and consider their social environment. Particular attention should be given to vulnerable and historically disadvantaged groups and situations characterized by power or information imbalances.
In April 2021 the European Commission proposed the first EU regulatory framework for AI. Their priority was to make sure that AI systems used in the EU are safe, fair, transparent, traceable, non-discriminatory, overseen by people, and environmentally friendly. This proposed framework is the basis of the AI Act. Since June 2023, the regulation has transitioned to the phase where EU countries are forming the final wording of the regulation.
General principles of this regulation is that all AI systems are safe, protect privacy, transparent, and non-discriminate, as well as having proper data management.
The plan is to reach an agreement by the end of this year with Generative AI causing plenty of discussions this spring.
The regulation takes a use case-based approach categorizing AI applications into four risk levels, which are low, limited, high and unaccepted risk. Low-risk applications, such as email spam filters and predictive maintenance systems, are not heavily regulated but still encouraged to be robust. Limited risk applications, including chatbots, are subject to transparency obligations. Users must be aware that they are interacting with AI and should have the option to discontinue use while at the same time receiving the service.
Generative AI can be at different risk levels. If used in low-risk application, it needs to be transparent in disclosing AI-generated content for users, prevent the generation of illegal content, and publish summaries of copyrighted data used in training. Currently, the larger foundational models still somewhat lack these aspects as Stanford University discovered earlier this year. The companies providing general-purpose foundational models AIs like GPT have requirements stated if they are to operate within EU.
High-risk applications are such that the system poses a significant risk of harm to the health, safety, or fundamental rights of natural persons or the environment and are subjected to strict obligations throughout their lifecycle. These use cases are defined as AI systems in law enforcement, migration and border control, recommender systems of large online platforms, justice administration and democratic processes, education, employment, essential private and public services, and critical infrastructure. These systems require comprehensive risk assessments and mitigation, data governance practices, transparency and provision of information about it being an AI system. They also require a fundamental rights impact assessment and monitoring environmental impact.
The unaccepted risk and hence prohibited use cases pose clear threats to people’s safety, livelihoods, and rights. Examples include biometric classification of individuals based on sensitive characteristics, real-time remote biometric identification and retrospective identification from recordings, proactive policing activities, emotion recognition systems in f.ex. law enforcement and education, and establishing large-scale facial recognition databases. These will not be allowed within the EU.
Get prepared: finding and fixing potential issues
While education on the regulation is still happening, the review of AI use cases in development and production should take place. This involves all solutions that are being designed, are in development, or are in production. For each, an assessment should be done on their risk level according to the regulation and the priority for business of each solution. This is a fairly simple operation of having current the AI Act guidelines and looking through each use case to which category they are most likely to land in. Legal advice can be sought to offer guidance in cases that could be seen one way or the other. For solutions in production that are already GDPR compliant and not high-risk, the chances are that required chances are small.
After each solution has been classified to a risk level, the characteristics of each solution need to be investigated regarding the AI Act risk assessment classification. We have developed a customer-tested framework and tool for this at Solita. The list of things to look at is very different in a low-risk application to that of a high-risk application. I recommend starting with the business-critical applications first. The idea here is to foresee possible issues with complying with the regulation and react to them in descending order of priority.
One thing each organisation should consider. If you are using an AI system offered from outside the EU, but used inside the EU, it’s advisable to prepare for some interruption of service. Systems offered outside the EU might not all choose to comply with the regulation but will instead opt out and not offer their services inside the EU, or they might take their service offline while building compliance with the new regulation. The more critical the AI system is to the company, the more important it is to take this into account in time.
Review the development and maintenance pipeline
While reviewing each use case is important, it is important also to start building or strengthening processes that ensure compliance with the regulation now and in the future so AI solutions can be compliant by design. Our framework serves this process well. The tool allows a company to look at their AI development processes, as well as each model, to easily document the current ways of working, identify any issues needing further development, and a way to document progress against identified gaps. We are closely following the development of the regulation and developing the framework accordingly.
Build a roadmap and implement it
Once use cases have been identified and the ways of working assessed, the next phase is to develop a roadmap in order of priority to fix any identified issues before they cause problems. Our framework helps with this. In limited to no-risk use cases it is useful to already start building transparency of an AI model being used and start building opt-out methods if not already present. Also, and especially in high-risk use cases, building a method of redress and obtaining explanations of the decisions made by the AI system, is very important.
For any use case that can be considered high risk, a more thorough investigation should be already started that documents carefully the system and its development and provides users and affected parties with the necessary information on the solution. The Solita framework makes this process easier. For the forbidden use cases, if they exist, it is necessary to think about the end of life of these solutions.
Act now
The AI Act is coming, and it is coming soon. I recommend starting to prepare for it now, and, if necessary, seek out ML engineers, responsible AI experts, and designers with thorough knowledge and understanding of this topic area to help to educate staff and build a roadmap for compliance with each AI solution in the development pipeline or in production. When the regulation comes into effect, I suspect many organizations will wake up to the need to do something as they did when GDPR came into effect and consultancies capable of helping them will be fully booked quickly. As the main parts of this regulation are already well known, my advice is to start preparing for this now. We’re always happy to help with client-tested tools to do so.
Testing is always a crucial part of any Power BI development. When developing content to be embedded there are some different test angles to consider like what type of test users are needed, how RLS works in UI or what might look different after embedding. Testing is also something that needs to be done after go live and you need to have clear understanding with other stakeholders about the production release process.
In my blog seriespart 1 I described some experiences from my embed projects and issues to consider, like how to identify restrictions in Power BI to meet customer brand and functionalities not supported when content is embedded, to be prepared to manage expectations and agree what areas in the solution are developed with Power BI. The part 2 was dedicated to describe collaboration with stakeholders. This last part includes my experiences from testing and some production use considerations.
Testing, testing, testing
I am always a bit surprised how much time testing takes. When developed content to be embedded, noticed that I needed to reserve even more time for testing because testing need to be done in three different places:
Power BI desktop: data validation, functionalities, layout, performance (use also DAX Studio)
Power BI Service: gateway (if needed) and connections, monitor data refresh, Service principal access rights
UI/customer portal DEV and/or TEST environments: Same kind of testing needed as in Desktop as you might find some differences in positions or how e.g Header Icons are positioned or if there appear scroll bars need to be removed etc. If your solution will have a lot of users, then one big part of the testing is performance and load testing. Testing just mentioned requires other stakeholders input.
In “traditional” Power BI development you would do testing in the Desktop and then in the Power BI Service and maybe a bit less time is needed.
Noticed that testing needs to be done using different test users with different access rights. I asked for the different type test users and this way was able to make documentation including the information which features, reports and data each user should see. So, ensure you have all needed test users available to test different use cases.
As in traditional Power BI content development I needed to test the reports thoroughly to ensure that they work correctly and meet the user’s and brand requirements. In my projects I was able to use real production data, but of course sample test data can be used as well. With my test users I was able to simulate different scenarios and test the report’s performance under different conditions. And of course customer testers were also doing their part in the testing.
RLS testing
In my experience one of the most time consuming testing was access/visibility. Row Level Security (RLS) setup needs special attention and needs to be tested first in the Desktop and after this with many different users in the UI. This type of testing is different from the traditional Power BI Service testing/functionalities.
I also experienced that in these type solutions the RLS needs seem to change during the project. And as needs changed, I needed to do testing again for something that was already once approved.
Ways of working in testing
In my projects the Test manager/coordinator enabled a more effective adoption of testing practices. For Power BI developers working together with a Test manager/coordinator will probably mean that you are able to concentrate more on development and changes rather than sitting in testing sessions. Ensure that you have smooth communication with the Test manager/coordinator. Also consume time to show how testing should be done and what is relevant for you in test findings/notes.
Would say that consider carefully if it is useful to let the Testers do testing in Power BI Service. End user experience will not be the same in UI and testers might report wrong results. In my experience the better approach was to enable in the project a testing UI environment as soon as possible. And it is also important to get the Testers to do testing during the development phase and not just at the end of the project. This way I was able to get feedback from the tester in the early phase of the report development.
I noticed that the change and correction need to be reported in a structured way. This way I was able to see the “big picture” and plan the order and the time of the changes with other Power BI developers and UI developers. So, ensure to use clear versioning practicalities and communication channels. Otherwise you might end-up in a situation where another developer is overwriting a version and some changes are lost. The Deployment Pipeline feature could help to monitor the situation (and coming Git integration within Fabric might give even better results).
Experiences during the testing
Gathered some of my experiences from testing in my projects. Maybe these help you to tackle some obstacles beforehand.
Testing was divided into three areas: data validation, visual layout and Power BI functionalities and UI related report functionalities. I spent most of my time doing data validation like investigating source transactions and exception handling with DAX and testing different DAX solutions to meet business calculation requirements. Also gathering business logic for the calculations from different business and data owners took time.
During report development and testing, the Business owners realized there are more requirements to restrict data visibility to different types of users. RLS definitions changed many times and caused more development work and re-testing.
Noticed that the Testers needed some time to learn how testing is done and especially how to report findings. Learned that it was a good practice to have testing findings in small / many tickets rather than one huge one.
Sometimes the Testers forgot the scope of the project. So, I needed to actively ask the Business owner and Project manager what findings will be fixed and what can be added to future development lists.
The Test manager/coordinator checked frequently with the Testers and Business owner the status of test findings. We also had weekly sessions to check with the Business owner the situation and this way minimized risk of misunderstandings. Would recommend this type of way of working.
Before the Testers started the testing of a new report, we had a demo session. This way I was able to demo Power BI features/functionalities they were not so familiar with. In my experience this type of session is good to have also in the beginning of UAT testing.
Last learning for me was that having a UX Designer in the project helped to notice mistakes in layouts, colors, fonts etc.
Performance and load testing
One big part of testing might be performance testing and load testing. In many cases your reports probably work ok and the memory and CPU available within Premium capacity is enough. But if embed project reports are used by many users (thousands), data amounts are large, there are complex calculations and/or many visuals on one report page, you need to start planning the performance and load testing. Questions to the Business owner
How many users will there be?
Are there some peak moments when there are many concurrent users?
How much history data is needed on the reports?
Is it possible to reduce the amount of visuals in a report page?
Could you provide detailed level information about the business logic calculation needs?
The Business owner might not be able to answer these questions right away, but if you have heard any hints that some of the previous issues are relevant, it is best to include the performance and load testing to the project.
Production use considerations
As in all projects, you need to plan go live tasks and times. In my experience in these types of projects, it is worth considering phased production use start or if a certain pilot user group could be used. This way both customer and development team can get new improvement proposals from new users before a wide audience starts to use the reports.
You also need to discuss with the Business owner and Power BI Admin who is taking the ownership of support and alerts. If you are using e.g., dev, test and prod, maybe the support can be divided like this:
First hand support for end-users, inhouse or outsourced support team takes care
Support requests like user right problems
Owner of prod environment
Probably there is a separate tool in use within the customer to handle support tickets
“Deeper level” support where support team can contact Power BI developers
Support request requiring deep understanding about Power BI development, model, source tables etc.
Owner of dev and test environments
Probably you have your own organization support ticket tool
This is just one proposal and companies might have very different support models.
Testing in production
Another angle in production use is testing the changes and corrections. Remember to agree how future development and release is done. Consider following:
What is the timetable for releases?
Who is involved in testing? How do testers report results?
Where, how and who should be informed about the new features, reports, error corrections etc.?
How are changes documented?
Noticed that the planning of production use required many parties and many sessions. My role was more to give insights about the technical possibilities but my Project managers, Power BI admins and Business owners were dealing with other stuff like agreements.
Key takeaways
We were able to resolve complicated RLS needs where the authentication tool was not Microsoft Azure AD. This proved that Power BI is a suitable product to be used in solutions where the goal is to embed reports to your customer portal.
With ensuring enough time for testing these type of projects succeed.
Most important key takeaway was to understand how collaboration with other stakeholders ensures the best end results. Having a team around you with many skills, helps to resolve problems. Luckily in my company I was able to work with different kinds of talented people.
Development work for a customer portal is not something you can do alone. You need a project team with many skills to achieve the best result. When Power BI content is developed to be embedded, you need to collaborate with Power Service or UX designer, BI admin, Software developer, Business owner, Solution architect, Data Engineer, Project manager and Test manager.
In my blog series part 1 I described some experiences from my embed projects and issues to consider like how to identify restrictions in Power BI to meet customer brand and functionalities not supported when content is embedded, to be prepared to manage expectations and agree on what areas in the solution are developed with Power BI. This second part I dedicated to collaboration as I see it being one of the most important areas in a project where Power BI reports are embedded in a customer portal.
Tight collaboration with stakeholders
This type of development work is not done by individuals. You need to collaborate tightly with different stakeholders. Collaboration with different stakeholders can be very intensive in different phases of the project.
For example, with a UX designer, you need to use more time at the beginning of the project to plan and test layouts, json file etc. Later you will need her/his advice or opinions randomly in smaller details occurring in agile development work of individual reports. And then for example with Power BI admin your collaboration is tight in the beginning to get all accesses, connections etc. and then again at the end of the project when planning go-live and support processes.
How to make use of Service/UX designers expertise and feedback
Make sure you understand Service/UX designers’ drafts (if available) and ensure these issues are discussed:
Discuss with her/him about possible problems you recognize, like some planned layout plans are hard to accomplish in Power BI.
If a customer portal will be used via mobile phone, check and test together what is possible and what might be hard to achieve within Power BI.
Together test in Power BI different solutions to meet the brand requirements, but keep in mind also the usability and accessibility point of view.
Together use the time to create a json -theme file and test the import.
During the agile report development, I collaborated with Service/UX designer to get feedback or suggestions to resolve smaller problems in visual positions, sizes or text sizes. After I had published a report for testing, the Service/UX designer looked at it “with fresh eyes” and usually noticed something I had missed.
What insight you need from Power BI admin
Ask from customer Power BI admin the options and possible boundaries, like
How are they using Power BI Service?
What license model is in use?
Who can create gateway connections if needed?
Who can create Workspaces?
Does the customer allow custom visuals?
Is it ok to use the deployment pipeline process?
Will there be a dedicated premium tenant available?
Where should backup .pbit files be stored?
Overall make sure you inform the Power BI admin about the progress of the development and ask for help well in advance. I also included my Solution Architect in these discussions.
In the end part of the project, I involved the Power BI admin to plan and decide on go-live tasks and support processes.
How to pair work with Software Developer
As Power BI content, report page/pages or individual visuals will be embedded in a UI/customer portal you need to test and try different solutions together with Software developers doing the embedding. Consider these:
Clearly communicate the requirements for the Power BI embedded report to the software designer. Discuss the design and branding requirements, as well as any technical specifications, such as data sources and performance requirements.
Agree on the storage location for Power BI reports and visual’s IDs and ensure a clear communication process of updates.
Check how the report page fits into the UI and what is the best Page View option to be used.
Ensure you use the correct canvas size according to brand, but also verify that it is the best from the point of view of the report users.
Decide what areas are implemented in UI and what in Power BI. For example, a report header might be easier to maintain on the UI side if changes occur, Power BI page/sheet names need to be hidden in UI or some pre-selections in a date range are easier to do in UI.
If a customer portal will be used via mobile phone, check and test together the best Mobile layout for each report.
Review the report with the software designer and iterate based on testers’ feedback, both the technical and design aspects of the report.
During the testing phase, I noticed that sometimes for testers it was hard to recognize if the “bug” was related to Power BI or to UI. It helped to have weekly sessions with Business owner and testers. With the Software designer, I was able to smoothly discuss these in our daily sessions and/or in other communications tools.
How to ensure communication flow with Business owner
With the Business owner ensure the following:
You both understand report requirements and specifications are clear.
Reserve enough time and sessions with the customer to explore the old solution/customer portal.
Show the first draft of the new report version in the early phase to get feedback.
Ensure to have a communication channel open to ask questions and clarifications. Many times business owners forget to tell all the needed functionalities and during the development, you need to get more insights.
In my experience, it was a good practice to have the demo sessions for each report during the whole development phase in the project. In the testing phase, weekly sessions with the Business owner helped to keep track of the test results, “bug” reports and corrections.
Keep in mind other stakeholders
Some stakeholder cooperation is quite typical in all reporting-related development projects, so just briefly mentioning these:
Make sure you have a solid communication channel with the Customers data owner/developer, who understands the database, data source structure and business logic. If you are able to utilize a data warehouse, you have more possibilities to discuss with e.g., the Data Engineer which calculation could be done there or what to include in the source views.
If an old customer portal exists make sure you have contact persons to investigate and ask about the calculations logic done with the old tool. Sometimes contact can be a customer internal employee or another vendor’s representative.
Make sure to keep the Project manager and Solution architect aware of the technical obstacles you are facing or problems with testing resources. These stakeholders usually take care of the communication with other stakeholders like the customer’s management or testers.
Have recognized two other stakeholders, the Test manager/coordinator and Tester, but explain some insight related to them in the last part of my blog series.
I’ve collaborated with all stakeholders described above in my projects but this is not a complete list. For example, your customer organization model affects the number of stakeholders you need to collaborate with.
In the last part of my blog series I will tell you about my experiences in testing and support process planning for this type of solution.
Tableau Conference (TC23) was held last week in Las Vegas and once again it shed light on Tableau’s long term roadmap but also provided some concrete examples of features coming in the next releases. Tableau jumped on the generative AI bandwagon with Tableau GPT. Tableau Pulse redefines metrics and creates a new landing page for data consumption. VizQL Data Service is the first step towards headless BI for Tableau. The introduction of Tableau Gestures in an augmented reality context was impressive, it reminded me a bit of Tom Cruise exploring data in the film Minority Report.
TC23 keynote was started by Chief Product Officer Francois Ajenstat with the celebration of Tableau’s 20 years long journey. Francois emphasised the role of Tableau and Tableau community as a key innovator in easy-to-use self-service analytics. ”A new day for data” was used as a title for the upcoming introductions to suggest there is something big and impressive coming out.
The new CEO of Tableau, Ryan Aytay, also thanked the community, customers, partners and employees for their support. Ryan revealed Tableau success plan for all customers coming later this year to listen and support customers more closely. One of the conference highlights was once again Iron Viz visualisation competition, this year’s winner was Paul Ross with his magnificent renewable energy dashboard.
Tableau Iron Viz vibes in TC23 (photo credit Sharad Adhikari).
But what about the features? Tableau GPT is a very interesting new feature but in a way it isn’t very unique considering almost every organisation is talking about language models and generative AI. On the other hand, it doesn’t mean the feature wouldn’t be very useful, it might be quite the opposite. Tableau Pulse might be a bigger thing than you first think. It has a very appealing UI to combine metrics, visualisations, descriptive information and Tableau GPT based additional insights & interactions. The redesigned metrics layer seems to be much more flexible than before. Metrics are easier to create, more powerful and they can be used around Tableau: in Pulse, dashboards, emails, Slack and mobile.
Possibly a bit more surprising feature is the upcoming VizQL Data Service that takes Tableau towards composable analytics or headless BI. This means you can connect directly to the Tableau backend data model (hyper engine) to query the data without the need of building frontend visualisations with Tableau. This would provide a lot more flexibility when creating data-related products and solutions where you need to use data & analytics. This feature might be somewhat related to the fact that Salesforce is using Tableau hyper data models within its Data Cloud offering to boost analytics possibilities. In the future, Salesforce could use data accelerated by Tableau data engine in their Salesforce Clouds via VizQL Data Service.
From an analytics developer point of view, the most interesting single feature showcased in TC23 (originally introduced in TC22) was shared dimensions (or multi-fact models) support. Shared dimensions enable more flexible multi-fact data models where multiple fact tables can relate to shared dimension tables. This feature makes the logical data layer introduced a couple of years ago more comprehensive and very powerful. Tableau would finally fully support the creation of enterprise level data models that can be leveraged in very flexible ways and managed in a centralised manner. The user interface icon for defining the relationships looked a bit like a meatball, and because the relationships in the logical data model have been referred to as noodles, it was said that Tableau is bringing meatballs to the noodles, very clever 🙂.
Perhaps the coolest little thing was the augmented reality demo where Matthew Miller used a gesture-based user interface to interact with data and visualise it in a meeting context. The demonstration had a bit of a Minority Report vibe in it, perhaps the technology wasn’t yet as smooth as in the film, but Miller was just as convincing as Tom. Tableau gestures feature was created by the Tableau research team and it appears to be in its early stages. Most likely it won’t be released any time soon, but it might be a hint of where data interaction is going in the future.
Matthew Miller demonstrates gesture-based data analytics in TC23.
But what wasn’t mentioned in the TC23? There are a couple of features or big announcements that were highlights in TC21 and TC22, but haven’t yet been released and weren’t mentioned again in TC23. One year ago, in TC22, one of the big buzzwords was business science. It was described as business-driven data science using autoML features and scenario planning etc. But in TC23 keynote business science wasn’t mentioned at all nor were the Model builder or Scenario Planner features.
Next, I’ll go through the key features introduced in TC23 and also list functionalities presented in TC22 and TC21 to understand the big picture. These feature lists don’t contain all the features included in previous releases but the ones mentioned in earlier Tableau Conferences. More info about TC22 and TC21 introduced features can be found in our previous blog posts:
Note: All the product/feature related images are created using screenshots from the TC23 Opening Keynote / Devs on Stage session. You can watch the sessions at any time on Tableau site.
Workbook authoring & data visualisation
Let’s start with workbook authoring and actual data visualisation related features. The only new feature was the new Sankey and Radial charts (or mark types) that are already in pilot use in Tableau Public. It was suggested that there are also other new chart types to be released in near future. Even though I’m a bit sceptical towards too complex or hyped visualisations it’s good to have the option to easily create something a bit different. Because of Tableau’s flexibility, creating something totally crazy has always been possible but often it has required a lot of data wrangling and custom calculations.
Out-of-the-box Sankey chart type presented in TC23.
Creating custom visualisations with Visualisation Extensions was introduced in TC21 (more info here), but we haven’t heard anything about this feature since. It might be that the visualisation extensions development has been stopped or paused, but still these new Sankey and Radial chart types might have something to do with the visualisation extension development done in the past, who knows?
New in TC23
TC23 New mark types (pilot period currently in Tableau Public): Create Sankey & radial charts using specific mark types. Possibly new native mark/charts types in the future.
TC23 Improved Image role functionality: new file types (gif) & expansion to the size limit.
TC23 Edit alt text (for screen readers) directly in Data Guide
Previously introduced and already released features
TC22 Image role (2022.4): Dynamically render images in the viz based on a link field in the data.
TC21 Dynamic zone visibility (2022.3): Use parameters & field values to show/hide layout containers and visualisations.
TC21 Redesigned View Data (2022.1): View/hide columns, reorder columns, sort data, etc.
TC21 Workbook Optimizer (2022.1): Suggest performance improvements when publishing a workbook.
TC21 Multi Data Source Spatial Layers (2021.4): Use data from different data sources in different layers of a single map visualisation.
Previously introduced but not released nor mentioned in TC23
TC21 Visualisation Extensions (~2022 H2): Custom mark types, mark designer to fine-tune the visualisation details, share custom viz types.
Consume analytics & understand data
The hype (and also actual new features) around generative AI have been the number one topic for most of the tech companies this year, and it sure was also for Tableau. Tableau introduced Tableau GPT, which is a generative language model integrated to Tableau and its data with security and governance included. Tableau GPT can be useful for both consumers and analysts. It can be used to search data and find insights just by writing questions and it’ll provide answers in both written text and as a visualisation (like Ask data with steroids). Ask any question and Tableau GPT will help to 1) Find relevant data sources, 2) Analyse data, 3) Present results in text and chart with the possibility to explore more, 4) Suggest related additional questions. It was suggested that Tableau GPT will also be integrated into Data Guide and for developers/analysts to the calculation editor to help build calculations.
Tableau Pulse was another big announcement. It’s a completely new interface to consume analytics and insights with the ability to ask questions via Tableau GPT. It seems to be mostly intended for consumers to follow and understand key metrics and related trends, outliers and other interesting aspects. Tableau Pulse includes a redesigned metrics layer with the possibility to create embeddable metrics manually or suggested by Tableau GPT. It contains personalised metrics & contents (changes, outliers, trends, drivers) and descriptive information created by Tableau GPT.
Tableau Pulse with metrics and TableauGPT generated textual contents presented in TC23.
Unfortunately, we still need to wait to get our hands on Tableau GPT and Tableau Pulse. It might be the end half of this year or even early next year when Tableau actually gets these new features released.
New in TC23
TC23 Tableau GPT (~pilot 2023 H2): Generative AI to assist in searching, consuming and developing data & analytics in many Tableau user interfaces.
TC23 Tableau Pulse with redesigned metrics (~pilot 2023 H2): New user interface to consume analytics and create, embed & follow metrics.
TC23 Tableau Gestures & augmented analytics: Use gestures to interact with data and infuse analytics into meetings.
Previously introduced and already released features
TC22 Data Guide (2022.3): Contains information about the dashboard and fields, applied filters, data outliers and data summary, and links to external resources.
TC22 Data Stories (2022.2 & 2022.3): Dynamic and automated data story component in Tableau Dashboard. Automatically describes data contents.
TC21 Data Change Radar (2022.3): Alert and show details about meaningful data changes, detect new outliers or anomalies, alert and explain these.
TC21 Explain the Viz (2022.3): Show outliers and anomalies in the data, explain changes, explain marks etc.
TC21 Multiple Smaller Improvements in Ask Data (2022.2 & 2022.3): Contact Lens author, Personal pinning, Lens lineage in Catalog, Embed Ask Data.
TC21 Ask Data improvements (2022.1): Phrase builder already available, phrase recommendations available later this year.
Previously introduced but not released nor mentioned in TC23
TC21 Model Builder: Use autoML to build and deploy predictive models within Tableau. Based on Salesforce’s Einstein platform.
TC21 Scenario Planner: Easy what-if-analysis. View how changes in certain variables affect target variables and how certain targets could be achieved.
Collaborate, embed and act
New features in this area related heavily to embedding and using Tableau data for building external data products and services. Especially the VizQL Data Service is Tableau’s first step towards composable analytics where the backend data layer and frontend user interface don’t need to be created with the same tool or technology. Composable analytics or headless BI is seen as a future trend in analytics. VizQL Data Service provides access to data modelling capabilities and data within Tableau to streamline building different kinds of data products with Tableau data. This means that data from Tableau could easily be used outside Tableau without actually embedding visuals, but using the data itself in different ways.
Another introduced feature was the Embedding Playground that will ease up the creation of code to embed Tableau visuals and different kinds of interactions. In the playground, you can select options from dropdowns to alter embedding settings, create interactions (eg. context menus, export, filtering, marks etc.) and get ready to be embedded in Javascript & HTML code. Ephemeral users will centralise user identity and access management and in the future usage-based licensing will be provided to make the pricing more flexible to.
TC23 Ephemeral users (~2023 H2): Centralises user identity and access management to one place. Usage-based licensing options in the future.
TC23 VizQL Data Service (~dev preview 2023 H2): Tableau’s first step is to decouple the data and presentation layer.
TC23 Grant access to a workbook when sharing
Previously introduced and already released features
TC22 Tableau External Actions (2022.4): Trigger actions outside Tableau, for example, Salesforce Flow actions. Support for other workflow engines will be added later.
TC22 Publicly share dashboards: Share content via external public facing site to give access to unauthenticated non-licenced users, only Tableau Cloud. Available via Tableau Embedded analytics usage-based licensing.
TC21 Embeddable Ask Data (2023.1)
TC21 Embeddable Web Authoring (2022.2): No need for a desktop when creating & editing embedded contents, full embedded visual analytics.
TC21 3rd party Identity & Access Providers (2022.2): Better capabilities to manage users externally outside Tableau.
TC21 Connected Apps (2021.4): More easily embed to external apps, creating a secure handshake between Tableau and other apps.
TC21 Tableau search, Explain Data and Ask Data in Slack (2021.4)
TC21 Tableau Prep notifications in Slack (2022.1)
Data preparation, modeling and management
My personal favourite, the Shared dimensions feature, which was introduced already a year ago, was demoed once again. It enables more flexible multi-fact data models with shared dimension tables to create more flexible and comprehensive data models. At least the modelling UI seemed to be rather ready, but unfortunately we didn’t get a target schedule for when this might be released.
Shared dimensions enable multi-fact data sources. Example presented in TC23.
One very welcome little feature is Address Geocoding which allows you to visualise addresses on a map without doing the geocoding beforehand. Related to data models, Tableau also emphasised how Tableau data models are used and available within Salesforce Data Cloud (Tableau Hyper-accelerated queries) and also in the future Data Cloud contents can be analysed in Tableau with a single click (Tableau Instant Analytics in SF Data Cloud).
New in TC23
TC23 Tableau Hyper-accelerated queries in SF Data Cloud (Available now): Salesforce data Cloud is at least partially based on Tableau Hyper data models, which can be used to easily analyse the data within Salesforce Data Cloud without additional modeling steps.
TC23 Tableau Instant Analytics in SF Data Cloud (~2023 H2): Analyse SF Data Cloud data with Tableau with one click.
TC23 Address Geocoding: geocode address data in Tableau to visualise addresses on a map.
TC23 Use TableauGTP in prep & modeling: ask TableauGTP to create advanced calculations, eg. extract email address from json.
TC23 Tableau Prep enhancements: spatial joins, smart suggestion to remove duplicates & easily set header and start a row.
Previously introduced and revisited in TC23
TC22 Shared dimensions / multi-fact models: Build multi-fact data models where different facts relate to multiple shared dimensions.
TC22 New AWS data sources: Amazon S3 connector. Previously mentioned also Amazon DocumentDB, Amazon OpenSearch, Amazon Neptune.
TC22 Multi-row calculations in Prep: Calculate for example running total or moving average in Tableau Prep.
Previously introduced and already released features
TC22 Insert row number and clean null values in Prep (2023.1): Easily insert row number column and clean & fill null values.
TC22 Table extensions (2022.3): Leverage python and R scripts in the data model layer.
TC22 Web data connector 3.0 (2022.3): Easily connect to web data and APIs, for example to AWS S3, Twitter etc.
TC21 Data Catalog Integration: Sync external metadata to Tableau.
TC21 Virtual Connections (2021.4): Centrally managed and reusable access points to source data with a single point to define security policy and data standards.
TC21 Centralised row-level security (2021.4): Centralised RLS and data management for virtual connections.
TC21 Parameters in Tableau Prep (2021.4): Leverage parameters in Tableau Prep workflows.
Previously introduced but not released nor mentioned in TC23
TC21 Tableau Prep Extensions: Leverage and build an extension for Tableau Prep (sentiment analysis, OCR, geocoding, feature engineering etc.).
Tableau Cloud management
For Tableau Cloud management Tableau emphasised HIPAA compliance and improved activity logs to analyse for example login activities and attempts. Customer-managed IP filtering for Tableau Cloud will streamline cloud security management. There were also new features introduced related to access token management in the Tableau Cloud environment.
New in TC23
TC23 Improved activity logs: More data in admin templates about login activities & attempts.
TC23 Customer-managed IP filtering: Set IP address filtering to limit access to Tableau Cloud Site.
TC23 Enhanced access token management: Access token management via API, Control personal access token creation via user group and set expiration periods.
Previously introduced and revisited in TC23
TC22 Multi-site management for Tableau Cloud: Manage centrally all Tableau Cloud sites.
Previously introduced and already released features
TC22 Customer-managed encryption keys (2022.1): BYOK (Bring Your Own Keys).
TC22 Activity Log (2022.1): More insights on how people are using Tableau, permission auditing etc.
Tableau Admin Insights login activity example presented in TC23.
Tableau Server management
Again this year, there weren’t too many new specific features related to Tableau Server management. On the other hand, it was emphasised that the possibility to use an on-premise Tableau Server will be an option also in the future.
Previously introduced and already released features
TC22 Auto-scaling for Tableau Server (2022.3): Starting with backgrounder auto-scaling for container deployments.
TC21 Resource Monitoring Improvements (2022.1): Show view load requests, establish new baseline etc.
TC21 Backgrounder resource limits (2022.1): Set limits for backgrounder resource consumption.
TC21 Time Stamped log Zips (2021.4)
Tableau Ecosystem & Tableau Public
Tableau Public had a few new features introduced, like improved search. Accelerators weren’t mentioned too much in TC23, but lately their usability has improved with the ability to easily map fields when taking dashboard accelerators in use. There were some Tableau Public-related features introduced few years ago in TC21 that haven’t been released yet. Especially getting more connectors to Tableau Public would be very nice, and also the possibility to publish Prep workflows to Tableau Public would be great. Let’s see if we get these previously introduced features to use in the future.
New in TC23
TC23 Tableau Public Enhanced search with sorting & filtering, network activity feed with notifications & extra info, profile pronouns
Previously introduced and already released features
TC21 Tableau Public Custom Channels: Custom channels around certain topics.
TC21 Tableau Exchange: Search and leverage shared extensions, connectors, more than 100 accelerators. The possibility to share the dataset may be added later on.
TC21 Accelerators: Dashboard starters for certain use cases and source data (e.g. call center analysis, Marketo data, Salesforce data etc.). Can soon be used directly from Tableau.
Previously introduced but not released nor mentioned in TC23
TC21 Tableau Public Slack Integration (~2022 H1)
TC21 More connectors to Tableau Public (~2022 H1): Box, Dropbox, OneDrive.
TC21 Publish Prep flows to Tableau Public: Will there be a Public version for Tableau Prep?
Want to know more?
If you are looking for more info about Tableau, please read our previous blog posts, check out our visualisation and Tableau offering, and send a message to discuss more (via our website):
Nowadays many companies are providing services where their B2B customers can investigate and monitor their data in a customer portal. Data could be related to purchases, product quality, delivery times, invoices etc. This type of data and content can be provided to the customer portal B2B users with BI tools, one of them Power BI.
Developing content for this type of solution includes several topics to consider as with “traditional” Power BI development to be shared via Power BI Service. First you need to identify user requirements. Then you spend time understanding data and identifying the data sources, the relationships between them, and the types of data your working with. After this you’re able to clean and transform the data to ensure that it is accurate, complete, and consistent. Next you need to design a model that is optimized for performance, scalability, and usability. This involves creating the necessary tables, columns, relationships, hierarchies, and calculations to support your analysis.
When data and data model is ready, you can choose appropriate visualizations, create interactive elements such as drill-downs and filters, optimize the report layout and ensure accessibility. Finally you need to use time to test your model and visualizations to ensure that they are working correctly and meeting requirements. During the whole process you remember to document the report design, data model, and queries used in the report.
Power BI content development to embed
Power BI Premium enables report and visual embedding. In this blog series I will concentrate on the Power BI developer’s point of view on a solution using some parts from Microsoft “Embed for your customers”. These types of solutions allow developers to build an app that uses non-interactive authentication against Power BI. Usually the report users are external users, and they don’t need to sign in using Power BI credentials to view the embedded content. (If you are interested in learning more details about a software developer’s point of view, visit Microsoft’s official pagesPower BI embedded analytics Client APIs | Microsoft Learn.)
In addition to these, there are things that I needed to take into account in the development work or need my special attention. Below are my key takeaways from the Power BI development projects where the objective was to recreate the old customer portal reports. Many of these are applicable also to Qlik Sense.
Identify restrictions in Power BI to meet customer brand or other UX design requirements and contribute to the development of a good theme file (json).
Prepare to do some expectation management.
Identify functionalities not supported when Power BI content is embedded.
Agree features/functionalities development and setups done in Power BI.
Do tight collaboration with stakeholders. – Read more in the second part of my blog series.
Reserve enough time for testing. – Read more in the third part of my blog series.
Remember to plan and agree on the support process well in advance as usually there are several parties and even tools involved. – Read more in the third part of my blog series.
Power BI restrictions and UX-related requirements
Some customers’ brands might have colors not best for reports accessibility or a font type not supported by Power BI. To tackle these in my experience the development work is easiest to do with a Service/UX designer and with the person responsible for the brand. So, in the early phase of the development work make sure you identify restrictions in the tool to meet brand or other UX-related requirements
Contribute to the development of a good theme file (json). This ensures that all reports have consistent and on-brand colors, fonts, etc. Experienced later that when my customer changed brand colors, it was much easier to implement these changes to all reports. Of course, this type of thinking is relevant in “traditional” Power BI development, but when reports are published outside customer organizations, these issues tend to be even more important.
Expectation management
Prepare to do some expectation management for the customer and testers, if an old existing customer portal is recreated with a new technology. Not all functionalities of the old implementation can necessarily be implemented or they are implemented in a different way. Or the new implementation may have new features or some functionality may be better or sometimes worse compared to the old implementation. During my projects this took time as there was existing portal to be replaced.
To really understand feature and functionality requirements, reserve enough time and sessions with the Business owners or Testers to explore the old solution. In my projects I showed the first draft of the report in the early phase, to get feedback. Noticed also that sometimes the Business owner or Tester do not understand the advantages of an agile way of development. So, it did need some courage to show “not so polished” report versions.
If a totally new customer portal is created, then you probably have much more freedom to introduce visualization types and report layouts/features. But in this case, I would also prefer to demo as soon as possible the first draft version of a report.
Power BI restrictions and embedding
Ensure you know all the solution requirements and discuss them with the Solution Architect and Software developer whether they all are possible to implement. Especially some Power BI Service-related functionalities you probably need to handle outside the tool:
Export to PDF
Save favorites/bookmarks
Report Subscription
Hiding reports from certain users
Embed report size and positions in the customer portal
Functionality to move from one report to another with portal selections/dropdown lists
Agree on features/functionalities development and setups done in Power BI
These features/functionalities I needed to agree with other stakeholders if they are developed in or outside Power BI:
Report headers/titles (consider where maintenance of the name changes is easiest)
Consider if some Filter controls need to be done in the UI/customer portal. E.g., default selections in slicers.
These features/functionalities setups in Power BI need to be agreed upon and tested carefully:
The format of token values is managed outside Power BI, but need to make sure that RLS rules use the correct formats
Page view setup
Page/canvas size, Height and Width
Mobile layouts
I will continue the story about my own experiences related to tight collaboration with stakeholders, testing and support process planning in the next parts of my blog series.
Mastering the art of requirements extraction is crucial for engineering teams striving to create cutting-edge products and systems. But what if there was a way to revolutionize this process and enhance efficiency?
Requirements extraction is a critical process in engineering that involves analyzing and interpreting complex technical documents to identify and prioritize the key features, functions, and constraints of a product or system to be designed. However, the traditional methods of requirements extraction can be time-consuming, error-prone, and inefficient, leading to delays, cost overruns, and suboptimal performance.
Recent advancements in natural language processing and artificial intelligence have made it possible to automate and streamline the requirements extraction process, leading to faster and more accurate results. One such technology is ChatGPT, a state-of-the-art language model that can generate human-like responses to natural language queries and tasks, such as text summarization and question-answering. In this blog post, we will explore how ChatGPT can be used for requirements extraction in engineering, and how it can help engineering teams to optimize their product development lifecycle and stay ahead of the competition.
To interact with large language models such as ChatGPT, we use natural language by providing a prompt and requesting the model to generate a completion. This prompt could be in the form of a question, conversation turn, or pattern to extend, among others. However, this interaction is limited to the knowledge the model has learnt during training. Hence, a roadblock for use in requirements extraction. There are at least two ways to handle this roadblock:
Copy and paste external data into the chat interface for ChatGPT, however there is a limit to how much text can be used in the input. Often the documentation from which requirements are extracted does not fit within this limit.
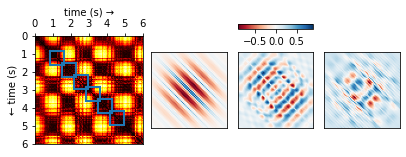
Use a framework called LangChain to solve this “limit problem” which can be used to handle large file formats and data sets. Here we split the text into several chunks and still retain meaning, create embeddings and then store these embeddings as an external knowledge base. Next, only the context-related chunks are then retrieved and combined with the question and sent to the large language model (GPT – 4) to generate a response that is contextual and appropriate. The figure below shows how this can work using Azure Cognitive Search and Azure OpenAI Service.
An added advantage is the explainability through citation where the response from ChatGPT also includes citation with a link to the source content for reference.
Additionally, ChatGPT can also assist in identifying potential ambiguities or inconsistencies in requirements by offering alternative phrasings and scenarios. Overall, ChatGPT can be a valuable asset in the requirements engineering process, saving time and increasing the accuracy and completeness of requirements.
DDaT22481 - CMMS/EAM Software for the ISIS FacilityDescriptionThe final date and time for the submission of bids is Tuesday 11th April 2023 at 11:00.DO NOT apply directly to the buyer.All tender information MUST be submitted through the Jaggaer eSourcing Portal.Brief Description of RequirementSTFC's ISIS facility uses a particle accelerator to produce neutrons and muons which are used to carry out research in the physical and life sciences. The facility uses cutting edge technology and equipment to operate the accelerator continuously through user cycles, with planned maintenance periods approximately four times per year. The facility operates twenty-four hours per day during the user cycle. To ensure high availability and reliability of the assets within the accelerators, target stations and beamlines we require a software based CMMS / EAM system to store asset information, including its location which may be mobile, maintain the stores inventory and operate a maintenance and work order management system.The scope for the computerised maintenance management software (CMMS) package is as follows:- Plan a broad range of maintenance activities from reactive through to preventative and reliability centred.- Schedule and assign maintenance activities, including shutdown scheduling.- Manage the assets lifespan through their entire lifecycle.- Track assets that are movable in their location.- Management of assets, spares, stores functionality.- Produce reports and dashboards associated with asset activities.- Associate safety procedures and documentation such as RAMS, PTW and LOTO.- Shift Log allowing events during a shift to be recorded and exchanged between shifts and the equipment owners.- Manage the calibration activities and analyse calibration data of assets through their lifecycle.- Connect, communicate, and export data with third party software such as condition-based monitoring systems, spreadsheets, and external reporting software such as Power BI.Please ensure you review all attached information to ensure a full understanding of this requirement. All attachments can be found with the Supplier Attachments tab within the Jaggaer eSourcing Portal. This contract will be awarded based on the evaluation criteria as set out in the RFP document. When this contract was ingested into the GPT-4 model with a question to list functional requirements from the RFP, the resulting list produced were
When this contract was ingested into the GPT-4 model with a question to list functional requirements from the RFP, the resulting list produced were
Furthermore, business development executives can benefit from the increased adaptability of seeking information beyond their current knowledge. For example, they can request further details on RAMS, PTW, and LOTO from GPT-4.
However caution must be taken to verify the same information, if the terminologies are completely unknown to them.
Contact us to find out Solita’s complete offering in Generative AI.
Author: Karthik Sindhya, PhD, AI strategist, Data Science, AI & Analytics, Tel. +358 40 5020418, karthik.sindhya@solita.fi
Databricks is a cloud-based platform that seamlessly integrates data engineering, machine learning, and analytics to simplify the process of building, training, and deploying Machine Learning models. With its unified platform built on top of Lakehouse architecture, Databricks empowers Data Scientist and ML engineers to unleash their full potential, providing a collaborative workspace and offering comprehensive tooling that streamline the entire ML process, including tools to support DevOps to model development, deployment and management.
While many companies and businesses are investing in AI and machine learning to stay competitive and capture the untapped business opportunity, they are not reaping the benefits of those investments as their journey of operationalizing machine learning is stuck as a jupyter notebook level data science project. And that’s where MLOps comes to the rescue.
MLOps is a set of tools and practices for the development of machine learning systems. It aims to enhance the reliability, efficiency, and speed of productionizing machine learning. In the meantime,adhering to governance requirements. MLOps facilitate collaboration among data scientists, ML engineers, and other stakeholders and automate processes for a quicker production cycle of machine learning models. MLOps takes a few pages out of DevOps book; a methodology of modern software development but differs in asset management, as it involves managing source code, data, and machine learning models together for version control and model comparison, as well as for model reproducibility. Therefore, in essence, MLOps involves jointly managing source code (DevOps), data (DataOps) and Machine Learning models (ModelOps), while also continuously monitoring both the software system and the machine learning models to detect performance degradation.
MLOps = DevOps + DataOps + ModelOps
MLOps on Databricks
Recently, I had a chance to test and try out the Databricks platform. And in this blog post, I will attempt to summarise what Databricks has to offer in terms of MLOps capability.
First of all, what is Databricks ?
Databricks is a web based multi-cloud platform that aims to unify data engineering, machine learning, and analytics solutions under single service. The standalone aspect of Databricks is its LakeHouse architecture that provides data warehousing capabilities to a data lake. As a result, Databricks lakehouse eliminates the data silos due to pushing data into multiple data warehouses or data lakes, thereby providing data teams the single source of data.
Databricks aims to consolidate, streamline and standardise the productionizing machine learning with Databricks Machine Learning service. With MLOps approach built on their Lakehouse architecture, Databricks provides suits of tools to manage the entire ML lifecycle, from data preparation to model deployment.
MLOps approach on Databricks is built on their Lakehouse Platform which involves jointly managing code, data, and models. Fig:Databricks
MLOps approach on Databricks is built on their Lakehouse Platform which involves jointly managing code, data, and models. Fig:Databricks
For the DevOps part of MLOps, Databricks provides capability to integrate various git providers, DataOps uses DeltaLake and for ModelOps they come integrated with MLflow: an open-source machine learning model life cycle management platform.
DevOps
Databricks provides Repos that support git integration from various git providers like Github, Bitbucket, Azure DevOps, AWS CodeCommit and Gitlab and their associated CI/CD tools. Databricks repos also support various git operations such as cloning a repository, committing. and pushing, pulling, branch management, and visual comparison of diffs when committing, helping to sync notebooks and source code with Databricks workspaces.
DataOps
DataOps is built on top of Delta Lake. Databricks manages all types of data (raw data, log, features, prediction, monitoring data etc) related to the ML system with Delta Lake. As the feature table can be written as a Delta table on top of delta lake, every data we write to delta lake is automatically versioned. And as Delta Lake is equipped with time travel capability, we can access any historical version of the data with a version number or a timestamp.
In addition, Databricks also provides this nice feature called Feature Store. Feature Store is a centralised repository for storing, sharing, and discovering features across the team. There are a number of benefits of adding feature stores in machine learning learning development cycle. First, having a centralised feature store brings the consistency in terms of feature input between model training and inference eliminating online/offline skew there by increasing the model accuracy in production. It also eliminates the separate feature engineering pipeline for training and inference reducing the technical dept of the team. As the feature store integrates with other services in Databricks, features are reusable and discoverable to other teams as well; like analytics and BI teams can use the same set of features without needing to recreate them. Databricks’s Feature store also allows for versioning and lineage tracking of features like who created features, what services/models are using them etc thereby making it easier to apply any governance like access control list over them.
ModelOps
ModelOps capability in Databricks is built on a popular open-source framework called MLFlow. MLflow provides various components and apis to track and log machine learning experiments and manage model’s lifecycle stage transition.
Two of the main components of MLFlow are MLFlow tracking and MLFlow model registry.
The MLflow tracking component provides an api to log and query and an intuitive UI to view parameters, metrics, tags, source code version and artefacts related to machine learning experiments where experiment is aggregation of runs and runs are executions of code. This capability to track and query experiments helps in understanding how different models perform and how their performance depends on the input data, hyperparameter etc.
Another core component of MLflow is Model Registry: a collaborative model hub, which let’s manage MLflow models and their lifecycle centrally. Model registry is designed to take a model from model tracking to put it through staging and into production. Model registry manages model versioning, model staging (assign “Staging” and “Production” to represent the lifecycle of a model version), model lineage (which MLflow Experiment and Run produced the model) and model annotation (e.g. tags and comments). Model registry provides webhooks and api to integrate with continuous delivery systems.
The MLflow Model Registry enables versioning of a single corresponding registered model where we can seamlessly perform stage transitions of those versioned models.
The MLflow Model Registry enables versioning of a single corresponding registered model where we can seamlessly perform stage transitions of those versioned models.
Databricks also supports the deployment of Model Registry’s production model in multiple modes: batch and streaming jobs or as a low latency REST API, making it easy to meet the specific requirements of an organisation.
For model monitoring, Databricks allows logging the input queries and predictions of any deployed model to Delta tables.
Conclusion
MLOps is a relatively nascent field and there are a myriad of tools and MLOps platforms out there to choose from. Apples to apples comparison of those platforms might be difficult as the best MLOps tool for one case might differ to another case. After all, choosing the fitting MLOps tools highly depends on various factors like business need, current setup, available resources at disposal etc.
However, with the experience of using a few other platforms, personally, I find Databricks the most comprehensive platform of all. I believe Databricks make it easy for organisations to streamline their ML operations at scale. Platform’s collaboration and sharing capabilities should make it easy for teams to work together on data projects using multiple technologies in parallel. One particular tool which I found pleasing to work with is Databricks notebook. It is a code development tool, which supports multiple programming languages (R, SQL, Python, Scala ) in a single notebook, while also supporting real time co-editing and commenting. In addition, as the entire project can be version controlled by a tool of choice and integrates very well with their associated CI/CD tools, it adds flexibility to manage, automate and execute the different pipelines.
To sum up, Databricks strength lies in its collaborative, comprehensive and integrated environment for running any kind of data loads whether it is data engineering, data science or machine learning on top of their Lakehouse architecture. While many cloud based tools come tightly coupled with their cloud services, Databricks is cloud agnostic making it easy to set up if one’s enterprise is already running on a major cloud provider (AWS, Azure or Google cloud).
Finally, if you would like to hear more about Databricks as an unified Analytics, Data, and Machine Learning platform and learn how to leverage Databricks services in your Data journey, please don’t hesitate to contact me our Business Lead – Data Science, AI & Analytics, Mikael Ruohonen at +358414516808 or mikael.ruohonen@solita.fi or me at jyotiprasad.bartaula@solita.fi.
"In the final instalment of this series, we will be taking the Q-learning solution generated by ChatGPT and optimizing it for maximum performance. In the previous posts, we demonstrated how ChatGPT can be used as a tool for data science workflows, including generating boilerplate solutions and addressing bugs and errors. Now, with a working solution in hand, we will explore various optimization techniques to fine-tune and improve the performance of the Q-learning algorithm. From adjusting hyperparameters to implementing advanced techniques, this post will show you how to take your ChatGPT-generated solution to the next level.
In the previous instalments of this blog series, I demonstrated how to use ChatGPT as tool in your data science workflow and how much it helps, timewise, compared to doing everything from scratch. In this third part, I will ask ChatGPT to optimize code in a working solution and comment on how good of a job it does. As previously source code is available here: solita/chatGPT_RL_blog3: All resources referenced in Solita chatGPR for RL blog part3 (github.com)
And as a treat, my assignment solution for the university is also available for you in the repository. Feel free to compare and evaluate both.
Optimizing the agent
I’ll start with the actual neural network architecture. Let’s ask ChatGPT to suggest a better Deep Q-learning architecture.
Input: “Suggest a better deep q learning architecture than this one:
Output: One improvement to this architecture would be to use a convolutional neural network (CNN) instead of a fully connected network for the initial layers. This is because CNNs are well-suited for processing images and other grid-like data, which is often the type of input that a DQN receives.
Additionally, you can use a technique called experience replay which stores past experiences and randomly samples from them to improve the stability and efficiency of learning.
You can also add a target network that is used to compute the target Q-values during training. This can help to stabilize the training process and improve the overall performance of the DQN.
Another improvement would be to use a technique called Double DQN which addresses the problem of overestimation of Q values by having two different networks to estimate the Q values, one for action selection and the other for action evaluation.
Incorporating these techniques can lead to a better DQN architecture and improve the performance of the agent.
Input: Produce a model with the suggested improvements, keep in mind that the input data is 1-dimensional if you use convolutional layers
Output:
A solid proposition for creating a better architecture for the neural network. Convolutional layers are used as a feature extraction layer and then passed to feed-forward neural network layers for estimating q-values. You can see from the notebook provided that this change had quite a drastic effect on the reward that the agent gets.
I’ll test another function from the agent class before moving to the environment class.
Input: Do you have propositions on how to make this function faster?
“””get action from model using epsilon-greedy policy”””
“””
I transferred the epsilon decay method to the notebook.
The chatGPT generated function is only choosing a random action or the action with the highest predicted Q-value.
It should also be considering the possible actions that are available in the current state. Additionally, the function is only decreasing epsilon after each episode, while it should be decreasing epsilon after each sample.
I don’t want to pass the environment class as a parameter to access the env.requests() function. We’ll just pass the possible action indices and actions an rewrite this function.
“””
if np.random.rand() <= self.epsilon:
# explore: choose a random action from possible actions
return random.choice(possible_actions_index)
else:
# exploit: choose the action with the highest predicted Q-value
state = np.array(self.convert_state_to_vector(state)
In all honesty, some of these don’t make much sense and this is due to the fact that ChatGPT didn’t get any context in the input, just the code.
would be valid if the possible_actions_index variable would be numpy array and not a list.
With refactoring it would be possible to use vectorized data, a good suggestion
preprocessing the requests could be done in this case since all requests could be pre-computed from the time matrix.
kind of makes this whole code pointless since the agents job is to estimate the q-values.
Epsilon decay is done after each step.
Prioritized replay buffer is a valid suggestion and wouldn’t be too complex to implement, but since it involves some extra computation and look backs during each step (compared to the vanilla replay buffer I implemented) it would make the solution slower albeit the Q-learning algorithm would, probably, converge faster.
This is the architecture that I originally submitted myself, it makes training a little bit slower,, but the model converges faster due to increased stability
A valid option also
Based on this I would say that ChatGPT is actually making some nice propositions on a function level on how to optimize the agent class but not on a solution level since it’s lacking the context. Here’s the code for the optimized DQN Agent
Let’s move on to the environment class, in the last part of this blog series I pointed out that there is a repeated code problem in the reward and next state functions. How will ChatGPT react to it?
Time to see how would ChatGPT optimize the environment class.
Input: Give a suggestion on how to optimize this class:
Output:
Suggestion is already in the code,
the second and third suggestions are good suggestions but with the state_space tuple you must be careful, since you need to add that state for an offline action. Once the tuple is created you cannot modify it.
Suggestions 4. To 6. Resonate well with the previous suggestion of not calling the state vectorization function. If the data would be in a NumPy format, we wouldn’t need to do the vectorization calls. This would require extensive refactoring and take some time to achieve.
The last suggestion is maybe too much for our use case.
Let’s check how ChatGPT optimizes the reward_func and next_state_func where I pointed out that we’re making the same 4D array slicing in both functions.
As a conclusion to this blog series, I have demonstrated how Data Scientists can use ChatGPT as a tool to streamline their working process and get suggestions for problems or code quality enhancements.
ChatGPT is quite proficient at suggesting good and mostly relevant changes to solutions that already work but it isn’t yet quite able to produce a working solution just by itself.
It will be quite exciting to start working on solving business problems with large-language-models and personally, I can’t wait to test the coding optimized version of GPT3.5 that Microsoft is now offering Azure OpenAI Service – Advanced Language Models | Microsoft Azure
If you would be interested in learning more about opportunities with generative models, and optimization or are looking for a partner to help you with your use cases don’t hesitate to contact us.
In the first part of this series, we explored the capabilities of ChatGPT, a state-of-the-art language model developed by OpenAI, in assisting data scientists with tasks such as data cleaning, preprocessing, and code generation. In this second part, we will delve deeper into what ChatGPT generated and why it didn't work. We will discuss the specific challenges that come with using AI-generated code, and how to effectively address these issues to ensure the reliability and accuracy of the final product. Whether you're a data scientist or a developer, this post will provide valuable insights into how to use ChatGPT to improve your workflow and streamline your development process.
In the first instalment of this blog series, we explored the capabilities of ChatGPT in generating boilerplate code from well-defined problem statements. We also discussed the benefits of providing extensive detail on the desired code functionality and the performance of ChatGPT when given a skeleton code to fill.
While the results were impressive, and a good starting point for a data science project, it was an effort to make the code function.
In this part of the blog, I will walk you through the bugs and mistakes ChatGPT made. As for why ChatGPT made the mistakes, there are multiple reasons and I have explained some of the problems in the first chapter of the series.
Materials
I was having trouble figuring out a way to present this part of the blog. There are plenty of bugs and mistakes ChatGPT made and to make it easier to understand, I’ll provide an explanation of the smaller pieces (attributes, functions, variables) in more detail. This post is written for developers and assumes that the reader has a basic understanding of Python programming.
I have chosen to explain the major changes I made on the function level. To see all of the changes, you will need to refer to the code in the repository provided.
This post will go through each function, explain what it is supposed to do, and what ChatGPT did wrong in my opinion. The actual fixes can be found by looking at the code in the repository.
Docstub: “Initialise your state, define your action space, and state space”
My understanding of the errors that ChatGPT made:
The init for action_space that chatGPT generated was wrong since it generates a list of all possible pairs of integers between 0 and m-1 where m=5, including pairs where the integers are the same, and an additional pair [0, 0].
The agent can’t travel in a loop from state 1 to 1, eg. the pickup location and the drop-off location can’t be the same as per the problem description. The only exception is the offline action [0,0] when the agent chooses to go offline.
I fixed this so that the action_space init generates a list of all possible pairs of integers between 0 and m-1, where the integers in each pair are distinct and at least one of them is 0.
The requests function
Docstub: Determining the number of requests basis, and the location. Use the table specified in the MDP and complete it for the rest of the locations.
My understanding of the errors that ChatGPT made:
ChatGPT only handled pickup location 0 when m=5.
I added handling for the rest. Using a dictionary instead of the if-else structure suggested by ChatGPT. ChatGPT does not add the index [0] to indicate no ride action, the method just returned an empty list.
The reward function
Docstub: Takes in state, action and Time-matrix and returns the reward
My understanding of the errors that chatGPT made:
No-ride action is not handled correctly. No-ride action should move the time component +1h as described in the problem definition. The function was returning the reward=-C which does not correspond to the reward calculation formula: (time * R) – (time * C). time = total transit time from current location through pickup to dropoff (transitioning from current state to next state).
chatGPT is calculating the travel time from the current state to the next state and updates the location. chatGPT is doing a mistake, hour and day in a state tuple are integers.
ChatGPTs way of calculating the time it takes to transition (for the taxi to drive) from the current state to the next state results in returning arrays for h and d.
This is due to the fact that ChatGPT is slicing the 4D Time Matrix in the wrong manner. ChatGPT is using two sets of indices, pickup and drop-off, to slice the array.
indices are needed to slice the array in the correct way. I broke the total transition time calculation into multiple steps for clarity
The next state function
Docstub: Takes state and action as input and returns next state
My understanding of the errors that chatGPT made:
chatGPT is calculating the travel time from the current state to the next state and updates the location. chatGPT is doing a mistake, hour and day in a state tuple are integers.
ChatGPTs way of calculating the time it takes to transition (for the taxi to drive) from the current state to the next state results in returning arrays for h and d.
This is due to the fact that ChatGPT is slicing the 4D Time Matrix in the wrong manner. ChatGPT is using two sets of indices, pickup and drop-off, to slice the array.
indices are needed to slice the array in the correct way. I broke the total transition time calculation into multiple steps for clarity
Just to point out there is a repeated code problem in these functions since they make the same lookup, it should be refactored as a function, but I’ll leave that to the next part of the blog.
What was missing? A function to do a step:
In reinforcement learning (RL), a “step” refers to the process of transitioning from the current state to the next state and selecting an action based on the agent’s predictions. The process of taking a step typically includes the following steps:
The agent observes the current state of the environment
The agent selects an action based on its policy and the current state
The agent takes the selected action, which causes the environment to transition to a new state
The agent receives a reward signal, which indicates how well the selected action led to the new state
The agent updates its policy based on the received reward and the new state
At each step, the agent uses its current policy, which is a function that takes the current state as input and produces an action as output, to select the next action. The agent also uses the rewards obtained from the environment to update its policy so as to maximize the cumulative rewards.
Looking at the code that was generated by ChatGPT all of the pieces were there. The step function I implemented is just a wrapper that uses the reward and gets the next state functions. Look at the solution in the repository for details.
Docstub: “Initialise the DQNAgent class and parameters.”
My understanding of the errors that chatGPT made:
“Everything was initialized properly, variable for the initial exploration rate epsilon was missing so I added that. “
The build_model method
Docstub: “Build the neural network model for the DQN.”
ChatGPT didn’t do any mistakes here, it builds a simple feed-forward neural network, and the input and output sizes are defined correctly.
The get_action method
Docstub: “get action from the model using epsilon-greedy policy”
My understanding of the errors that ChatGPT made:
“Transferred the epsilon decay method to the notebook. The ChatGPT-generated function is only choosing a random action or the action with the highest predicted Q-value. It should also be considering the possible actions that are available in the current state. Additionally, the function is only decreasing epsilon after each episode, while it should be decreasing epsilon after each sample. I don’t want to pass the environment class as a parameter to access the env.requests() function. We’ll just pass the possible action indices and actions and rewrite this function.”
The train_model method
Docstub: “Function to train the model on each step run. Picks the random memory events according to batch size and runs it through the network to train it.”
My understanding of the errors that ChatGPT made:
“This boilerplate from ChatGPT won’t quite do. It is updating the Q values for one sample at a time, and not using a batch sampled from the memory. Using a batch will speed up training and stabilize the model. “
Summary
Overall going through the boilerplate code that ChatGPT generated and fixing them took around10 hours. As a comparison when I originally solved this coding problem and generated a solution with the help of Google, it took around 30 hours. The boilerplate provided as input had a clear impact on the solution, both with ChatGPT and me.
In the next part of the blog series, I’ll ask ChatGPT to propose optimizations to the fixed code and see if it makes or breaks it. My original solution will be available for comparison.
ChatGPT, a state-of-the-art language model developed by OpenAI, has the ability to assist data scientists in a variety of tasks. Its advanced natural language processing capabilities make it well-suited for tasks such as data cleaning and preprocessing, text summarization, and even the generation of code. In this blog post, we will explore one of the ways in which ChatGPT can be utilized in data science workflows, and discuss its potential to streamline and automate various aspects of the data science process.
This blog will reference source code presented here: chatGPT_RL_Blog1
Grammarly and GitHub Copilot are tools that help professionals improve their writing and coding by identifying errors and suggesting corrections. Grammarly is a writing tool that checks grammar, spelling, and punctuation, while GitHub Copilot is a coding tool that suggests code completions and helps with refactoring. These tools are designed to help professionals who already know the solution to the problem but want to speed up their work by automating error checking and providing suggestions to improve their writing or coding.
ChatGPT, on the other hand, is a language model that can generate text similar to human language. It can be used to generate code based on input, but it’s not specifically designed or trained to optimize code. However, ChatGPT can understand natural language instructions and generate code that follows those instructions, which makes it even better for people who are not experts in coding to write code based on their needs and it can perform a wide range of tasks. Additionally, ChatGPT has the ability to understand natural language inputs and generate human-like responses, which is not the case for Grammarly and GitHub Copilot which are specialized for specific tasks.
I have come across several blog posts (f.ex. https://www.solita.fi/en/blogs/gpt-will-you-do-the-fandango/) discussing the use of ChatGPT for data science and have personally conducted my own testing and troubleshooting with it. As a result, I decided to utilize ChatGPT for a hobby project in data science. It revolves around optimizing the revenue of taxi drivers with reinforcement learning. The following details my process, the challenges encountered, and the outcomes achieved.
For reference, this optimization problem was presented as a part of a Reinforcement Learning course when I was studying at university. Multiple different solutions to this problem are available on GitHub and Kaggle.
Here is the link to the source material presented: chatGPT_RL_Blog1
Primer – What is reinforcement learning?
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with its environment. The agent receives rewards or penalties for its actions and uses this feedback to improve its decision-making over time. A common example of this is a computer program that learns to play a game by repeatedly playing it and adjusting its strategy based on its performance. The goal of the agent is to maximise its overall reward over time. Reinforcement learning has been used to train agents to play complex games like Go and chess, as well as control robots and drones.
Reader discretion is advised – Why can the outputs differ when using the same inputs in chatGPT?
“ChatGPT generates its output based on the input it receives and the patterns it has learned from the dataset it was trained on. If the input it receives is slightly different, the model will generate a different output based on the patterns it has learned. Additionally, ChatGPT is a probabilistic model, so it samples from the distribution of possibilities it has learned from the data. Therefore, even if the input is the same, ChatGPT may generate a different output each time it is run. The variation can also come from the fact that the model is not deterministic.” – chatGPT
Let’s first see how chatGPT builds the environment for the reinforcement learning problem.
The problem declaration was given as a README.md file. The environment for the cab driver is defined and constrained very clearly so that students can start working with it immediately.
Let’s see how chatGPT performs, there won’t be pictures of the complete outputs since that would make this blog way too long. The reader is encouraged to try these input prompts while you’re reading and taking a look at the boilerplate was the result of this experiment.
Input: Based on this input explain the problem and summary of a possible solution.
Output: “The problem at hand is to develop an RL-based algorithm that can assist cab drivers in maximizing their profits by helping them make better decisions on the field. The recent hikes in electricity prices have caused many drivers to complain that their profits are almost flat despite gradually increasing revenues. The algorithm’s goal is to help drivers choose the ‘right’ rides, i.e. those that are likely to maximize the total profit earned by the driver that day. The objective of the problem is to maximize the profit earned over the long-term. The decisions are made at an hourly interval, and the algorithm needs to take into consideration the current state of the driver (location, hour-of-the-day, and day-of-the-week), the ride requests received, and the rules governing the ride-allocation system. A possible solution in python would be to develop a Q-learning algorithm that takes into account the state, action, and reward, and updates the Q-values over time to converge to an optimal policy for the cab driver to follow.”
If you read the problem definition you can see that chatGPT wrote a really nice summary of the problem described.
Input: Based on the previous input generate, a environment.py file that can be used to train an RL agent to solve the problem. The reinforcement learning agent is a Tensorflow Keras API based deep Q learning model.
Output: “I’m sorry but creating an environment.py file that can be used to train an RL agent to solve the problem would require me to have access to the relevant data and the complete structure of the deep Q learning model. Additionally, it would also require a significant amount of code development and testing to make sure the environment is working correctly.
However, I can give you some guidelines on how to create such an environment.py file:
Define the state space and the action space for the agent
Create a class for the environment that initializes the state and implements the step function, which takes in the action chosen by the agent and returns the next state, reward, and a boolean indicating if the episode is over
Implement a method for resetting the environment to the initial state
Implement a method for rendering the current state of the environment
Create a function for getting the state from the environment, which will be used by the agent to update its Q-values
Add any additional functionality needed for the specific problem and the chosen RL algorithm
Please keep in mind that the implementation details of the environment will depend on the data and the specific problem you are trying to solve.“
Let’s try a different type of input, a summary in natural language about the code that we want ChatGPT to generate. Input:
Output an example in python based on this definition:
The CabDriver class is used to simulate the cab-driving environment for the reinforcement learning agent.
The __init__ function initializes the class and sets the following attributes:
self.action_space: a list of all possible actions the agent can take, represented as a pair of integers for the pickup and drop-off locations.
self.state_space: a list of all possible states the agent can be in, represented as a tuple of integers for the current location, hour, and day.
self.state_init: a randomly generated initial state for the agent to start in.
The convert_state_to_vector function takes in the current state and converts it into a vector format, which can be fed into a neural network. The vector is of size m + t + d, where m is the number of cities, t is the number of hours, and d is the number of days.
The replay function takes in the current state and returns the number of requests the agent can receive at that location, time and day. The function uses a Poisson distribution with an average rate specified for each location. The possible actions are obtained by randomly sampling from the action space and appending a [0,0] action which means no pickup or drop-off
The get_reward function takes in the current state, action and the time matrix and returns the reward for the given state and action. The reward is calculated as the difference between the revenue from the passenger and the cost of fuel and other expenses.
The get_next_state function takes in the current state, action and the time matrix and returns the next state of the agent after taking the given action from the current state. The next state will be the destination location, the time of arrival and the day of the week after completing the travel time. If the action is [0,0], meaning no pickup or drop off, the next state will be the same as the current state.
The reset() function returns the action_space, state_space and the initial state of the agent at the beginning of the episode.
Now the result looks promising, let’s iterate once more. Code stubs for the environment and agent were provided as a part of the assignment from the university. Let’s ask chatGPT to fill in the code stub based on the previous output.
Let’s try a third kind of input, a code skeleton.
Input: Fill in this code skeleton. Add docstrings for all functions.
The output looks like something we can start working with.
Q-learning algorithm
Let’s start working on the RL agent class.
Input: Create a DQNAgent python script that uses the CabDriver class for training
Output:
This looks really good; the function naming is now clearer than with the environment and ChatGPT has added the necessary parameters. Let’s try using the natural language input that defines the DQNAgent class.
Input: Build a python script based on this description and the previous output:
The DQNAgent class is a class for creating a deep Q-network (DQN) agent.
The __init__ method is used to initialize the class, and sets the size of the state and action space for the agent, as well as initializes the following hyperparameters for the DQN:
discount_factor: the discount factor used to weigh future rewards in the Q-learning algorithm
learning_rate: the learning rate used to update the model’s weights
epsilon_max: the maximum value of the epsilon exploration parameter
epsilon_decay: the rate at which epsilon decays towards epsilon_min
epsilon_min: the minimum value of the epsilon exploration parameter
batch_size: the number of samples used in each training update
memory: a deque object used to store previous experiences for training
model: the DQN model created by the build_model method
The build_model method is used to build the neural network model for the DQN. This method creates a new Sequential model, adds layers to the model, and compiles it with the mean squared error loss function and the Adam optimizer with the learning rate specified in the class initialization.
The get_action method is used to select the next action to take in the environment. It uses an epsilon-greedy policy, where with probability epsilon, a random action is chosen, and with probability 1-epsilon, the action with the highest predicted Q-value is chosen.
The append_sample method is used to save a sample of the form (state, action, reward, next_state) to the replay memory. This sample can later be used for training the DQN.
The train_model method is used to train the DQN model using samples from the replay memory. It first checks if there are enough samples in the memory, and if so, it randomly samples a batch of samples from the memory. It then creates empty arrays update_output and update_input that will be used to update the model’s weights.
It then loops through the samples in the mini-batch and for each sample, it predicts the target Q-values using the current model, computes the target Q-values using the next state, and updates the update_output and update_input arrays with the state and target Q-values respectively.
After updating the arrays, it then fits the model with the update_input and update_output arrays, with the batch size specified in the class initialization and for only one epoch.
The save method is used to save the current DQN model to a file with the specified name.
Interestingly the output didn’t change that much, a train_model function was added, and the function naming was replaced by the inputs. And finally let’s see the input when we use a code skeleton and chatGPT fills in the blanks.
Input: Fill in this code skeleton based on the previous inputs and outputs. Add docstrings to all functions.
This will be the boilerplate that I’ll start working on in the next part of this blog. As it can be seen it is by no means a working solution.
Interestingly as I requested chatGPT to regenerate the output a few times, this started happening:
Parting words
In summary, this blog post has shown you how to use chatGPT as a starting point for your machine-learning projects. You can find all the code and examples used in this blog post from GitHub: chatGPT_RL_Blog1
In the next part of the blog, I will go through the changes I made to the boilerplate code to make it work. In the last chapter of this series, I will use chatGPT suggestions to optimize functions in the code and add some optimizations of my own to see how good of a solution we’ll end up with.
FYI: All the text in this blog has been written with the help of Grammarly and the images have been generated by: DALL·E (openai.com)
The biggest obstacle for unlocking value from data assets is inefficient methods for discovering data within large data ecosystems. Gartners Data Fabric introduces emerging solutions that introduce metadata driven automation that help to overcome this obstacle.
This is the third part of the blog series. The 1st blogfocused on the maturity model and explained how the large monolith data warehouses were created. The 2nd blog focused on metadata driven development or “smart manufacturing” of data ecosystems.
This 3rd blog will talk about reverse engineering or how existing data assets can be discovered to accelerate the development of new data products.
Business Problem
Companies have increasing pressure to start addressing the data silos to reduce cost, improve agility & accelerate innovation, but they struggle to deliver value from their data assets. Many companies have hundreds of systems, containing thousands of databases hundreds of thousands of tables, millions of columns, and millions of lines of code across many different technologies. The starting point is a “data spaghetti” that nobody knows well.
Business Solution
Metadata discovery forms the foundation for making fact-based plans, decisions and actions required to improve, leverage, and monetize data assets. Metadata driven development can use fact-based knowledge delivered by metadata discovery. It can leverage the most valuable data assets and provide delivery with dramatic improvement to quality, cost & speed.
How to efficiently resolve a “data spaghetti”?
Are you planning changes in your architecture? Do you need a lot of time from the experts to evaluate the impact of the changes? Do you have a legacy environment that is costly & risky to maintain, and nobody knows well? How do you get an accurate and auditable blueprint of it to plan for changes?
You may have experience in a data development project, where it took a lot of meetings and analysis to determine the correct data sources and assets to be used for the business use case. It was hard to find the right experts and then it was hard to find availability from them. Frequently there are legacy systems that nobody knows anymore as the experts have left the company. Very often legacy environments are old and not well documented.
A manual approach for discovering data assets means slow progress
Due to complexity, time and resource constraints manual documentation is likely to have a lot of pitfalls and shortcuts that introduce risks to the project. Manual documentation is likely to be outdated already when finished. It is inaccurate, non-auditable and non-repeatable.
Unfortunately, often the scale of the problem is not understood well. Completely manual approaches have poor chances to succeed. It is like trying to find needles in a haystack.
More automation and less dependency on bottleneck resources are needed for an efficient resolution of a “data spaghetti”. In our industry, this area is widely called data discovery. In this blog, we talk about metadata discovery because we want to bring attention to applying metadata driven automation to make data discovery more efficient and scalable.
A data discovery needs to start with an automated metadata discovery, which enables scale and can point the “hotspots” for scoping of the most critical data assets for doing data discovery.
In data discovery, we discover the data/content itself typically by doing data profiling. Data profiling will show if the data quality is fit for the intended usage. Data profiling is data intensive and analysing vast amounts of production data is not always feasible due to negative performance impacts. Data discovery can only be applied with the most critical data assets because security and privacy become bottlenecks in accessing many data sources.
An efficient Data Supply Chain needs to be able to unlock value from existing data assets
Data Supply Chain focuses on creation and improvement of data driven business solutions. It can be called forward engineering. The efficiency of Data Supply Chain is very dependent on knowledge of existing data assets that can be reused, or preferred data sources and data assets to be refined to meet the business data requirements.
Metadata discovery is used for cataloguing or documenting existing data assets. It can be called as reverse engineering as it is like discovering of an architecture blueprint of the existing data ecosystem.
Efficient Data Supply Chain leverages forward and reverse engineering
Even if the Data Supply Chain applies metadata driven development and the resulting data products are catalogued for future reuse, there is always a large set of data assets in the data ecosystems that nobody knows well. This is where reverse engineering can help.
Reverse engineering is a term that might not be that familiar to many of the readers. Think of a data ecosystem where many of the solutions have been created a long time ago. People who have designed and implemented these solutions – using forward engineering – have left the company or some of the few remaining ones are very busy and hard to access. The documentation is no longer up-to-date and not at the level that you would need. Reverse engineering means that you are lifting the “blueprint” of the ecosystem into a right level to discover the most valuable assets and their dependencies to evaluate any change impacts. Then you are carving out from the legacy environment the original design that has been the basis for data storages and data interfaces.
Automated metadata discovery can help you discover and centralize knowledge that the company may have lost.
This interplay between reverse engineering – discovering As-Is data assets – and forward engineering – planning, design, and creation of To-Be data products – is always existing in data development. There are hardly any greenfield development cases, which solely focus on forward engineering. There is always a legacy data ecosystem that contains valuable data assets that needs to be discovered. It is very much needed in all cases where the existing data architecture is changed or with any migrations.
Think if you have an accurate blueprint of the legacy environment which will enable you to reduce migration scope, cost, and risk by 30%. That alone can justify solutions that can do automated metadata discovery. Many banks have used automated metadata discovery for documenting old mainframes that have been created decades ago. They have requirements to show data lineage to the regulators.
This blog is going to make a deeper dive into reverse engineering, which has not been in focus of the previous blogs. Reverse engineering would mean in manufacturing the same as doing migration of the supply chain into using a digital twin. This would involve creating an understanding of the inventory, product configurations at different levels the manufacturing process and tools to translate raw materials to finished goods. One such application is Process Mining. The key difference is that it is based on data – not metadata. Another key difference is:
Data is an exceptional business asset: It does not wear out from use and in fact, its value grows from reuse.
Data fabric – Emerging metadata driven capabilities to resolve data silos
The complete vision presented in these blogs matches very well with Gartner’s Data Fabric:
“A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets (reverse engineering) to support the design, deployment and utilization of integrated and reusable data across all environments (forward engineering)”
Gartner clients report approximately 90% or more of their time is spent preparing data (as high as 94% in complex industries) for advanced analytics, data science and data engineering. A large part of that effort is spent addressing inadequate (missing or erroneous) metadata and discovering or inferring missing metadata.
Automating data preparation to any degree will significantly increase the amount of analysis and outcome development (innovation) time for experts. Decreasing preparation time by just 8% almost doubles innovation time. (The State of Metadata Management: Data Management Solutions Must Become Augmented Metadata Platforms)
“Future is already here. It is just not evenly distributed.” By William Gibson. Gartner’s Data Fabric is still quite visionary and on top of the hype curve. There are not many products in the market that can realize that vision. The happy news is that we have seen some parts of the future. In this blog we can shed some light into this vision from our experience.
Metadata discovery automation unlocks value of existing data assets
Data Dictionaries
Connectivity and automated technical metadata ingestion from variety of data sources
Metadata discovery starts by identifying prioritised data sources to be ingested based on business drivers. What is technical metadata? It is the metadata that has been implemented in a database or in a piece of software. Technical metadata is quite usually database, tables, and columns or files & fields. It is also the code that moves data from one table to another or from one platform to another.
Automated data lineage
Data lineage shows how the data is flowing through the ecosystem. It includes the relationships between technical metadata. Doing a data lineage requires that the solution can “parse” a piece of code to understand the input tables/files it reads from and then what is the output tables/files it writes into. This way the solution can establish lineage across different platforms.
Sometimes that the code is parametrized, and the actual code is available only at the run time. This means that the lineage is built using processing/query logs, which is called operational metadata.
Automated transparency – Augmented data cataloguing
Data cataloguing means that we can map business terms with technical metadata. Augmented data cataloguing means that we leverage Machine Learning (ML) based automation to improve the data cataloguing efforts. That can be achieved with both top-down and bottom-up approaches.
Bottom-up – Automated inferencing of relations between business terms and technical metadata. For example: “SAP fields are abbreviated in German. How to map an SAP field against an English vocabulary? You follow data lineage towards consumption where you find some more understandable terms that enable infer the meaning of a field in SAP”.
Solutions use ML for these inferences and the result gives a probability of the discovered relationship. When a data steward confirms the relationship then ML learns to do more accurate proposals.
Top-down – Semantic discovery using business vocabularies, data models & training data means that you have a vocabulary that you use for classifying mapping assets. The solutions use typically some training data sets that help to identify typical naming patterns of data assets that could match with the vocabulary. This method is used in particular for identifying and classifying PII data.
Analytics activates metadata – It creates data intelligence
Data intelligence term is a bit like business intelligence that has been used with data warehousing. Metadata management is a bit like data warehousing. There is a common repository to which metadata is ingested, standardized, and integrated.
Reaching transparency is not enough. There is too much metadata to make the metadata repository actionable. Activating metadata means leveraging analytics identify the most valuable or risky data assets to focus on.
Analytics on metadata will start showing the “health” of the data assets – overlaps, redundancies, duplicates, assets that nobody uses, or which are used heavily.
Gartner focuses on usage analytics, which is a very immature area with the products in the market. Usage analytics leverages Operational Metadata, which provides tracking and logging of data processing & usage.
Here are examples of use cases that can leverage usage analytics:
Enables governance to focus on data assets that have the most value & risk for business usage
Guides priority to assignment of term definitions, managing assets, classifications, quality, and usage
High usage of private data brings focus of evaluation if data is used for the right purpose by the right people
Enables ranking of application, databases, and tables value based on usage, for example when doing migration planning
High usage is an indication that many users trust and find benefits of data – evaluate which of the optional data sources is a good candidate for golden source
Enables to free up space – Clean up unused data – Enables to decommission unused applications, databases & tables
Guides business & data placement optimization across all platforms – Identify the best use of platform or integration style for business needs based on data usage patterns & size
Reveal shadow IT because it could show the data lineage from consumption towards data sources. There could be surprising sources being used by BI services. These in turn would be security & privacy concerns.
Can also show to larger user community the most popular reports, queries, analytics, data sets
Collaboration, Curation and Certification
Collaboration around metadata driven Data Supply Chain has been discussed in the previous blogs. This chapter gives a short summary.
Centralizing knowledge for distributed people, data & ecosystems accelerates & scales the “Data Supply Chain”
Metadata discovery automation enables business views linked to physical evidence, which creates foundation for collaboration and fact-based decisions
Bottom-up – Automation is key for being able to centralize vast amounts of knowledge efficiently.
The repository is populated using intelligent automation including ML, then the results provided (proposals with probabilities) by automation are curated by data stewards and the ML learns to do more accurate proposals. Analytics enables focus on assets that demand decisions, actions, and improvements.
Top-down – Business driven implementation is a must. Business buy-in is critical for success.
Creating transparency to data assets cannot be completely automated. It requires process, accountability, and behaviour changes. It requires common business data definitions, rules & classifications etc. It needs to be supported with a metadata solution that enables collaboration & workflows.
Top-down, business driven plan, governance and incremental value delivery is needed. Bottom-up discovery needs to be prioritized based on business priorities. Common semantics is the key for managing demand and supply of data to an optimized data delivery roadmap.
Getting people activated around the centralized knowledge is a key success factor. This can happen through formal accountabilities and workflows where people are leveraging fact-based knowledge to collaborate, curate and certify reusable data assets / products and business glossary. It can happen through informal collaboration, crowd sourcing & voting or in general by activating people in sharing their “tribal” knowledge.
Data Supply Chain leverages facts about data assets to accelerate changes.
Metadata discovery can help a lot with efficiency of Data Supply Chain. It makes fact-based plans, decisions, and actions to improve, leverage and monetize data assets. It enables to focus & prioritize plans and actions on data assets that have the most value & risk for business usage. Facts about “health” of the data assets can help to justify and provide focus for practical data architecture and management improvements:
Who is getting value from which data? Which data can be trusted and should be reused?
What data assets/data flows are non-preferred/redundant/non-used etc.?
Which data assets should be cleaned-up/minimized, migrated, and decommissioned?
What is the impact of the proposed changes?
Recommendation Engine
“The data fabric takes data from a source to a destination in the most optimal manner, it constantly monitors the data pipelines to suggest and eventually take alternative routes if they are faster or less expensive — just like an autonomous car.” Demystifying the Data Fabric by Gartner
Recommendation engine is the most visionary part of Gartner’s Data fabric. Gartner’s recommendation engine leverages discovered metadata – both technical and operational – and makes recommendations for improving the efficiency of the development of new data pipelines & data products.
Recommendation engine is like a “Data Lineage Navigator”.
It can analyse all alternative paths between navigation points A and B
It will understand the complexity of the alternative paths – roads and turning points.
Number of relationships between selected navigation points A and B
Relationships & transformations are classified into complexity categories.
Identify major intersections / turning points.
Identify relationships with major transformations – these could contain some of the key business rules and transformations that can be reused – or avoided.
Identify roads with heavy traffic.
Identifies usage and performance patterns to optimize the selection of the best path.
Many of the needed capabilities for realizing this vision are available, but we have not run into a solution that would have these features. Have you seen a solution that resembles this? Please let us know.
Back down to earth – What should we do next?
This blog has provided a somewhat high-fly vision for many of the readers. Hopefully, the importance of doing metadata discovery using Data Catalogs has become clearer.
Data Catalogs provide the ability to create transparency in existing data assets, which is a key for building any data-driven solutions. Transparency creates the ability to find, understand, manage, and reuse data assets. This in turn enables the scaling of data-driven business objectives.
Data cataloguing should be used at the forefront when creating any data products on Data Lake, DW or MDM platforms. It is especially needed in the planning of any migrations or adaptations.
Maybe as a next step also your company is ready to select a Data Catalog?
The Data Catalog market is a very crowded market. There are all kinds of solutions. All of them have their strengths and weaknesses. Some of them are good with top-down and some bottom-up approaches. Both approaches are needed.
Data Catalog market is very crowded
We find quite often customers that have chosen a solution that does match to their needs and typically there are hard leanings with automation – especially with data lineage.
We at Solita have a lot of experience with Data Catalogs & DataOps. We are ready to assist you in finding the solution that matches your needs.
Learn more about Solita DataOps with Agile Data Engine (ADE):
Smart manufacturing uses digital twin to manage designs, processes, and track quality of the physical products. Similarly smart development of modern data ecosystems uses metadata as the digital twin to manage data product designs and the efficiency of the data supply chain.
The first part of this blog series introduced a maturity model that illustrated the history of developing data ecosystems – data marts, lakes, and warehouses – using an analogy to car manufacturing. It explained how the large monolith data warehouses were created. It just briefly touched on the metadata driven development.
This blog drills down to the key enablers of metadata driven data supply chain that was introduced in the last blog. The blog has 2 main chapters:
The Front End – Data Plan & Discovery
The Back End – Data Development with Vertical Slices & DataOps automation
Metadata driven data supply chain
Metadata driven data supply chain produces data products through a life cycle where the artefacts evolve through conceptual, logical, physical, and operational stages. That also reflects the metadata needs in different stages.
Data plan for incremental value delivery – The front end of the data supply chain leverages data catalogs to optimise data demand and supply into a data driven roadmap.
Delivery of incremental value – The back end of the data supply chain delivers business outcomes in vertical slices. It can be organized into a data product factory that has multiple, cross functional vertical slice teams that deliver data products for different business domains.
Vertical slicing enables agility into the development processes. DataOps automation enables smart manufacturing of data products. DataOps leverages metadata to centralize knowledge for distributed people, data & analytics.
Business Problems with poor metadata management
As a result of building data ecosystems with poor metadata management companies have realised large monolith data warehouses that failed to deliver the promises, and now everyone wants to migrate away from them. There is a high risk that companies end up building new monoliths unless they change the way of developing data ecosystems fundamentally.
Business Solution with metadata driven development
Metadata enables finding, understanding, management and effective use of data. Metadata should be used as a foundation and as an accelerator for any development of data & analytics solutions. Metadata driven development brings the development of modern data warehouses into the level of “smart manufacturing”.
1. Front end – Data Plan & Discovery
Data Plan & Discovery act as a front end of the data supply chain. That is the place where business plans are translated into data requirements and prioritised into a data driven roadmap or backlog.
This is the place where a large scope is broken into multiple iterations to focus on outcomes and the value flow. We call these vertical slices at Solita. This part of the data supply chain is a perfect opportunity window for ensuring a solid start for the supply of trusted data products for cross functional reuse. It is also a place for business alignment and collaboration using common semantics and a common data catalog.
Common semantics is the key for managing demand and supply of data
Vision – Data as a reusable building block
Common semantics creates transparency to business data requirements and data assets that can be used to meet the requirements. Reconciling semantic differences and conflicting terms enables efficient communication between people and data integrations between systems.
Common semantics / common data definitions enable us to present data demand and supply using common vocabulary. Common semantics also enables decoupling data producers and data consumers. Without it companies create point-to-point integrations that lead to well known “spaghetti architecture”.
Flexible data architecture is built on stable, modular & reusable data products
Data products is gaining significant interest in our industry. There seems to all kinds of definitions for data products. They come in different shapes and forms. Again, we should learn from manufacturing industry and apply it for data supply chain.
Flexible data architecture is built on stable, modular design of data products.
Modular design has realized mass customisation in manufacturing industry. Reusing product modules has provided both economies of scale and the ability to create different customer specific configurations for increased value for customers. Here is a fantastic blog about this.
Reuse of data is one of the greatest motivations for data products because that is the way to improve speed and scale data supply capability. Every reuse of data product means 70% cost saving and dramatic improvement in speed & quality.
An efficient data or digitalization strategy needs to include a plan for developing a common business vocabulary that is used for assignment of data domain level accountabilities. The common business vocabulary and the accountabilities are used to support design and creation of reusable data products on data platforms and related data integration services (batch, micro services, API, messaging, streaming topics) for sharing of the data products.
An enterprise-wide vocabulary is a kind of “North Star” vision that no company has ever reached, but it is a very valuable vision to strive for, because cost for integrating different silos is high.
Focus on common semantics does not mean that all data needs to be made available with common vocabulary. There will always be different local dialects and that is OK. What seems today like a very local data need may tomorrow become a very interesting data asset for a cross functional use case, then governance needs to act on resolving the semantic differences.
Data demand management is a great place to “battle harden” the business vocabulary / common semantics
Too often companies spend a lot of time on corporate data models and common vocabulary but lack a practical usage of them in the data demand management.
Data demand management leverages the common semantics to create transparency to business data requirements. This transparency enables us to compare data requirements of different projects to see project dependencies and overlaps. These data requirements are prioritised into a data roadmap that translates data demand into an efficient supply plan that optimises data reuse and ensures incremental value delivery.
Data Demand Management
Data catalogs play a key role in achieving visibility to the data assets that can be used to meet business needs. Data reuse is a key for achieving efficiency and scaling of the data supply chain.
Translating business plans to data plans
Embedding data catalog usage into the data supply chain makes the catalog implementation sustainable. It becomes a part of normal everyday processes and not as a separate data governance activity.
Without a Data Catalog the front end of the data supply chain is typically handled with many siloed Excel sheets covering different areas like – requirements management & harmonization, high level designs and with source-target mappings, data sourcing plans, detailed designs & mappings, and testing plans etc.
Collaborative process for term harmonisation follows business priority
Data governance should not be a police force that demands compliance. Data Governance should be business driven and proactively ensuring efficient supply of trusted data for cross functional reuse.
Data governance should actively make sure that the business glossary covers the terms needed in the data demand management. Data governance should proactively make sure that the data catalog contains metadata of the high priority data sources so that the needed data assets can be identified.
Data governance implementation as an enterprise-wide activity has a risk of becoming academic.
Business driven implementation approach creates a basis for deploying data governance operating models incrementally into high priority data domains. This can be called “increasing the governed landscape”.
Accountable persons are identified, and their roles are assigned. Relevant change management & training are held to get the data stewards and owners aware of their new roles. Understanding is increased by starting to define data that needs to be managed in their domains and how that data could meet the business requirements.
Collaborative process for term harmonization
Common semantics is managed both in terms of formal vocabulary / business glossary (sometimes called Corporate Data Model (CDM)) as well as crowd sourcing of the most popular terms. Anyone can propose new terms. Data Governance should identify these terms and formalise them based on priority.
Commitment Point – Feasibility of the plan is evaluated with data discovery
Data plan is first done at the conceptual level to “minimise investment for unknown value”. Conceptual data models can support this activity. Only when the high priority vertical slices are identified it makes sense to drill down to the next level of detail in the logical level. Naturally, conceptual level means that there could be some risks with the plan. Therefore, it makes sense to include a data discovery for early identification of risks in the plan.
Data discovery reduces risks and wasting effort. The purpose is to test with minimal investment hypothesis & business data requirements included in the business plan by discovering if data provides business value. Risks may be top-down resulting from elusive requirements or bottom-up resulting from unknown data quality.
This is also a place where some of the data catalogs can support as they include data profiling functionality and data samples that help to evaluate if data quality is fit for the intended purpose.
Once the priority is confirmed and the feasibility is evaluated with data discovery, we have reached a commitment point from where the actual development of the vertical slices can continue.
2. Back end – Data Development with Vertical Slices & DataOps automation
Vertical slicing means developing an end-to-end data pipeline with fully implemented functionality – typically BI/analytics – that provides business value. Vertical slicing enables agility into data development. The work is organised into cross functional teams that apply iterative, collaborative, and adaptable approaches with frequent customer feedback.
Scaled DataOps approach
DataOps brings the development of modern data warehouses into the level of “smart manufacturing”.
Smart manufacturing uses digital twin to manage designs, processes, and track quality of the physical products. Smart manufacturing enables to deliver high quality products with frequent interval and with batch size one. It also enables scaling to physically distributed production cells because knowledge is shared with the digital twin.
DataOps uses metadata as the digital twin to manage data product designs and the efficiency of the data supply chain. DataOps centralizes knowledge, which enables to scale data supply chain to distributed people, who deliver high quality data products in frequent time interval.
DataOps uses metadata as the digital twin
DataOps automation enables smart manufacturing of data products. Agile teams are supported with DataOps automation that enables highly optimised development, test and deployment practices required for frequent delivery of high-quality solution increments for user feedback and acceptance. DataOps enables to automate large part of the pipeline creation. Focus of the team shifts from basics to ensuring that the data is organized for efficient consumption.
DataOps enables consistent, auditable & scalable development. More teams – even in distributed locations – can be added to scale development. The team members can be distributed into multiple countries, but they all share the same DataOps repository. Each team works like a production cell that delivers data products for certain business domain. Centralized knowledge to enables governance of standards and interoperability.
Centralizing knowledge for distributed people, data & analytics
DataOps automation enables accelerated & predictable business driven delivery
Automation of data models and pipeline deployment removes manual routine duties. It frees up time for smarter and more productive work. Developer focus shifts from data pipeline development to applying business rules and presenting data as needed by the business consumption
Automation enables small, reliable and delivery of high-quality “vertical slices” for frequent review & feedback. Automation removes human errors and minimises maintenance costs.
Small iterations & short cycle times – We make small slices and often get feelings of accomplishment. The work is much more efficient and faster. When we deploy into production sometimes the users ask if we started developing this.
DataOps facilitates a collaborative & unified approach. Cross functional teamwork reduces dependency on individuals. The team is continuously learning towards wider skill sets. They become high performers and deliver with dramatically improved quality, cost, and speed.
Self-organizing teams – More people can make the whole data pipeline – the smaller the team the wider the skills.
DataOps centralises knowledge to scale development. Tribal knowledge does not scale. DataOps provides a collaborative environment where all developers are consuming and contributing to a common metadata repository. Every team member knows who, what, when, and why of any changes made during the development process and there is no last-minute surprise causing delivery delays or project failure.
Automation frees up time for smarter and more productive work – Development with state-of-the-art technology radiates positive energy in the developer community
DataOps enables rapid responses to constant changes. Transparent & automatically documented architecture ensures that any technical depth or misalignment between teams can be addressed by central persons like data architect. Common metadata repository supports automated and accurate impact analysis & central management of changes in the data ecosystem. Automation ensures continuous confidence that the cloud DW is always ready for production. Changes in the cloud DW and continual fine tuning are easy and without reliance on manual intervention.
Continuous customer feedback & involvement – Users test virtually continuously, and the feedback-correction cycle is faster
Solita DataOps with Agile Data Engine (ADE)
Agile Data Engine simplifies complexity and controls the success of a modern, cloud data warehouse over its entire lifecycle. Our approach to cloud data warehouse automation is a scalable low-code platform balancing automation and flexibility in a metadata-driven way.
We automate the development and operations of Data Warehouse to ensure that it delivers continuous value and adapts quickly and efficiently to changing business needs.
ADE – Shared Design and Multi-Environment Architecture for Data Warehousing
Designer
Designer is used by the users for designing the data warehouse data model and load definitions. It is also the interface for the users to view the graphical representations of the designed models and data lineages. The same web-based user interface and an environment shared by all data & analytics engineering teams.
Deployment Management
Deployment Management module manages the continuous deployment pipeline functionality for data warehouse solution content. It enables continuous and automated deployment of database entities (tables, views), data load code and workflows into different runtime environments.
Shared repository
Deployment Management stores all metadata changes committed by the user into a central version-controlled metadata repository and manages the deployment process.
Metadata-driven code generation
The actual physical SQL code for models and loads is generated automatically based on the design metadata. Also, load workflows are generated dynamically using dependencies and schedule information provided by the developers. ADE supports multiple cloud databases and their SQL dialects. More complex custom SQL transformations are placed as Load Steps as part of metadata, to gain from the overall automation and shared design experience.
Runtime
Runtime is a module used for operating the data warehouse data loads and deploying changes. Separate runtime required for each warehouse environment used in data warehouse development (development, testing and production). Runtime is also used as a workflow and data quality monitoring and troubleshooting the data pipelines.
Learn more about Solita DataOps with Agile Data Engine (ADE):
Stay tuned for more blogs about “Smart Manufacturing”.
This blog is the 2nd blog in the series. The 1st blog focused on the maturity model and explained how the large monolith data warehouses were created. This 2nd blog focused on metadata driven development or “smart manufacturing” of data ecosystems. The 3rd blog will talk about reverse engineering or how existing data assets can be discovered to accelerate development of new data products. There is a lot more to tell in that.
AWS re:Invent is the biggest AWS conference in the world with over 50,000 participants and 2600 sessions to choose from over five days. This blog is a recap of the event and the sessions that I attended to give you an idea of what happens during the hectic week in Las Vegas.
After two years of virtual events and uncertainty in travel restrictions, this year it finally looked possible to attend the biggest AWS event on-site too, so I definitely wanted to take the opportunity to head to Las Vegas once again. I have been to two AWS conferences before (re:Invent in 2018 andre:Inforce in 2019), so I already had some idea of what to expect from the hectic week. You can read more about what to expect and tips and tricks for attending from the previous blog posts, as most of them applied this year too and the conference itself hasn’t changed that much from previous years. In this blog post, I’m going to summarize all the different sessions that I attended during the week to give you an idea of what’s happening during this massive and long event.
Pre-planning and scheduling
re:Invent is always a huge conference and this year made no exception. With over 50,000 participants and 2600 sessions to choose from over five days, there’s a lot of content for almost everything AWS related. With the massive scale of the conference comes some challenges related to finding relevant content. There are different types of sessions available, with breakout sessions being lecture-type presentations that will be published to YouTube later on. Therefore, I tried to focus on reserving seats to more interactive, Q&A focused Chalk Talks and hands-on workshops, as those are only available at the event itself.
This year, reserving seats to the sessions went pretty smoothly, but once again the calendar and session finder were quite lacking in helpful features that would make the process a lot easier. For example, you can’t easily search for sessions that would fit your calendar at the location your previous session ended, but have to go through the session list manually with some basic filters. Also, since there are many different venues and traveling between venues takes a lot of time, you would want to minimize the amount of venues per day, but for some reason the sessions I wanted to go to were scattered all over the campus. So initially, my calendar looked pretty unrealistic, as sessions were in multiple different locations throughout the days. Therefore I ended up just focusing on a couple of longer workshops per day, and favoriting a bunch of sessions in the same location as the previous or next session. This way, I could easily have a “Plan B” or even a “Plan C” when trying to find a walk-up spot for some of the sessions.
However, this meant that my calendar for the week ended up looking like this:
Overall, the scheduling experience was still a bit lacking compared to the excellent quality of the conference otherwise. But at least this time in the end I managed to get in to pretty much all of the sessions I wanted to, and the schedule worked out pretty well in practice too, as you could utilize the free time between sessions with all the nice things happening around (content hub, labs, jam lounge) and just walking around the huge expo area (talking to AWS staff, vendors and also collecting some nice swag)
Notes from the sessions
Here are some short recaps on the different sessions that I attended during the week.
Day 0 – Sunday
The whole Solita crew attending the event started the journey with the same flight, but after some unfortunate flight delays, we were split to different connecting flights in Dallas and finally arrived to Las Vegas in late Saturday night after 22 hours of traveling and a lot of waiting.
For some reason, the traditional Midnight Madness event with the first announcements was not held this year, so Sunday was quite relaxed with some strolling around while trying to deal with jet lag. Badge and hoodie pickup points opened on Sunday, so that was pretty much the only official agenda for the day. In the evening we had dinner with the whole Solita crew attending the event this year.
Day 1 – Monday
Hackathon: GHJ301-R – AWS GameDay: The New Frontier
Day one started early at 8:30 AM with one of the most interesting sessions available – the GameDay Hackathon where teams of four compete against each other in a gamified learning experience. Because there was no reserved seating available for this year’s GameDay sessions, I wanted to make sure to get there in time. And due to some jet lag, a brisk morning walk was also a good way to wake up. In the end, I was there way too early as there wasn’t a huge queue to get in like I had thought and the room didn’t even get full.
The concept of GameDay was a bit different this year, as there were independent quests and challenges instead of one unifying challenge. In 2018, the theme was microservices and trying to keep the services up and running while something unexpected occurred. That required a bit more teamwork, as now you could just focus on working on one challenge at a time individually.
There were also some bonus quests added during the session, and even Jeff Barr made a quick visit on stage announcing a trivia bonus quest. In the end, our team finished 10th out of roughly 40 participating teams, but we could’ve had a lot more points if we had done some of the challenges in a different order, as there were some that were generating a lot more points based on the time they were completed.
Overall, it was a fun learning experience once again, as you get to solve some puzzles and try new services in a more hands-on way than in a workshop.
Workshop: AIM312-R – Build a custom recommendation engine in 2 hours with Amazon Personalize
Next up was a 2 hour workshop focused around recommendations using Amazon Personalize. I have previously tinkered with the service right when it launched, and it was a bit limited in features back then. Over the years they have added some new things like promotions, campaigns and metrics, but if you are trying to do anything more complicated, you might quickly run into the limits of the service.
The title of the workshop was a bit misleading, since the actual model used for recommendations was already pre-built and would take way longer than 2 hours to complete even with the small dataset that was used in the workshop.
Session: BOA304 – Building a product review classifier with transfer learning
I had scheduled a second workshop for the afternoon but it would have been on the other side of the campus, so I opted for staying near Venetian so that I could visit the Expo area too. Found a breakout session with an interesting topic so I decided to join it as a walk-up. The very quick 20 minute session was about using apre-built model from Hugging Face in Sagemaker and doing some transfer learning for building a simple helpful/not helpful classifier for Amazon.com product reviews.
Chalk Talk: DAT301 – Use graphs to perform fraud analysis with Amazon Neptune and Neptune ML
I also managed to get in a chalk talk as a walk-up without any queueing(!). Apparently graph databases are still not that widely used. It was an interesting session though, and with chalk talks you get a lot more opportunities for interacting with and asking questions from the presenters.
Neptune ML seems like a pretty nice wrapper for Sagemaker, but it looked like you needed to use property graphs (Gremlin or openCypher) instead of RDF (SPARQL). The upcoming Graph Explorer looked nice compared to the current very limited visualization tools available using Neptune Notebooks. Some pretty good conversation sparked from questions from the audience regarding data modeling in graph databases.
After the sessions on Monday evening, AWS Nordics hosted a welcoming reception in one of the restaurants located inside Venetian, the main conference hotel. It was quite packed, but it was nice to meet new people from other companies in Finland.
Day 2 – Tuesday
Keynote: Adam Selipsky’s keynote
To save some time on traveling between venues and waiting in queues, I opted to watch the Tuesday morning’s main keynote from an overflow space located at my hotel. Loads of new announcements and customer cases were shared once again. The biggest data related announcements were probably OpenSearch Serverless, the “zero-ETL” integration of Athena and Redshift, general availability of Redshift streaming ingestion from Spark, and Datazone, a new data catalog and governance tool which I hoped to learn more about in a new launch session, but unfortunately there weren’t any available and even the blog post was quite vague on details.
Workshop: LFS303 – Finding data in a life science data mesh
The first workshop on Tuesday focused on creating a data mesh setup with multiple different health care data sets in S3 that were cataloged using Lake Formation and crawled using Glue. Information about the data sets was then converted into RDF Triples and loaded into Amazon Neptune so that graph traversal queries can be done and medical codes can be combined with the hierarchical medical code ontology data set to create a knowledge graph where you can find out the data sets where the data you are looking for is located in, using differently formatted medical codes. Then you can use Lake Formation to provide fine grained access to the data and Athena to query the actual data.
This was a pretty good and informative workshop with some similarities to one use case in my current project too (Neptune and hierarchical ontologies), and I learned something new from Lake Formation which I hadn’t used before too.
The agenda for the second workshop of Tuesday was building a simple voting web application using serverless components (Aurora Serverless, Lambda, API Gateway and Cloudfront) and auto-scaling, with authentication using Cognito. The use case was quite basic, so nothing too special was done in this workshop, but it was still nice to see how quickly Aurora is able to auto-scale when the load increases or decreases, while latencies to the web application remain low.
Session: CMP314 – How Stable Diffusion was built: Tips and tricks to train large AI models
There wasn’t any space for two chalk talks that I tried to join as a walk up (without reservation), so instead I went to listen to a session on how the text-to-image ML model Stable Diffusion was trained instead. It was fun to hear from the challenges that training that massive of a model has and the infrastructure around it, even though this massive ML model training is probably something I won’t be doing anytime soon.
After the sessions on Tuesday night there were some sponsored restaurant reception events at the venues, and in addition to that I attended an event hosted by Databricks at Topgolf. It was a fun experience to try some rusty golf swings on a gamified driving range while meeting new people and discussing what they are doing using AWS services.
Day 3 – Wednesday
Workshop: BOA325-R – Building a serverless Apache Kafka data pipeline
On Wednesday morning Swami Sivasubramanian hosted a keynote focusing on data & machine learning. I had booked a workshop at the same time, so I tried to follow the keynote while waiting for the workshop to start. Some new features for existing products were announced, for example Spark support for Athena and Geospatial ML for Sagemaker.
The actual workshop was focused on building a quite simple data pipeline with a Fargate task simulating generating clickstream events, sending them to Kafka which triggered a Lambda to convert the events to a CSV format and upload that to S3. Converted files were then visualized in QuickSight.
Workshop: ANT312 – Streaming ingestion and ML predictions with Amazon Redshift
Second workshop of the day focused on the new-ish streaming ingestion and ML features of Redshift. First streaming data was loaded from Kinesis to Redshift using the new Streaming Ingestion feature where you don’t need to use Firehose and S3 but you can just define the Kinesis stream as an external schema and create a materialized view for the stream data. Kafka (MSK) streams were supported too. After configuring the streaming data as a materialized view and loading some historical data, Redshift ML was used to build a XGBoost binary classification model for finding fraudulent transactions directly from the stream based on history data. Quicksight was then used for visualizing the data and to create a dashboard for the fraudulent transactions.
Also had some extra time between workshops and didn’t have any room to join nearby workshops or chalk talks as a walk-in, so went to the overflow content hub to briefly listen to some on-going sessions regarding EKS and Well-Architected Framework.
Workshop: ANT310-R – Build a data mesh with AWS Lake Formation and AWS Glue
Third and last workshop of the day focused on creating a quite complex data mesh setup based on AWS Analytics Reference Architecture using Lake Formation, Glue, CDK and Athena. Basically it was about sharing your own data set to a centrally governed data catalog with some Named/Tag based access control, and then accessing data from other accounts in the data catalog and combining them in queries using Athena.
Day 4 – Thursday
Hackathon: GHJ206-R – AWS Jam: Data & Analytics
Thursday morning started with some jamming instead of the Werner Vogels keynote that was happening at the same time. I glanced through the announcements from the keynote afterwards, and at least Eventbridge Pipes and Application Composer looked like interesting announcements.
This year there were also separate Jam events in addition to the Jam Lounge at the Expo area, where you could again complete different challenges during the whole week. The separate Jam events were only three hours long and teams of four competed in completing challenges while collecting points, similarly to this year’s GameDay. The Jam event I was most interested in was focusing on Data & Analytics, with challenges ranging from using Amazon Rekognition for facial image recognition to creating real time data analytics pipeline using Kinesis Data Streams and Kinesis Data Analytics Studio.
Luckily we got some very talented people in our team and we managed to complete almost all of the challenges. In the end, we finished first out of 50 participating teams and won the jam, and got some nice prizes for the effort too. It was a close competition and we managed to climb to the first position only in the very last minutes. Overall it was again an intense but fun experience and I managed to learn some new things regarding Sagemaker and Kinesis.
Session: DAT328 – Enabling operational analytics with Amazon Aurora and Amazon Redshift
There were a couple of new launch sessions added to the catalog after the keynotes, and this time I managed to get a seat in a couple of them. This session focused on the “zero-ETL” linking of Amazon Aurora and Amazon Redshift, where Aurora data will be automatically synced to Redshift without having to write any code. Basically you first needed to configure the integration using the Aurora console, and after that a new database was added to Redshift. After that, an initial export was done, CDC logging was enabled in Aurora and future changes will be synced automatically to Redshift to the newly created database. Currently the feature only supports Aurora MySQL and is available in preview only. It also seemed to lack any features for example for filtering the synchronization to use only a specific table or multiple tables in Aurora.
Workshop: CON402-R – Concepts to take your Kubernetes operations and scale to the next level
Last workshop of the week was focused on some best practices for scaling, security and observability inside EKS. It’s still quite cumbersome and slow to set up and the developer experience for Kubernetes still isn’t great. Cluster autoscaling was done using Karpenter, security was improved using IAM role based access control and pod level security, observability was done using CloudWatch Container Insights, OpenTelemetry and X-Ray.
Chalk talk: AIM341-R – Transforming responsible AI from theory into practice
Last chalk talk of the day was an interactive discussion on how to build responsible ML models, which aspects to take into account and how to make ML models more explainable. Would have liked to see more concrete examples on how to take all those things into account at the model level.
Thursday night was the re:Play night. Before the main event, there was also a AWS Certified Reception pre-party held at at a local bowling alley with also other fun and games. The main event took place at the nearby Festival Grounds and it was a great night filled with music, good food, drinks and meeting up with colleagues and new people, with Martin Garrix and Thievery Corporation headlining the two live music stages. This time it took quite a lot of time to get in and out of the party, as wait times for shuttles were long and traffic was slow.
Day 5 – Friday
Session: ARC313-R -Building modern data architectures on AWS
Even though most of the content at re:Invent happens between Monday and Thursday, there were still a couple of sessions held on Friday morning too. This session was quite an information dump showcasing the multiple different AWS resources available for reference architectures for different data use cases and data platforms. Focused on six different layers: ingestion, storage, cataloging, processing, consumption and governance, with providing reference architectures and services to use for each of those. What also became clear with this session is that AWS has quite a lot of overlapping services these days, and the ones you should use depend quite a lot on your use case.
Last session of the week was a brief overview and demo on the new EventBridge Pipes feature announced at Werner’s keynote on Thursday. It provides a simple way to integrate different AWS services without writing extra code. It looks pretty easy to use for simple use cases, where you might need to do some filtering for Kinesis streams or call a Lambda for transforming data, and then passing on the data to another service like SQS. They wanted it to work kind of like UNIX pipes, but for AWS services.
Conclusions
Overall, re:Invent 2022 was again a great learning experience and an exhausting but rewarding week. The days were long but there’s so much new to learn and things happening all the time that the week just flew by very quickly. It was great to finally attend a large conference after a couple of years of online-only events which just don’t work the same way in terms of learning and networking in my opinion. You could easily spend the whole week just in the expo area talking to different vendors and AWS staff, and still learn a lot without even attending the sessions.
Even though the conference is massive in its scale, almost everything worked smoothly without any major issues. I’d still agree with pretty much all of the conclusions from my previous blog post again, and re:Invent is definitely a conference worth attending even though it is a pretty big investment timewise. Hopefully I’ll get the chance to attend it again some time in the future.
Also keep an eye out for upcoming re:Invent blog posts in our Dev and Cloud blogs too.
Digital companies face a new era of fraud. In this article, we look at fraud beyond financial transactions. “Soft fraud” is about loopholes in marketing incentives or policies, rather than the typical “hard” definitions of payment or identity fraud. The goal is to look at fraud that could silently happen to you and how to address it with data. Lastly, we check what is needed for successful fraud detection with machine learning.
Many companies transform digitally to stay ahead of the curve. At the same time they expose themselves in a digital ecosystem. As digital presence grows, so does the surface area that attracts malicious actors. “The crime of getting money by deceiving people” according to the Cambridge Dictionary takes many forms when you deceive systems instead of people. Once fraudsters identify a loophole, they scale their approach with bots leading to substantial financial loss. This likely explains why fraud and debt analytics ranks among the top ten AI use cases according to McKinsey’s state of AI report.
Soft fraud
Fraud that is less clear-cut from a legal perspective involves bad actors that systematically exploit loopholes within usage policies, marketing campaigns or products. We could refer to it as soft fraud:
Bad actors systematically misuse policies, products or services to divert money or goods from the digital ecosystem to themselves.
Digital marketing giveaways. The digital economy offers a vast range of services, and so does it offer endless possibilities for fraud. One of the biggest areas is digital marketing. It gets attacked from two sides: Humans and algorithms that mimic human behavior, also known as bots. Both try to exploit usage policies, ad campaigns or incentive schemes. For example, a customer creates accounts to claim sign-up bonuses, also called sign-up fraud. Another one involves a customer that uses a product once and yet returns it, referred to as return fraud. Sharing accounts across friends or family is a famous example for companies like Netflix. Non-human actors, like bots, click on paid-ads or exploit affiliate schemes to claim rewards, such as a payout for each new customer registration.
Humans reap bonuses. Most of the traffic still comes from humans, estimated around 60%. They become interested in your product and explore your digital offering. Some try to take advantage of promotional schemes such as newsletter sign-up bonuses, giveaways or related incentives. They reap bonuses multiple times, for example by using generic email addresses. Others try to push boundaries on usage policies. For example, when multiple persons use one account or share content protected by paywall. With a genuine interest in your product, they count as “friendly fraudsters”, happily using blind spots in web-tracking or marketing campaigns. Those customers invest time to access your products. So, they reveal a strong preferences for your offering. Rigorously blocking them to bring down fraud may hit innocent customers as false positives. Additionally it kills the potential to re-engage with previous fraudsters in a more secure way. That is why in the world of fraud detection, experts refer to it as the “insult rate”.
Bots dilute metrics. Up to estimated 40% of website traffic comes from bots. They click ads, fill out web forms and reap giveaways. The entire lifecycle of digital marketing gets compromised. Bots dilute key performance metrics which leave you wondering about low conversion rates, high cost-per-click or low lead quality. They negatively impact key metrics such as cost per acquisition (CPA), customer lifetime value (LTV), cost per click (CPC), marketing qualified leads (MQL), etc.
Below you find a list that provides an overview about fraud types you can encounter. It divides into non-human actors like bots, human actors like users and eventually both. It includes anyone who gets incentivized by your digital presence to commit fraud.
Non-human actors like bots
Click fraud: Viewing ads to get paid per click.
Inventory fraud: Buying limited goods like sneakers or tickets and holding inventories.
Fake account creation: Registering as users to dilute the customer base.
Campaign life-cycle fraud: Competitors deploy bots which eat up marketing budgets.
Lead generation fraud: Filling out forms to sabotage sales efforts
Human-only actors like customers or competitors
Multi-account usage: Different persons use a personalized account.
Return fraud: Customer uses product and returns it damaged
Bonus fraud: Get discounts multiple times after newsletter sign-up or account registration.
Account takeover: Leaked login details or weak user authentication
Friendly fraud: Customers receive a product, dispute the purchase and chargeback the money
Either human or non-human
Affiliate fraud: Bots click exploit a strategy in affiliate campaigns to unlock compensation
Bad-reputation fraud: An attack on your product reviews from competitors
Some of these can be tackled with data analytics and possibly machine learning, while some are more about designing policies and services in a safer way, so that they cannot be easily exploited.
Effective fraud detection builds on data
Now that we have seen different types of fraud, what can we do about it? Do we want to detect them when they happen, or do we want to prevent them from happening at all? Let us see how data & analytics can help us.
Leverage machine learning. Fraud tends to happen systematically. Systematic actors need a systematic response. If your data captures these patterns and lets you identify fraud, you have everything to build effective solutions with rules, heuristics or eventually machine learning. Machine learning is an approach to learn complex patterns from existing data and use these patterns to make predictions on unseen data (Huyen, C., 2022. Designing Machine Learning Systems).
Rephrasing this from a business perspective would lead to the starting question for machine learning:
Do you face a (1) business-relevant and (2) complex problem which can be (3) represented by data?
Business-relevance: Can you become more profitable
Complexity: Is data available in volume or complexity that heuristics likely fail?
Data representation: Is data extensive and consistent enough for a model to identify patterns?
Machine learning requires detailed and consistent data to make it work. There is no silver bullet.
Identify fraud in data. Preventing fraud comes down to data. How well you can track web sessions, impressions and click paths becomes central in dealing with fraud. Without tracking data, chances are low to do anything about it. Even third-party anti-fraud software might be ineffective since it solves generic use cases by design. Different firms attract different fraud types. Third party solutions cannot possibly know the specifics on a complex range of products or services and their vulnerabilities. Therefore, a tailored approach built together with internal domain experts such as product or marketing could effectively prevent fraud.
Machines or humans. One major challenge is to differentiate between bots and humans. Nowadays, bots have become better at mimicking human behavior. At worst they come in thousands to interact with whatever incentive you expose to the outside world. Due to the sheer traffic volume it is infeasible to manually analyze patterns. You have to fend off algorithms with algorithms. The depth of data you have, directly determines whether you have any chance to deploy machine learning.
Honeypots for bots. One way to label bots is to use so-called honeypots to lure bots. Honeypots are elements on your website invisible to humans, like hidden buttons or input forms. Bots scrape the website source-code to discover elements they can interact with. If your website tracking logs an interaction with these hidden elements, you clearly identify bots. You can see a summary of the honeypot method in this article by PerimeterX: How to use honeypots to lure and trap bots.
As bots act more like humans, their digital footprint blends in with anyone else’s. This poses a major challenge to any data-driven solution and there is no magic solution to that. Creating honeypots that lure bots could be one way forward. Along the lines of Gartner’s Market Guide for Online Fraud Detection, a vendor on bot detection would be the safest bet, such as Arkose Labs, Imperva, GeeTest or Human to name a few.
Conclusion
This article talks about the rise of novel fraud types that modern fraud detection faces. Firms increasingly expose their offerings in the digital ecosystem which leads to losses due to fraud. Policy loopholes and marketing giveaways erode their digital budgets. For example, customers reaping signup bonuses multiple times with generic emails on the one hand, and sophisticated bots creating fake accounts that dilute your customer base on the other hand. Both forms lead to losses along the digital supply chain.
I personally find the world of fraud detection fascinating. It constantly changes where preventive technology and creative fraudsters move in tandem. With the rise of bots, fraud detection becomes more complex and difficult to do with conventional approaches. If you start on your fraud detection journey, I recommend you start thinking about how your company’s digital presence is reflected by the data you have. Web tracking needs to be deep enough to enable analytics or even machine learning.
At Solita we have the skillset to both build strategic roadmaps and create data solutions with our team of data experts. Feel free to reach out how we can help you on the data groundwork towards effective fraud detection.
Solita has received the Microsoft Azure Data, Analytics and AI Partner of Year award two times in a row, holds several Microsoft competencies, is Azure Expert MSP and has advanced specialization in Analytics on Microsoft Azure. These recognitions are granted by Microsoft and are based on the hard work Solitans have done in our projects. Let's find out what kind of services our Microsoft Azure practice offers and what it means in our daily work.
According to this study made by Solita’s Cloud unit, the most popular cloud services used by large Finnish companies are Microsoft Azure (82 %), Amazon Web Services (34 %) and Google Cloud Platform (27 %). Significant part of the respondents (43 %) are operating in multi-cloud environments, meaning they are using services from more than one provider.
Why is Azure so popular? From data services point of view, Azure offers mature services to create complex data platforms that can meet any requirement. Many organizations already utilize the Microsoft 365 and Dynamics 365 ecosystems and for them Azure is a justified technology choice for the cloud journey. In addition to these services, the Microsoft ecosystem includes Power Platform making it a comprehensive and mature platform for any kind of needs. It’s not surprising that during the last few years, we have seen a significant increase in the popularity of Azure services in the Nordics and in demand for Azure experts.
What kind of Azure-based deliveries has Solita done?
Combining data, tech and human insights is the bread and butter of our offering. When it comes to Azure-based data analytics solutions, we are proud of our works like this data platform that combines modern cloud technology and the on-premises world in a unique way, the IoT edge computing solution (video!) for forest harvesting, the streaming data solution to support operational decision-making in metro traffic, and this machine learning based real-time dashboard running on the Azure platform. Technologies cover Azure capabilities widely including e.g. Synapse Analytics, Azure Stream Analytics, Azure Databricks, Azure ML and Power BI.
In addition to the strong offering with Azure data services, our Cloud unit helps companies with the implementation of Azure cloud platforms. We have received the rare Microsoft Azure Expert Managed Services Provider certification. Check out also Solita CloudBlox, our modern managed cloud service.
What makes Solita the best Azure consultancy in northern Europe?
We put focus on finding the best solutions for our customers. Our approach is to look at the overall architecture, find suitable tools for different business use cases and build well-integrated solutions. We focus on the business objectives. We are not afraid of talking business and participating in refining the requirements with the customer. We have a strong emphasis on developing the skills of our people so that we have extensive knowledge of the solutions offered in the market and what works in different situations.
From an employee point of view we make a promise that at Solita you get to work with state of the art technology and delivery methods. In our projects we use agile practices and apply DataOps principles. What this means in practice is that we support project teams with standardized ways of working, utilize automation always when applicable, build solutions for continuous delivery and are adaptive to change when needed.
Solita has a strong culture of competence development
Solitans hold hundreds of Microsoft recognitions for passed certifications. Through our partnership with Microsoft we have access to Microsoft’s Enterprise Skills Initiative that offers interactive courses, certification preparation sessions and practice exams so we can improve our Azure skills and earn certifications. We encourage everyone to spend time on competence development to keep our skills up-to-date. In leading-edge technology projects we also have the possibility to collaborate and investigate solutions with Microsoft’s Black Belt professionals who have the deepest technology knowledge in these specific areas.
In addition, Solita has an internal program called Growth Academy that offers learning opportunities and competence development for all Solitans. Growth Academy makes learning more visible and we encourage everyone to develop their skills, learn and grow. Through Growth Academy we offer learning content for Azure for different certifications and learning paths for different roles. We also have active Slack communities where people share knowledge and ask questions.
In this blog, we will be talking about how technology has shifted from on-premises data centers to the cloud and from cloud to edge. Then, we will explain data fabric, introduce HPE Ezmeral Data Fabric and investigate its capabilities. Finally, we will talk about Edge AI with HPE Ezmeral Data Fabric.
To see what Edge AI is, we need to take a deeper look at the history of data processing over time.
The evolutions of data-intensive workloads
On-premises data centers
Back in 2000, almost everything was running locally in on-premises data centers. This means that everything from management to maintenance was on the company’s shoulders. It was fine but over time, when everything was getting more dependent on the internet, businesses faced some challenges. Here are some of the most important ones:
Infrastructure inflexibility
Over time, many new services and technologies are released and it should be taken into consideration that there might be a need to update the infrastructure or apply some changes to the services.
This can be challenging when it comes to hardware changes. The only solution seems to be purchasing the desirable hardware, then manual configuration. It can be worse if, at some point, we realize that the new changes are not beneficial. In this case, we have to start all over again!
This inflexibility causes wasting money and energy.
How about scaling on demand
A good business invests a lot of money to satisfy its customers. It can be seen from different angles but one of the most important ones always has the capacity to respond to the clients as soon as possible. This rule is also applied to the digital world: even loyal customers might change their minds if they see that the servers are not responding due to reaching their maximum capacity.
Therefore, there should be an estimation of the demand. The challenging part of this estimation is when this demand goes very high on some days during the year and one should forecast it. This demand forecasting has many aspects and it is not limited to the digital traffic from clients to servers. Having a good estimation of the demand for a particular item in the inventory is highly valuable.
Black Friday is a good example of such a situation.
There are two ways to cope with this unusual high demand:
Purchase extra hardware to ensure that there will be no delay in responding to the customers’ requests. This strategy seems to be safe, but it has some disadvantages. First, since the demand is high on only certain days, many resources are in idle mode for a long time. Second, the manual configuration of the newly purchased devices should be considered. All in all, it is not a wise decision financially.
Ignore that demand and let customer experience the downtime and wait for servers to become available. As it is easy to guess, it is not good for the reputation of the business.
This inflexibility is hard to address, and it gets worst over time.
Expansion
One might want to expand the business geographically. Along with marketing, there are some technical challenges.
The issue with the geographical expansion is the delay that is caused by the physical distance between the clients and servers. A good strategy is to distribute the data centers around the world and locate them somewhere closer to the customers.
The configuration of these new data centers along with the security, networking, and data management might be very hard.
Cloud Computing
Having the challenges of the on-premises data centers, the first evolution of data-intensive workloads happened around 2010 when third-party cloud providers such as Amazon Web Services and Microsoft Azure were introduced.
They provided companies with the infrastructure/services with the pay-as-you-go approach.
Cloud Computing solved many problems with on-premises approaches.
Risto and Timo have a great blog post about “Cloud Data Transformation” and I recommend checking it out to know more about the advantages of Cloud Computing.
Edge Computing
Over time, more applications have been developed, and Cloud Computing seemed to be the proper solution for them, but around 2020 Edge Computing got more and more attention as the solution for a group of newly-introduced applications that were more challenging.
The common feature of these applications was being time-sensitive. Cloud computing might act poorly in such cases since the data transmission to the cloud is time-consuming itself.
The basic idea of Edge Computing is to process data close to where it is produced. This decentralization has some benefits such as:
Reducing latency
As discussed earlier, the main advantage of Edge Computing is that it reduces the latency by eliminating the data transmission between its source and cloud.
Saving Network Bandwidth
Since the data is being processed in Edge Nodes, the network bandwidth can be saved. This matters a lot when the stream of data needs to be processed.
Privacy-preserving
Another essential advantage of Edge Computing is that the data does not need to leave its source. Therefore, it can be used in some applications where sending data to the cloud/on-perm data centers is not aligned with regulations.
AI applications
Many real-world use cases in the industry were introduced along with the advances in Artificial Intelligence.
There are two options for deploying the models: Cloud-based AI and Edge AI. There is also another categorization for training the model (centralized and decentralized) but it is beyond the scope of this blog.
Cloud-based AI
With this approach, everything happens in the cloud, from data gathering to training and deploying the model.
Cloud-based AI has many advantages, such as being cost-saving. It would be much cheaper to use cloud infrastructure for training a model rather than purchasing the physical GPU-enabled computers.
The workflow of such an application is that after the model is deployed, new unseen data from the business unit (or wherever the source of data is) will be sent to the cloud, the decision will be made there and it will be sent back to the business unit.
Edge AI
As you might have guessed, Edge AI addresses the time-sensitivity issue. This time, the data gathering and training of the model steps still happen in the cloud, but the model will be deployed on the edge nodes. This change in the workflow not only saves the network bandwidth but also reduces the latency.
Edge AI opens the doors to many real-time AI-driven applications in the industry. Here are some examples:
So far, we have discussed a bit about the concepts of Cloud/Edge computing, but as always, the story is different in real-world applications.
We talked about the benefits of cloud computing but it is important to ask these questions ourselves:
What would be the architecture of having such services in the Cloud/Edge?
What is the process of migration from on-prem to cloud? What are the challenges? How can we solve them?
How can we manage and access data in a unified manner to avoid data silos?
How can we orchestrate distributed servers or edge nodes in an optimized and secure way?
How about monitoring and visualization?
Many companies came up with their own solutions for the above questions with manual work but there is a need for a better way for a business to focus on creating values, rather than dealing with these issues. This is when Data Fabric comes into the game.
Data Fabric is an approach for managing data in an organization. Its architecture consists of a set of services that make accessing data easier regardless of its location (on-prem, cloud, edge). This architecture is flexible, secure, and adaptive.
Data Fabric can reduce the integration time, the maintenance time, and the deployment time.
Next, we will be talking about the HPE Ezmeral Data Fabric (Data Fabric is offered as a solution by many enterprises and the comparison between them is beyond the scope of this blog).
HPE Ezmeral Data Fabric
HPE Ezmeral Data Fabric is an Edge to Cloud solution that supports industry-standard APIs such as REST, S3, POSIX, and NFS. It also has an ecosystem package that contains many open-source tools such as Apache Spark and allows you to do data analysis.
You can find more information about the benefits of using HPE Ezmeral Data Fabric here.
As you can see, there is an eye-catching part named “Data Fabric Event Stream”. This is the key feature that allows us to develop Edge AI applications with the HPE Ezmeral Data Fabric.
Edge AI with HPE Ezmeral Data Fabric – application
An Edge AI application should contain at least one platform for orchestrating the broker cluster such as Kafka, some tools such as Apache Spark, and a data store. This might not be as easy as it seems, especially in large-scale applications when we have millions of sensors, thousands of edge sites, and the cloud.
Fortunately, with HPE Ezmeral Data Fabric Event Stream, this task can be done much easier. We will go through it by demonstrating a simple application that we developed.
Once you set up the cluster, the only thing you need to do is to install the client on the edge nodes, connect them to the cluster (by a simple line maprlogin command), and then enable the services that you want to use.
For the event stream, it is already there, and again it just needs a single command for creating a stream and then creating topics in it.
For the publisher (also called producer), you need to just send the data from any source to the broker, and for the subscriber (also called consumer) the story is the same.
For using open-source tools such as Apache Spark (or in our case Spark Structure Streaming), you just need to install them on the mapr client, and the connection between the client and the cluster will be automatically established. So you can run a script in edge nodes and access data in the cluster.
Storing data is again as simple as the previous ones. The table creation can be done with a single command, and storing it is also straightforward.
Conclusion
To sum up, Edge AI has a promising future, and leveraging it with different tools such as Data Fabric can be a game changer.
Thank you for reading this blog! I would also like to invite you to our talk about the benefits of Edge Computing in Pori on 23/09/2022!
Data development is following a few steps behind the evolution of car manufacturing. Waterfall development is like chain manufacturing. Agile team works like a manufacturing cell. Metadata aligns with digital twin for smart manufacturing. This is the next step in the evolution.
A lot of companies are making a digital transformation with ambitious goals for creating high value outcomes using data and analytics. Leveraging siloed data assets efficiently is one of the biggest challenges in doing analytics at scale. Companies often struggle to provide an efficient supply of trusted data to meet the growing demand for digitalization, analytics, and ML. Many companies have realised that they must resolve data silos to overcome these challenges.
Business Solution
Metadata enables finding, understanding, management and effective use of data. Metadata should be used as a foundation and as an accelerator for any development of data & analytics solutions. Poor metadata management has been one of the key reasons why the large “monolith” data warehouses have failed to deliver their promises.
Data Development Maturity Model
Many companies want to implement a modern cloud-based data ecosystem. They want to migrate away from the old monolith data warehouses. It is important to know the history of how the monoliths were created to avoid repeating the old mistakes.
The history of developing data ecosystems – data marts, lakes, and warehouses – can be illustrated with the below maturity model & analogy to car manufacturing.
Data development maturity model
1. Application Centric Age
In the application centric age, the dialogue between business & IT related mostly to functionality needs. Realising the functionality would require some data, but the data was treated just as a by-product of the IT applications and their functionality.
Artisan workshop – created customised solutions that are tuned for a specific use case & functionality – like custom cars or data marts – which were not optimised from data reuse (semantics & integrity etc.) point of view.
Pitfalls – Spaghetti Architecture
Projects were funded, planned, and realised in organisational/ departmental silos. Data was integrated for overlapping point solutions for tactical silo value. Preparation of data for analytics is about 80% of the effort and this was done repeatedly.
As a consequence of lack of focus on data, the different applications are integrated with “point-to-point” integrations resulting in so-called “spaghetti architecture”. Many companies realised that this was very costly as IT was spending a very large part of their resources in connecting different silos with this inefficient style.
From data silos to efficient sharing of data
2. Data Centric Age
In the data centric age companies wanted to share data for reuse. They wanted to save costs, improve agility, and enable business to exploit new opportunities. Data became a business enabler and a key factor into the dialogue between business & IT. Data demand & supply needed to be optimised.
Companies also realised that they need to develop a target architecture – like enterprise data warehouse (EDW) – that enables them to provide data for reuse. Data integration for reuse required common semantics & data models to enable loose coupling of data producers and data consumers.
Pitfalls – Production line for “monolith” EDW
Many companies created a production line – like chain production or waterfall data program – for building analytical ecosystems or EDWs. Sadly, most of these companies got into the data centric age with poor management of metadata. Without proper metadata management the objective of data reuse is hard to achieve.
There are a lot of studies that indicate that 90% of process lead time is spent on handovers between responsibilities. Within data development processes metadata is handed over between different development phases and teams spanning across an entire lifecycle of a solution.
In waterfall development splits the “production line” into specialised teams. It includes a lot of documentation overhead to orchestrate the teams and many handovers between the teams. In most cases metadata was left in different silo tools and files (Excel & SharePoint). Then the development process did not work smoothly as the handovers lacked quality and control. Handing over to an offshore team added more challenges.
Sometimes prototyping was added, which helped to reduce some of these problems by increasing user involvement in the process.
Waterfall development model with poor metadata management
The biggest headache is however the ability to manage the data assets. Metadata was in siloed tools and files, there were no integrated views of the data assets. To create integrated views the development teams invented yet another Excel sheet.
Poor metadata management made it very hard to:
understand DW content without the help of experts
create any integrated views of the data assets that enable reusing data
analyse impacts of the changes
understand data lineage to study root causes of problems
Because of slow progress these companies made a lot of shortcuts (technical debt) that started violating the target architecture, which basically meant that they started drifting back to the application centric age.
The beautiful data centric vision resulted in a lot of monolithic EDWs that are hard to change, provide slow progress and have increasing TCO. They have become legacy systems that everyone wants to migrate away.
3. Metadata Centric Age
Leading companies have realised that one of the main pitfalls of the data centric age was lack of metadata management. They have started to move into the “metadata centric age” with a fundamental way of working change. They apply metadata driven development by embedding usage of collaborative metadata capabilities into the development processes. All processes are able to consume and contribute into a common repository. Process handovers are simplified, standardised, integrated, and even automated.
Metadata driven development brings the development of modern data warehouses into the level of “smart manufacturing”.
Metadata enables collaboration around shared knowledge
Smart manufacturing enables us to deliver high quality products with frequent intervals and with batch size one. Smart manufacturing uses digital twins to manage designs, processes, and track quality of the physical products. It also enables scaling because knowledge is shared even between distributed teams and manufacturing sites.
Thanks to open access article: Development of a Smart Cyber-Physical Manufacturing System in the Industry 4.0 Context
Metadata driven development uses metadata as the digital twin to manage data product designs and the efficiency of the data supply chain. Common metadata repository which is nowadays branded as Data Catalog centralises knowledge, reduces dependency on bottleneck resources and enables a scalable development.
Metadata driven data supply chain produces data products through a life cycle where the artefacts evolve through conceptual, logical, physical, and operational stages. That also reflects the metadata needs in different stages.
Metadata driven data supply chain
Data Plan & Discovery act as a front end of the data supply chain. That is the place where business plans are translated into data requirements and prioritised into a data driven roadmap or backlog. This part of the data supply chain is a perfect opportunity window for ensuring cross functional alignment and collaboration using common semantics and a common Data Catalog solution. It gives a solid start for the supply of trusted data products for cross functional reuse.
Once the priority is confirmed and the feasibility is evaluated with data discovery, we have reached a commitment point from where the actual development of the vertical slices can continue.
DataOps automation enables smart manufacturing of data products. It enables highly optimised development, test and deployment practices required for frequent delivery of high-quality solution increments for user feedback and acceptance.
DataOps enables consistent, auditable, repeatable & scalable development. More teams – even in distributed locations – can be added to scale development. Solita has experience of forming agile teams that each are serving a certain business function. The team members are distributed into multiple countries, but they all share the same DataOps repository. This enables transparent & automatically documented architecture.
Example of transparent & automatically documented architecture with ADE
Learn more about Solita DataOps with Agile Data Engine (ADE):
Stay tuned for more blogs about “Smart Manufacturing”.
This blog is the first blog in the series. It focused on the maturity model and explained how the large monolith data warehouses were created. It just briefly touched on the metadata driven development. There is a lot more to tell in that.
After a decade in my previous profession, I felt it was time for a change. I used to be a senior level expert, so making this kind of a change was exciting but also a bit terrifying. The Data Academy was ideal, because I felt it would better support my transition. After my studies, I applied to the Data Academy and I was accepted.
Our Data Academy group had future data platform engineers, future master data management engineers and me, the future visual Analytics consultant. Everyone would learn a bit about each role, giving an introductory level to the topics. Solita’s internal experts held hybrid lessons, which meant real-life knowledge combined with expert tips. Regardless of your career path, the topics will be important to you at some point in your data career.
The best part of the Academy was the network that it offered to me. Firstly, I had my fellow academians. Secondly, I got a good look at all the departments and met colleagues. During the Academy, I met over 70 Solitans and got to know colleagues in different offices.
“The best part of the Academy was the network that it offered to me.”
Growing as a specialist
After the Academy I dedicated my time to self-studies: Power BI and Azure certificates were my first targets, but I also continued my AWS studies, together with the Mimmit Koodaa community.
I will learn a lot through my work as well because all the work projects are different in Solita. Most importantly, I can commit to self-study time for my work weeks. I am participating in internal training, covering agile methods, Tableau, and service design. These courses will contribute to my work in the future.
The Solita community has warmly welcomed me. My colleagues are helpful, and they share their knowledge eagerly. I received work straight after the Academy, even quite demanding tasks, but there are always senior colleagues to turn to and discuss the matters.
Three tips on how to become an Analytics Consultant
Of course, you need to understand the core fundamentals of data, and how you can utilize data in business. Here is a great example, of how data creates value.
Finally, notable topics to learn are cloud technologies, databases and data modelling. They are strongly present in our everyday work.
I could not be happier with my choice to join Solita via the Academy, and I sincerely recommend it!
Are you interested in attending Data academy? Read more here!
Meet Johanna, Tuomas and Tero! Our Consultants, who all work with data analysis and visualizations. Let’s map out their journey at Solita and demystify the work of Analytics Consultants!
All three have had different journeys to become an Analytics Consultant. Tuomas has a business degree and Tero started his career working with telecommunications technology. Johanna however found her way to visualizations quite young: “I created my first IBM Cognos reports as a summer trainee when I was 18 and somehow, I ended up studying Information Systems Science.” It has been, however, love at first sight for all of them. Now they work at Solita’s Data Science and Analytics Cell.
What is a typical Analytics Consultant’s workday like?
The interest in versatile work tasks combines our Analytics Consultants. Tuomas describes himself as “a Power BI Expert”. His days go fast by designing Power BI phases, modelling data, and doing classical pipeline work. “Sometimes I’d say my role has been something between project or service manager.”
Tero in the other hand is focusing on report developing and visualizations. He defines backlogs, develops metadata models, and holds client workshops.
Johanna sees herself as a Data Visualization Specialist, who develops reports for her customers. She creates datasets, and defines report designs and themes. “My work also includes data governance and the occasional maintenance work,” Johanna adds.
All three agree that development work is one of their main tasks. “I could say that a third of my time goes to development,” Tuomas estimates. “In my case I would say even half of my time goes to development,” Tero states.
Power BI is the main tool that they are using. Microsoft Azure and Snowflake are also in daily use. Tools vary in projects, so Tuomas highlights that “it is important to understand the nature of different tools even though one would not work straight with them”.
What is the best part of an Analytics Consultant’s work?
The possibility to work with real-life problems and creating concrete solutions brings the most joy to our consultants. “It is really satisfying to provide user experiences, which deliver the necessary information and functionality, which the end users need to solve their business-related questions,” Johanna clarifies her thoughts.
And of course, collaborating with people keeps our consultants going! Tuomas estimates that 35% of his time is dedicated to stakeholder communications: he mentions customer meetings, but also writing documentations, and creating project defining, “specs”, with his customers.
Our consultants agree that communication skills are one of the key soft skills to master when desiring to become an Analytics Consultant! Tuomas tells, that working and communicating with end-users has always felt natural to him.
Tero is intrigued by the possibility of working with different industries: “I will learn how different industries and companies work, what kind of processes they have and how legislation affects them. This work is all about understanding the industry and being customer-oriented.”
“Each workday is different and interesting! I am dealing with many different kinds of customers and business domains every day.”
When asked, what keeps the consultants working with visualizations, they all ponder for a few seconds. “A report, which I create, will provide straight benefit for the users. That is important to me,” Tuomas sums up his thoughts. “Each workday is unique and interesting! I am dealing with many different customers and business domains every day,” Johanna answers. Tero smiles and concludes: “When my customers get excited about my visualization, that is the best feeling!”
How are our Analytics Consultants developing their careers?
After working over 10 years with reporting and visualizations, Tero feels that he has found his home: “This role feels good to me, and it suits my personality well. Of course, I am interested in getting involved with new industries and learning new tools, but now I am really contented!”
Tuomas, who is a newcomer compared to Tero, has a strong urge to learn more: “Next target is to get a deeper and more technical understanding of data engineering tools. I would say there are good opportunities at Solita to find the most suitable path for you.”
Johanna has had different roles in her Solita journey, but she keeps returning to work with visualizations: “I will develop my skills in design, and I would love to learn a new tool too! This role is all about continuous learning and that is an important capability of an Analytics Consultant!”
“I would say there are good opportunities at Solita to find the most suitable path for you.”
How to become an excellent Analytics Consultant? Here are our experts’ tips:
Johanna: “Work together with different stakeholders to produce the best solutions. Do not be afraid to challenge the customer, ask questions or make mistakes.”
Tuomas: “Be curious to try and learn new things. Don’t be afraid to fail. Ask colleagues and remember to challenge customer’s point of view when needed.”
Tero: “Be proactive! From the point of view of technical solutions and data. Customers expect us to bring them innovative ideas!”
Tableau Conference (TC22) was held last week in person in Las Vegas (with virtual participation possibility). Majority of the introduced new features and functionalities were related to data preparation & modeling, easy and automated data science (business science as Tableau calls it), and Tableau Cloud management & governance capabilities. Tableau is on its journey from a visual analytics platform to a full scale end-to-end analytics platform.
In the keynote Tableau CEO Mark Nelson emphasised the role of both Tableau and Salesforce user communities to drive change with data: there are over 1M Tableau Datafam members and over 16M Salesforce Trailblazers. Once again, the importance of data for businesses and organisations was highlighted. But the viewpoint was data skills – or lack of them – and data cultures more than technologies. Mark Nelson underlined the meaning of cloud saying 70% of new customers start their analytical journey in the cloud. One of the big announcements was rebranding Tableau Online to Tableau Cloud and introducing plenty of new features to it.
Taking account the new features introduced at TC22 Tableau platform includes good data preparation and modelling capabilities with many connectors to a variety of data sources, services and APIs. Tableau’s visual analytics and dashboarding capabilities are already one of best in the market. In TC21 last year Tableau talked a lot about Slack integration and embedding to boost collaboration and sharing of insights. At the moment, effort is put especially to democratize data analytics for everyone despite gaps in the data skills. This is done using autoML type of functionalities to automatically describe and explain data, show outliers, create predictions and help to build and act on scenarios. Also the cloud offering with better governance, security and manageability was a high priority.
Next I’ll go through the key features introduced in TC22 and also list functionalities presented in TC21 to understand the big picture. More info about TC21 released features can be found in a previous blog post: A complete list of new features introduced at the Tableau Conference 2021. These feature lists don’t contain all the features included in previous releases but the ones mentioned in TC21.
Note: All the images are created using screenshots from the TC22 Opening Keynote / Devs on Stage session and Tableau new product innovations blog post. You can watch the sessions at any time onTableau site.
In TC22 there weren’t too many features related to workbook authoring. The only bigger announcement was the new image role to enable dynamic images in visualizations. These could be for example product images or any other images that can be found via a url link in the source data. From TC21 there are still a couple of very interesting features waiting to be released, I’m especially waiting for dynamic dashboard layouts.
Introduced in TC22
Image role: Dynamically render images in the viz based on a link field in the data.
Introduced in TC21 (but not yet released)
Dynamic Dashboard Layouts (~2022 H1): Use parameters & field values to show/hide layout containers and visualizations.
Visualization Extensions (~2022 H2): Custom mark types, mark designer to fine tune the visualization details, share custom viz types.
Introduced in TC21 (and already released)
Multi Data Source Spatial Layers (2021.4): Use data from different data sources in different layers of a single map visualization.
Redesigned View Data (2022.1): View/hide columns, reorder columns, sort data, etc.
Workbook Optimizer (2022.1): Suggest performance improvements when publishing a workbook.
Image role example to dynamically render images presented in TC22. Side note: have to appreciate the “Loves Tableau: True” filter.
Augmented analytics & understand data
For this area there were a couple of brand new announcements and more info about a few major functionalities already unveiled in TC21. Data stories is an automated feature to create descriptive stories about data insights in a single visualization. Data stories explains what data and insights is presented in the visualization, explanation changes dynamically when data is filtered or selected in the viz. With the data orientation pane the author can partly automate the documentation of dashboard and visualizations. It shows information about data fields, applied filters, data outliers and data summary, and possible links to external documentation.
Example of automatically created descriptive data story within a dashboard presented in TC22.
Few originally in TC21 introduced features were also mentioned in TC22. Model Builder is a big step toward guided data science. It will help to build ML-model driven predictions fully integrated within Tableau. It’s based on the same technology as Salesforce’s Einstein Analytics. Scenario planner is a functionality to build what-if-analyses to understand different options and outcomes of different decisions.
Introduced in TC22
Data Stories (beta in Tableau Cloud): Dynamic and automated data story component in Tableau Dashboard. Automatically describes data contents.
Data orientation pane: Contain information about dashboard and fields, applied filters, data outliers and data summary, and links to external resources.
Model Builder: Use autoML to build and deploy predictive models within Tableau. Based on Salesforce’s Einstein platform.
Scenario Planner: Easy what-if-analysis. View how changes in certain variables affect target variables and how certain targets could be achieved.
Introduced in TC21 (but not yet released)
Data Change Radar (~2022 H1): Alert and show details about meaningful data changes, detect new outliers or anomalies, alert and explain these.
Multiple Smaller Improvements in Ask Data (~2022 H1): Contact Lens author, Personal pinning, Lens lineage in Catalog, Embed Ask Data.
Explain the Viz (~2022 H2): Show outliers and anomalies in the data, explain changes, explain mark etc.
Introduced in TC21 (and already released)
Ask Data improvements (2022.1): Phrase builder already available, phrase recommendations available later this year.
Collaborate, embed and act
In TC21 collaboration and Slack integration were one of the big development areas. In TC22 there wasn’t much new about this topic, but Tableau actions were again demonstrated as a way to build actionable dashboards. Also the possibility to share dashboards publicly for unauthenticated non-licenced users was shown again in TC22. This functionality is coming to Tableau Cloud later this year.
Introduced in TC22
Tableau Actions: Trigger actions outside Tableau, for example Salesforce Flow actions. Support for other workflow engines will be added later.
Publicly share dashboards (~2022 H2): Share content via external public facing site to give access to unauthenticated non-licenced users, only Tableau Cloud.
Introduced in TC21 (but not yet released)
3rd party Identity & Access Providers: Better capabilities to manage users externally outside Tableau.
Embeddable Web Authoring: No need for desktop when creating & editing embedded contents, full embedded visual analytics.
Embeddable Ask Data
Introduced in TC21 (and already released)
Connected Apps (2021.4): More easily embed to external apps, create secure handshake between Tableau and other apps.
Tableau search, Explain Data and Ask Data in Slack (2021.4)
Tableau Prep notifications in Slack (2022.1)
Data preparation, modeling and management
My personal favourite of the new features can be found here. Shared dimensions enable more flexible multi-fact data models where multiple fact tables can relate to shared dimension tables. This feature makes the logical data model layer introduced a couple of years ago more comprehensive and very powerful. Tableau finally supports creation of enterprise level data models that can be leveraged in very flexible ways and managed in a centralized manner. Another data model related new feature was Table extensions that enable use of Python and R scripts directly in the data model layer.
Shared dimensions enabled multi-fact data source example presented in TC22.
There are also features to boost data source connectivity. Web Data Connector 3.0 makes it easier to connect different web data sources, services and API’s. One important new data source is AWS S3 that will enable connection directly to the data lake layer. Also Tableau Prep is getting few new functionalities. Row number column and null value cleaning are rather small features. Multi-row calculations instead are a bit bigger thing, although the examples Tableau mentioned (running totals and moving averages) might not very relevant in data prep cause these usually must take into account filters and row level security and therefore these calculations must often be done at runtime.
Introduced in TC22
Shared dimensions: Build multi-fact data models where facts relate to many shared dimensions,
Web data connector 3.0: Easily connect to web data and APIs, for example to AWS S3, Twitter etc.
Table extensions: Leverage python and R scripts in the data model layer.
Insert row number and clean null values in Prep: Easily insert row number column and clean & fill null values.
Multi-row calculations in Prep: Calculate for example running total or moving average in Tableau Prep.
New AWS data sources: Amazon S3, Amazon DocumentDB, Amazon OpenSearch, Amazon Neptune.
Introduced in TC21 (but not yet released)
Data Catalog Integration: Sync external metadata to Tableau (from Collibra, Alation, & Informatica).
Tableau Prep Extensions: Leverage and build extension for Tableau Prep (sentiment analysis, OCR, geocoding, feature engineering etc.).
Introduced in TC21 (and already released)
Virtual Connections (2021.4): Centrally managed and reusable access points to source data with single point to define security policy and data standards.
Centralized row level security (2021.4): Centralized RLS and data management for virtual connections.
Parameters in Tableau Prep (2021.4): Leverage parameters in Tableau Prep workflows.
Tableau Cloud management
Rebranding Tableau Online to Tableau Cloud and a bunch of new management and governance features in it was one important area of TC22. Tableau Cloud can now be managed as a whole with multi-site management. Security has already been a key area when moving to cloud and now Tableau finally supports customer managed encryption keys (BYOK). From a monitoring point of view both activity log and admin insights provide information how Tableau Cloud and contents in it are used.
Introduced in TC22
Multi-site management for Tableau Cloud: Manage centrally all Tableau Cloud sites.
Customer managed encryption keys (later 2022): BYOK (Bring Your Own Keys).
Activity Log: More insights on how people are using Tableau, permission auditing etc.
Admin Insights: Maximise performance, boost adoption, and manage contents.
Tableau Cloud Admin Insights example presented in TC22.
Tableau Server management
There weren’t too many new features in Tableau Server management, I guess partly because of the effort put into Tableau Cloud Management instead. However, Tableau Server auto-scaling was mentioned again and it will be coming soon starting with backgrounder auto-scaling.
Introduced in TC22
Auto-scaling for Tableau Server (2022 H1): Starting with backgrounder auto-scaling for container deployments.
Introduced in TC21 (but not yet released)
Resource Monitoring Improvements (~2022 H1): Show view load requests, establish new baseline etc.
Backgrounder resource limits (~2022 H1): Set limits for backgrounder resource consumption.
Introduced in TC21 (and already released)
Time Stamped log Zips (2021.4)
Tableau ecosystem & Tableau Public
Last year in the TC21 Tableau ecosystem and upcoming Tableau Public features had a big role. This year there wasn’t much new in this area but still the Tableau exchange and accelerators were mentioned and shown in the demos a couple of times.
Introduced in TC21 (but not yet released)
Tableau Public Slack Integration (~2022 H1)
More connectors to Tableau Public (~2022 H1): Box, Dropbox, OneDrive.
Publish Prep flows to Tableau Public: Will there be a Public version for Tableau Prep?
Tableau Public custom Channels (~2022 H1): Custom channels around certain topics.
Introduced in TC21 (and already released)
Tableau exchange: Search and leverage shared extensions, connectors, more than 100 accelerators. Possibility to share dataset may be added later on.
Accelerators: Dashboard starters for certain use cases and source data (e.g. call center analysis, Marketo data, Salesforce data etc.). Can soon be used directly from Tableau.
Want to know more?
If you are looking for more info about Tableau read our previous blog posts:
In a world driven by data, Machine Learning plays the most central role. Not everyone has the knowledge and skills required to work with Machine Learning. Moreover, the creation of Machine Learning models requires a sequence of complex tasks that need to be handled by experts.
Automated Machine Learning (AutoML) is a concept that provides the means to utilise existing data and create models for non-Machine Learning experts. In addition to that, AutoML provides Machine Learning (ML) professionals ways to develop and use effective models without spending time on tasks such as data cleaning and preprocessing, feature engineering, model selection, hyperparameter tuning, etc.
Before we move any further, it is important to note that AutoML is not some system that has been developed by a single entity. Several organisations have developed their own AutoML packages. These packages cover a broad area, and targets people at different skill levels.
In this blog, we will cover low-code approaches to AutoML that require very little knowledge about ML. There are AutoML systems that are available in the form of Python packages that we will cover in the future.
At the simplest level, both AWS and Google have introduced Amazon Sagemaker and Cloud AutoML, which are low-code PAAS solutions for AutoML. These cloud solutions are capable of automatically building effective ML models. The models can then be deployed and utilised as needed.
Data
In most cases, a person working with the platform doesn’t even need to know much about the dataset they want to analyse. The work carried out here is as simple as uploading a CSV file and generating a model. We will take a look at Amazon Sagemaker as an example. However, the process is similar in other existing cloud offerings.
With Sagemaker, we can upload our dataset to an S3 bucket and tell our model that we want to be working with that dataset. This is achieved using Sagemaker Canvas, which is a visual, no code platform.
The dataset we are working with in this example contains data about electric scooters. Our goal is to create a model that predicts the battery level of a scooter given a set of conditions.
Creating the model
In this case, we say that our target column is “battery”. We can also see details of the other columns in our dataset. For example, the “latitude”and “longitude” columns have a significant amount of missing data. Thus, we can choose not to include those in our analysis.
Afterwards, we can choose the type of model we want to create. By default, Sagemaker suggests creating a model that classifies the battery level into 3 or more categories. However, what we want is to predict the battery level.
Therefore, we can change the model type to “numeric” in order to predict battery level.
Thereafter, we can begin building our models. This is a process that takes a considerable amount of time. Sagemaker gives you the option to “preview” the model that would be built before starting the actual build.
The preview only takes a few minutes, and provides an estimate of the performance we can expect from the final model. Since our goal is to predict the battery level, we will have a regression model. This model can be evaluated with RMSE (root mean square error).
It also shows the impact different features have on the model. Therefore, we can choose to ignore features that have little or no impact.
Once we have selected the features we want to analyse, we select “standard build” and begin building the model. Sagemaker trains the dataset with different models along with multiple hyperparameter values for each model. This is done in order to figure out an optimal solution. As a result, the process of building the model takes a long time.
Once the build is complete, you are presented with information about the performance of the model. The model performance can be analysed in further detail with advanced metrics if necessary.
Making predictions
As a final step, we can use the model that was just built to make predictions. We can provide specific values and make a single prediction. We can also provide multiple data in the form of a CSV file and make batch predictions.
If we are satisfied with the model, we can share it to Amazon Sagemaker Studio, for further analysis. Sagemaker Studio is a web-based IDE that can be used for ML development. This is a more advanced ML platform geared towards data scientists to perform complex tasks with Machine Learning models. The model can be deployed and made available through an endpoint. Thereafter, existing systems can use these endpoints to make their predictions.
We will not be going over Sagemaker Studio as it is something that goes beyond AutoML. However, it is important to note that these AutoML cloud platforms are capable of going beyond tabular data. Both Sagemaker and Google AutoML are also capable of working with images, video, as well as text.
Conclusion
While there are many useful applications for AutoML, its simplicity comes with some drawbacks. The main issue that we noticed about AutoML especially with Sagemaker is the lack of flexibility. The platform provides features such as basic filtering, removal, and joining of multiple datasets. However, we could not perform basic derivations such as calculating the distance traveled using the coordinates, or measuring the duration of rentals. All of these should have been simple mathematical derivations based on existing features.
We also noticed issues with flexibility for the classification of battery levels. The ideal approach to this would be to have categories such as “low”, “medium”, and “high”. However, we were not allowed to define these categories or their corresponding threshold values. Instead, the values were chosen by the system automatically.
The main purpose of AutoML is to make Machine Learning available to those who are not experts in the field. As a benefit of this approach, this also becomes useful to people like data scientists. They do not have to spend a large amount of time and effort selecting an optimal model, and hyperparameter tuning.
Experts can make good use of low code AutoML platforms such as Sagemaker to validate any data they have collected. These systems could be utilised as a quick and easy way to produce well-optimised models for new datasets. The models would measure how good the data is. Experts also get an understanding about the type of model and hyperparameters that are best suited for their requirements.
Data classification is an important process in enterprise data governance and cybersecurity risk management. Data is categorized into security and sensitivity levels to make it easier to keep the data safe, managed and accessible. The risks for poor data classification are relevant for any business. By not following the data confidentiality policies and also preferably automation, an enterprise can expose its trusted data to unwanted visitors by a simple human error or accident. Besides the governance and availability points of view, proper data classification policies provide security and coherent data life cycles. They are also a good way to prove that your organization follows compliance standards (e.g. GDPR) to promote trust and integrity.
In the process of data classification, data is initially organized into categories based on type, contents and other metadata. Afterwards, these categories are used to determine the proper level of controls for the confidentiality, integrity, and availability of data based on the risk to the organization. It also implies likely outcomes if the data is compromised, lost or misused, such as the loss of trust or reputational damage.
Though there are multiple ways and labels for classifying company data, the standard way is to use high risk, medium risk and low/no risk levels. Based on specific data governance needs and the data itself, organizations can select their own descriptive labels for these levels. For this blog, I will label the levels confidential (high risk), sensitive (medium risk) and public (low/no risk). The risk levels are always mutually exclusive.
Confidential (high risk) data is the most critical level of data. If not properly controlled, it can cause the most significant harm to the organization if compromised. Examples: financial records, IP, authentication data
Sensitive (medium risk) data is intended for internal use only. If medium risk data is breached, the results are not disastrous but not desirable either. Examples: strategy documents, anonymous employee data or financial statements
Public (low risk or no risk) data does not require any security or access measures. Examples: publicly available information such as contact information, job or position postings or this blog post.
High risk can be divided into confidential and restricted levels. Medium risk is sometimes split into private data and internal data. Because a three-level design may not fit every organization, it is important to remember that the main goal of data classification is to assess a fitting policy level that works with your company or your use case. For example, governments or public organizations with sensitive data may have multiple levels of data classification but for a smaller entity, two or three levels can be enough. Guidelines and recommendations for data classification can be found from standards organizations such as International Standards Organization (ISO 27001) and National Institute of Standards and Technology (NIST SP 800-53).
Besides standards and recommendations, the process of data classification itself should be tangible. AWS (Amazon Web Services) offers a five-step framework for developing company data classification policies. The steps are:
Establishing a data catalog
Assessing business critical functions and conduct an impact assessment
Labeling information
Handling of assets
Continuous monitoring
These steps are based on general good practices for data classification. First, a catalog for various data types is established and the data types are grouped based on the organization’s own classification levels.
The security level of data is also determined by its criticality to the business. Each data type should be assessed by its impact. Labeling the information is recommended for quality assurance purposes.
AWS uses services like Amazon SageMaker (SageMaker provides tools for building, training and deploying machine learning models in AWS) and AWS Glue (AWS Glue is an ETL event-driven service that is used for e.g. data identification and categorization) to provide insight and support for data labels. After this step, the data sets are handled according to their security level. Specific security and access controls are provided here. After this, continuous monitoring kicks in. Automation handles monitoring, identifies external threats and maintains normal functions.
Automating the process
The data classification process is fairly complex work and takes a lot of effort. Managing it manually every single time is time-consuming and prone for errors. Automating the classification and identification of data can help control the process and reduce the risk of human error and breach of high risk data. There are plenty of tools available for automating this task. AWS uses Amazon Macie for machine learning based automation. Macie uses machine learning to discover, classify and protect confidential and sensitive data in AWS. Macie recognizes sensitive data and provides dashboards and alerts for visual presentation of how this data is being used and accessed.
Amazon Macie dashboard shows enabled S3 bucket and policy findings
After selecting the S3 buckets the user wants to enable for Macie, different options can be enabled. In addition to the frequency of object checks and filtering objects by tags, the user can use custom data identification. Custom data identifiers are a set of criteria that is defined to detect sensitive data. The user can define regular expressions, keywords and a maximum match distance to target specific data for analysis purposes.
As a case example, Edmunds, a car shopping website, promotes Macie and data classification as an “automated magnifying glass” into critical data that would be difficult to notice otherwise. For Edmunds, the main benefits of Macie are better visibility into business-critical data, identification of shared access credentials and protection of user data.
Though Amazon Macie is useful for AWS and S3 buckets, it is not the only option for automating data classification. A simple Google search offers tens of alternative tools for both small and large scale companies. Data classification is needed almost everywhere and the business benefit is well-recognized.
For more information about this subject, please contact Solita Industrial.
Industries have resorted to use AI partner services to fuel their AI aspirations and quickly bring their product and services to market. Choosing the right partner is challenging and this blog lists a few pointers that industries can utilize in their decision making process.
Large investments in AI clearly indicate industries have embraced the value of AI. Such a high AI adoption rate has induced a severe lack of talented data scientists, data engineers and machine learning engineers. Moreover, with the availability of alternative options, high paying jobs and numerous benefits, it is clearly an employee’s market.
Market has a plethora of AI consulting companies ready to fill in the role of AI partners with leading industries. Among such companies, on one end are the traditional IT services companies, who have evolved to provide AI services and on the other end are the AI start-up companies who have backgrounds from academia with a research focus striving to deliver the top specialists to industries.
Considering that a company is willing to venture into AI with an AI partner. In this blog I shall enumerate what are the essentials that one can look for before deciding to pick their preferred AI partner.
AI knowledge and experience: AI is evolving fast with new technologies developed by both industries and academia. Use cases in AI also span multiple areas within a single company. Most cases usually fall in following domains: Computer vision, Computer audition, Natural language processing, Interpersonally intelligent machines, routing, and motion and robotics. It is natural to look for AI partners with specialists in the above areas.
It is worth remembering that most AI use cases do not require AI specialists or super specialists and generalists with wide AI experience could well handle the cases.
Also specialising in AI alone does not suffice to successfully bring the case to production. The art of handling industrial AI use cases is not trivial and novice AI specialists and those that are freshly out of University need oversight. Hence companies have to be careful with such AI specialists with only academic experience or little industrial experience.
Domain experience: Many AI techniques are applicable across cases in multiple domains. Hence it is not always necessary to seek such consultants with domain expertise and often it is an overkill with additional expert costs. Additionally, too much domain knowledge can also restrict our thinking in some ways. However, there are exceptions when domain knowledge might be helpful, especially when limited data are available.
A domain agnostic AI consultant can create and deliver AI models in multiple domains in collaboration with company domain experts.
Thus making them available for such projects would be important for the company.
Problem solving approach This is probably the most important attribute when evaluating an AI partner. Company cases can be categorised in one of the following silo’s:
Open sea: Though uncommon, it is possible to see few such scenarios, when the companies are at an early stage of their AI strategy. This is attractive for many AI consultants who have the freedom to carve out an AI strategy and succeeding steps to boost the AI capabilities for their clients. With such freedom comes great responsibility and AI partners for such scenarios must be carefully chosen who have a long standing position within the industry as a trusted partner.
Straits: This is most common when the use case is at least coarsely defined and suitable ML technologies are to be chosen and take the AI use case to production. Such cases often don’t need high grade AI researchers/scientists but any generalist data scientist and engineer with the experience of working in an agile way can be a perfect match.
Stormy seas: This is possibly the hardest case, where the use case is not clearly defined and also no ready solution is available. The use case definition is easy to be defined with data and AI strategists, but research and development of new technologies requires AI specialists/scientists. Hence special emphasis should be focused on checking the presence of such specialists. It is worth noting that AI specialists availability alone does not guarantee that there is a guaranteed conversion to production.
Data security: Data is the fuel for growth for many companies. It is quite natural that companies are extremely careful with safeguarding the data and their use. Thus when choosing an AI partner it is important to look and ask for data security measures that are currently practised with the AI partner candidate organisation. In my experience it is quite common that AI specialists do not have data security training. If the company does not emphasise on ethics and security the data is most likely stored by partners all over the internet, (i.e. personal dropbox and onedrive accounts) including their private laptops.
Data platform skills: AI technologies are usually built on data. It is quite common that companies have multiple databases and do not have a clear data strategy. AI partners with inbuilt experience in data engineering shall go well, else a separate partner would be needed.
Design thinking: Design thinking is rarely considered a priority expertise when it comes to AI partnering and development. However this is probably the hidden gem beyond every successful deployment of AI use case. AI design thinking adopts a human centric approach, where the user is at the centre of the entire development process and her/his wishes are the most important. The adoption of the AI products would significantly increase when the users problems are accounted for, including AI ethics.
Blowed marketing: Usually AI partner marketing slides boast about successful AI projects. Companies must be careful interpreting this number, as often major portions of these projects are just proof of concepts which have not seen the light of day for various reasons. Companies should ask for the percentage of those projects that have entered into production or at least entered a minimum viable product stage.
Above we highlight a few points that one must look for in an AI partner, however what is important over all the above is the market perception of the candidate partner, and as a buyer you believe there is a culture fit, they understand your values, terms of cooperation, and their ability to co-define the value proposition of the AI case. Also AI consultants should stand up for their choices and not shy away from pointing to the infeasibility and lack of technologies/data to achieve desired goals set for AI use cases fearing the collapse of their sales.
Finding the right partner is not that difficult, if you wish to understand Solita’s position on the above pointers and looking for an AI partner don’t hesitate to contact us.
Author: Karthik Sindhya, PhD, AI strategist, Data Science, AI & Analytics,
Tel. +358 40 5020418, karthik.sindhya@solita.fi
Have you ever wondered how much value a picture can give your business? Solita participated in a state-of-the-art computer vision workshop given by Amazon Web Services in Munich. We built an anomaly detection pipeline with AWS's new managed service called Lookout for Vision.
On a more fundamental level, computer vision at the edge enables efficient quality control and evaluation of manufacturing quality. Quickly detecting manufacturing anomalies means that you can take corrective action and decrease costs. If you have pictures, we at Solita have the knowledge to turn those to value generating assets.
Building the pipeline
At the premises we had a room filled with specialised cameras and edge hardware for running neural networks. The cameras were Basler’s 2D grayscale cameras and an edge computer: Adlink DLAP-301 with the MXE-211 gateway. All the necessary components to build an end-to-end working demo.
We started the day by building the training pipeline. With Adlink software, we get a real-time stream from the camera to the computer. Furthermore, we can integrate the stream to an S3 bucket. When taking a picture, it automatically syncs it to the assigned S3 bucket in AWS. After creating the training data, you simply initiate a model in the Lookout for Vision service and point to the corresponding S3 bucket and start training.
Lookout for Vision is a fully managed service and as a user you have little control over configuration. In other words, you do make a compromise between configurability and speed to deployment. Since the service has little configuration, you won’t need a deep understanding of machine learning to use it. But knowing how to interpret the basic performance metrics is definitely useful for tweaking and retraining the model.
After we were satisfied with our model we used the AWS Greengrass service to deploy it to the edge device. Here again the way Adlink and AWS are integrated makes things easier. Once the model was up and running we could use the Basler camera stream to get a real-time result on whether the object had anomalies.
Short outline of the workflow:
Generate data
Data is automatically synced to S3
Train model with AWS Lookout for Vision, which receives data from the S3 bucket mentioned above
Evaluate model performance and retrain if needed
Once model training is done, deploy it with AWS Greengrass to the edge device
Get real-time anomaly detection.
All in all this service abstracts away a lot of the machine learning part, and the focus is on solving a well defined problem with speed and accuracy. We were satisfied with the workshop and learned a lot about how to solve business problems with computer vision solutions.
If you are interested in how to use Lookout for Vision or how to apply it to your business problem please reach out to us or the Solita Industrial team.
Is your data management like a messy dinner table, where birds took “data silverware” to their nests? More technically, is your data split to organizational silos and applications with uncontrolled connections all around? This causes many problems for operations and reporting in all companies. Better data management alone won’t solve the challenges, but it has a huge impact.
Kirjoittaja:Pauliina Mäkilä Data Engineer, Data Platforms
Kirjoittaja:Anttoni TukiaData Engineer, Master Data Management
While the challenges may seem like a nightmare, beginning to tackle them is easier than you think. Let our Data Academians, Anttoni and Pauliina, share their experiences and learnings. Though they’ve only worked at Solita for a short time, they’ve already got a hang of data management.
What does data management mean?
Anttoni: Good data management means taking care of your organization’s know-how and distributing it to employees. Imagine your data and AI being almost as person, who can answer questions like “how is our sales doing?” and “what are the current market trends?”. You probably would like to have the answer in a language you understand and with terms that everyone is familiar with. Most importantly, you want the answer to be trustworthy. With proper data management, your data could be this person.
Pauliina: For me data management compares to taking care of your closet, with socks, shirts and jeans being your data. You have a designated spot for each clothing type in your closet and you know how to wash and care for them. Imagine you’re searching for that one nice shirt you wore last summer when it could be hidden under your jeans. Or better yet, lost in your spouse or children’s closet! And when you finally find the shirt, someone washed it so that it shrank two sizes – it’s ruined. The data you need is that shirt and with data management you make sure it’s located where it should be, and it’s been taken care of so that it’s useful.
How do challenges manifest?
Anttoni: Bad data management costs money and wastes valuable resources in businesses. As an example of a data quality related issue from my experience: if employees are maybe not allowed, but technically able, to enter poor data into a system, like CRM or WMS, they will most likely do that at some point. This leads to poor data quality, which causes operational and sometimes technical issues. The result is hours and hours of cleaning and interpretation work that the business could have avoided with a few technical fixes.
Pauliina: The most profound problem I’ve seen bad data management cause is the hindering of a data-driven culture. This happened in real life when presenters collected material for a company’s management meeting from different sources and calculated key KPI’s differently. Suddenly, the management team had three contradicting numbers for e.g. marketing and sales performance. Each one of them came from a different system and had different filtering and calculation applied. In conclusion, decision making was delayed because no-one trusted each other’s numbers. Additionally, I had to check and validate them all. This wouldn’t happen if the company properly manages data.
Bringing the data silverware from silos to one place and modelling and storing it appropriately will clean the dinner table. This contributes towards meeting the strategic challenges around data – though might not solve them fully. The following actions will move you towards a better data management and thus your goals.
How to improve your data management?
Pauliina & Anttoni:
We could fill all five bullets with communication. Improving your company’s data management is a change in organization culture. The whole organization will need to commit to the change. Therefore, take enough time to explain why data management is important.
Start with analyzing the current state of your data. Pick one or two areas that contribute to one or two of your company or department KPIs. After that, find out what data you have in your chosen area: what are the sources, what data is stored there, who creates, edits, and uses the data, how is it used in reporting, where, and by whom.
Stop entering bad data. Uncontrolled data input is one of the biggest causes of poor data quality. Although you can instruct users on how they should enter data to the system, it would be smart to make it impossible to enter bad data. Also pay attention to who creates and edits the data – not everyone needs the rights to create and edit.
Establish a single source of truth, SSOT. This is often a data platform solution, and your official reporting is built on top of it. In addition, have an owner for your solution even when it requires a new hire.
Often you can name a department responsible for each of your source system’s data. Better yet, you can name a person from each department to own the data and be a link between the technical data people and department employees.
About the writers:
My name is Anttoni, and I am a Data Engineer/4th year Information and Knowledge Management student from Tampere, Finland. After Data Academy, I’ll be joining the MDM-team. I got interested in data when I saw how much trouble bad data management causes in businesses. Consequently, I gained a desire to fix those problems.
I’m Pauliina, MSc in Industrial Engineering and Management. I work at Solita as a Data Engineer. While I don’t have education in data, I’ve worked in data projects for a few years in SMB sector. Most of my work circled around building official reporting for the business.
The application to the Solita Data academy is now open!
Are you interested in attending Data academy? The application is now open, apply here!
A digital twin is a virtual model of a physical object or process. Such as production lines and buildings. When sensors collect data from a device, the sensor data can be used to update a “digital twin” copy of the device’s state in real time. So it can be used for things like monitoring and diagnostics.
There are different types of digital twins for designing and testing parts or products, but let’s focus more on system and process related twins.
For a simple example, you have a water heater connected to a radiator. Your virtual model gets data from the heater’s sensors and knows the temperature of the heater. The radiator on the other hand has no sensor attached to it. But the link between the heater and radiator is in your digital model. Now you can see virtually that when the heater is malfunctioning, your radiator gets colder. Not only sensors are connected to your digital twin, but manuals and other documents are also. So you can view the heater’s manual right there in the dashboard.
Industrial point of view benefits
We are living in an age when everything is connected to the internet and industrial devices are no different. Huge amounts of data is flowing from devices to different endpoints. That’s where digital twins will show its strengths by connecting all those dots to form a bigger picture about process and assets. Making it easier to understand complex structures. It’s also a two-way street, so digital twins can generate more useful data or update existing data.
Many times industrial processes consist of other processes that aren’t connected to each other. Like that lonely motor spinning without real connection to other parts of the process. Those are easily forgotten, even if it is a crucial part of the process. When complexity grows there will be even more loose ends that aren’t connected to each other.
Predictive maintenance lowers maintenance costs.
Productivity will improve, because reduced downtime and improved performance via optimization.
Testing in the digital world before real world applications.
Allows you to make more informed decisions at the beginning of the process.
Continuous improvement through simulations.
Digital twins offer great potential for predicting the future instead of analyzing the past. Real world experiments aren’t a cost effective way to test ideas. With a digital counterpart you can cost effectively test ideas and see if you missed something important.
Quick overview of creating digital twins with AWS IoT Twinmaker
In workspace you create entities that are digital versions of devices. Those entities are connected with components that will handle data connections. Components can connect to AWS Sitewise or other data source via AWS lambda. When creating a component you define it in JSON format and it can inherit other components.
Next step is to get your CAD models uploaded to the Twinmaker. When you have your models uploaded, you can start creating 3D scenes that will visualize your digital twin. Adding visual rules like tags that change their appearance can be done in this phase.
Now digital twin is almost ready and the only thing to do is connect Grafana with Twinmaker and create a dashboard in Grafana. Grafana has a plugin for Twinmaker that helps with connecting 3D scenes and data.
There are many other tools for creating digital twins and what to use, depends on the needs.
Sensor data analytics is a fast-growing trend in the industrial domain. Audio, despite its holistic nature and huge importance to human machine operators, is usually not utilised to its full potential. In this blog post we showcase some of these possibilities through a research experiment case study conducted as part of the IVVES research project.
On a cold winter morning in December 2021 in the Solita Research R&D group we packed our bags with various audio recording equipment and set our sights on a local industrial machine rental company. We wanted to answer a simple question: do machines speak? Our aim was to record sound from multiple identical industrial grade machines (which turned out to be 53 kg soil compactors) in order to investigate whether we could consistently distinguish them based on their sound alone. In other words, just as each human has a very unique voice, our hypothesis was that the same would be true for machines, that is, we wanted to construct an audio fingerprint. This could then be used not only to identify each machine, but to detect if a particular machine’s sound starts to drift (indicating a potential incoming fault) or to check whether the fingerprint matches before and after renting out the machine, for example.
It is always important to keep the business use case and real-world limitations in mind when designing solutions to data-based (no pun intended) problems. In this case, we identified the following important aspects in our research problem:
The solution would have to be lightweight, capable of being run on the edge with limited computational resources and internet connectivity.
Our methods should be robust against interference from varying levels of background noise and variances in how users hold the microphone when recording a machine’s sound.
It would be important to be able to communicate our results and analysis to domain experts and eventual end users. Therefore, we should focus on physically meaningful features over arbitrary ones and on explainable algorithms over black boxes.
The set-up of our experiment should be planned to ensure high-quality uncontaminated data that at the same time would serve to produce the best possible research outcome while being representative of the data we might expect for a productionalised solution.
In this blog post we will focus on points 1. and 3. and we’ll return to 2. and 4. in a follow-up post.
Analysing Sound
We are surrounded by a constant stream of sound mixed together from a multitude of sources: cars speeding along on the street, your colleague typing on their keyboard or a dog barking at songbirds outside your window. Yet, seemingly without any effort, your brains can process this jumbled up signal and tell you exactly what is happening around you in real-time. Our hope is that we could somehow imitate this process by developing audio analysis methods with similar properties.
Figure 1. On the left is the waveform for the sound produced by the author uttering “hello”. On the right is the corresponding spectrogram.
It is quite futile to try to analyse raw signals of this type directly: each sound source emits vibrations in multiple frequencies and these get combined over all the different sources into one big mess. Luckily there is a classical mathematical tool which can help us to figure out the frequency content of an audio (or any other type) wave: the Fourier transform. By computing the Fourier transform for consecutive small windows of the input signal, we can determine how much of each frequency is present at a given time. We can then arrange this data in the form of a matrix, where the rows correspond to different frequency ranges and columns are consecutive time steps (typically in the order of 10-20 milliseconds each). Hence, the entries of the matrix tell you how much of each frequency is present at that particular moment. The resulting matrix is called a spectrogram, which we can visualise by colouring the values based on their magnitudes: dark for values close to zero with lighter colours signifying higher intensity. In Figure 1 you can see an example of the waveform produced by the author uttering “hello” and the resulting spectrogram. The process of transforming the original signal to its constituent frequencies and studying this decomposition is called spectral analysis.
From Raw to Refined Features
The raw frequency data by itself is still not the most useful. This is because different audio sources can of course produce sounds in overlapping frequency ranges. In particular, a single machine can have multiple vibrating parts which each produce their distinct sound. Instead, we should try to extract features that are meaningful to the problem at hand—classification of fuel powered machines in this case. There are many spectral features that could be useful (for some inspiration you can check out our public Google Colab notebooks or the documentation of librosa, a popular Python audio analysis library).
In this blog we’ll take a slightly different approach. Our goal is to be able to compare the frequency data of different machines at two points in time, but this won’t be efficient (let alone robust) if we rely on raw frequencies. This is because of background noise and the varying operating speed of the engines (think about how the pitch of the sound is affected by how fast the engine is running). Instead, we want to pool together individual frequencies in a way that would allow us to express our high-dimensional spectrogram in terms of a handful of distinct frequency range combinations.
Figure 2. Each principal component is some combination of frequencies with different weights.
Luckily there is, yet again, a classical mathematical tool which does exactly this: principal component analysis (PCA). If you’ve taken a course in linear algebra then this is nothing more than matrix diagonalisation, but it has become one of the staple methods of dimensionality reduction in the machine learning world. The output of the PCA-algorithm is a set of principal components each of which is some combination of the original frequencies. In Figure 2 we plot the weight of each frequency for two principal components: in the first component we have positive weights for all but the lowest of frequencies while for the second one the midrange has negative weights. An additional reason for why PCA is an attractive method for our problem is that the resulting frequency combinations will be linearly independent (i.e. you cannot obtain one component by adding together multiples of the other components). This is a crude imitation of our earlier observation that a single machine can have multiple separate parts producing sound at the same time. The crux of the algorithm is that in order to faithfully represent our original data, we only have to keep a small number of these principal components thus effectively reducing the dimensionality of our problem to a more manageable scale.
Structure in Audio
Now that we have a sequence of low-dimensional feature vectors that capture the most important aspects of the original signal, we can try to start finding some structure in this stream of data. We do this by computing the self-similarity matrix (SSM) [1], whose elements are the pairwise distances between our feature vectors. We can visualise the resulting matrix as a heat map where the intensity of the colour corresponds to the distance (with black colour signifying that the features are identical), see Figure 3.
Figure 3. The (i, j)-entry of the self-similarity matrix (on the right) is given by the distance between the feature vectors at times ti and tj. Black colour corresponds to zero distance i.e. the vectors being equal.
In Figure 4 you can see a part of an SSM for one of the soil compactors. By definition, time flows along its main diagonal (blue arrow). Short segments of the audio that are self-similar (i.e. the nature of the sound doesn’t change) appear as dark rectangles along the diagonal. For each rectangle on the main diagonal, the remaining rectangles on the same row show how similar the other segments are to the one in question. If you pause here for a moment and gather your thoughts, you might notice that there are two types of alternating segments (of varying duration) in this particular SSM.
Figure 4. Self-similarity matrix for one of the soil compactors. Time flows down the main diagonal on which the dark rectangles signify self-similar segments.
Do machines speak?
We have covered a lot of technical material, but we are almost done! Now we understand how to uncover patterns in audio, but how can we use this information to tell apart our four machines? The more ML-savvy readers might be tempted to classify the SSMs with e.g. convolutional neural networks. This might certainly work well, but we would lose sight of one of our aims which was to keep the method computationally light and simple. Hence we proceed with a more traditional approach.
Recall that we have constructed a separate SSM for each machine. For each of the resulting matrices, we can now look at small blocks along the diagonal (see Figure 5) and figure out what they typically look like. If we scale the results to [-1, 1], we obtain a small set of fingerprints (we also refer to these as kernels) for each machine. Just like you (hopefully) have ten fingers each with its own unique fingerprint, a machine can also have more than one acoustic fingerprint. We have visualised a few of these for one of the machines in Figure 5.
Figure 5. Fingerprints (on the right) for a single machine computed from its self-similarity matrix on the left.
We are now ready to return back to the machine rental shop to test if our solution works! Once we arrive, we follow the set of instructions below in order to determine which machine is which (see Figure 6 for an animation of this process):
Turn on the machine and record its sound.
While the machine is running, compute the self-similarity matrix on the fly.
Slide the fingerprints for each machine along the diagonal and compute their activations (by summing the elementwise product).
The fingerprint which reacts to the sound the most tells you which machine is running.
Figure 6. By computing the activations of each fingerprint on freshly recorded audio, we can find out which machine has been returned to the rental shop.
And that’s it! We saw how something seemingly natural, the sounds surrounding us, can produce very complex signals. We learned how to begin to understand this mess via spectral analysis, which led us to uncover structure hidden in the data—something our brain does with ease. Finally, we used this structure to produce a solution to our original business use case of classifying machine sounds.
I hope you have enjoyed this little excursion into the mathematical world of audio data and colourful graphs. Maybe next time you start your car (or your soil compactor) you might wonder whether you could recognise its sound from your neighbour’s identical one and what it is about their sounds that lets your brain achieve that.
If you are interested in applying advanced sensor data (audio or otherwise) analytics in your business context please reach out to me or the Solita Industrial team.


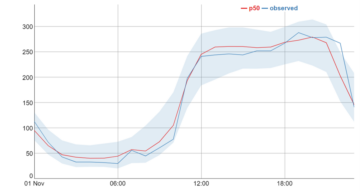








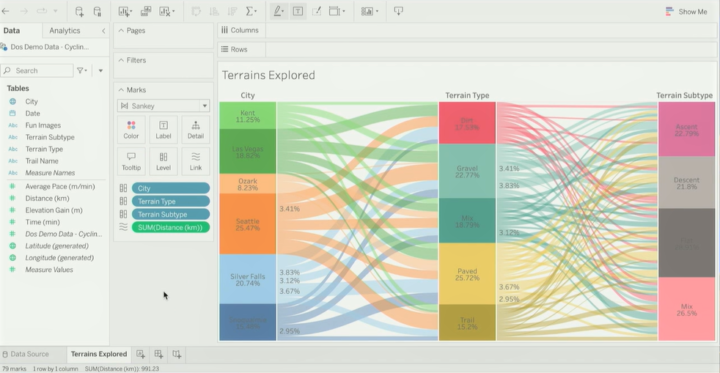
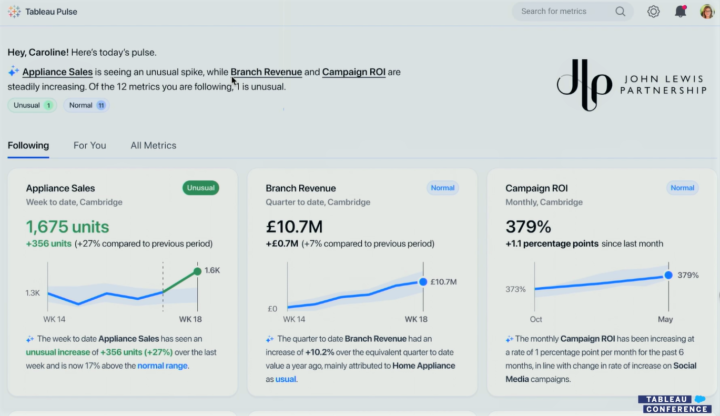
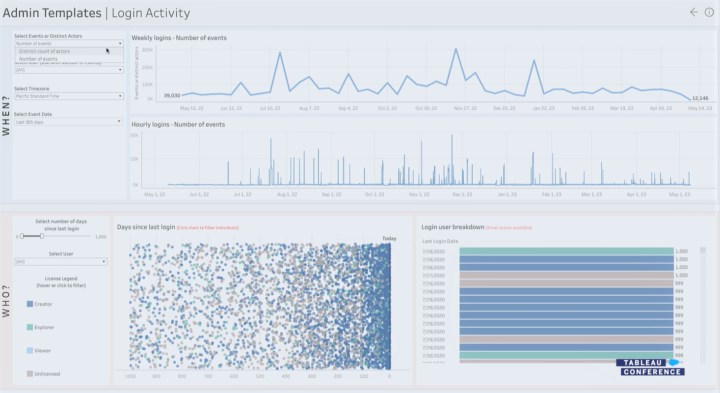




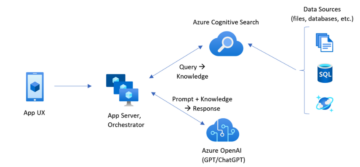






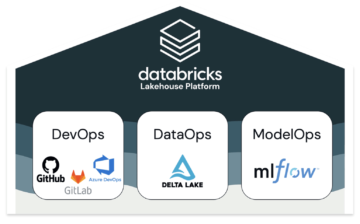
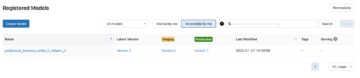













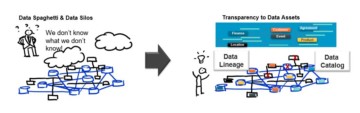

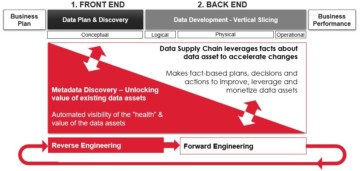
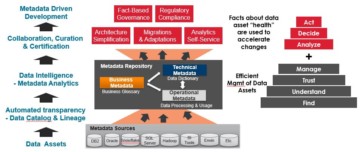
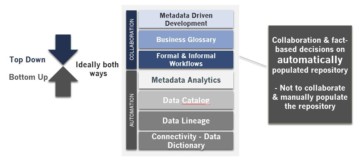



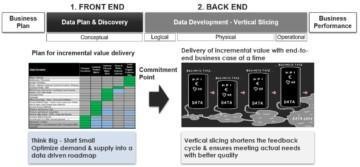

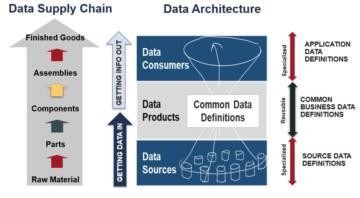


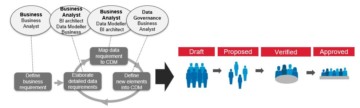
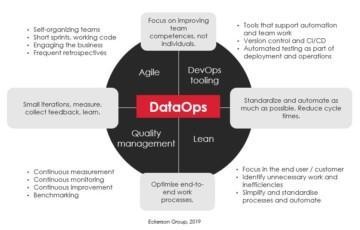














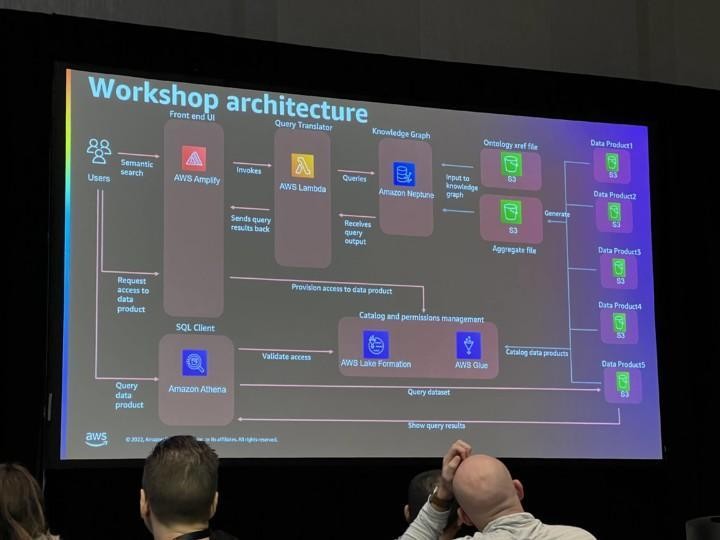

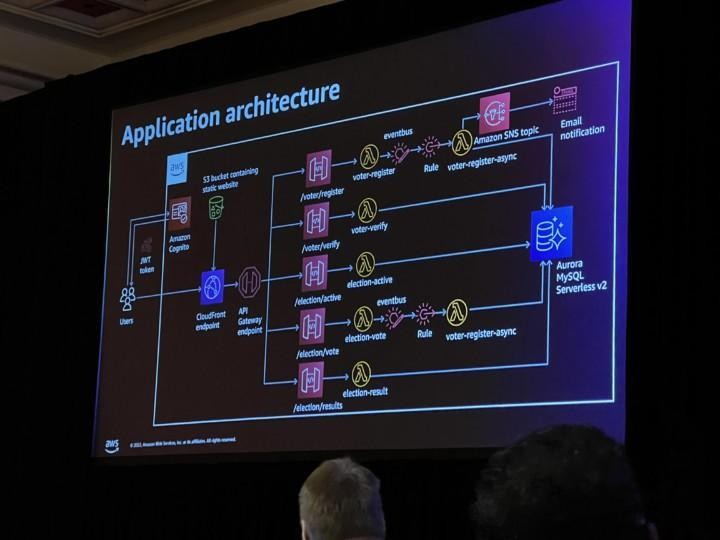


























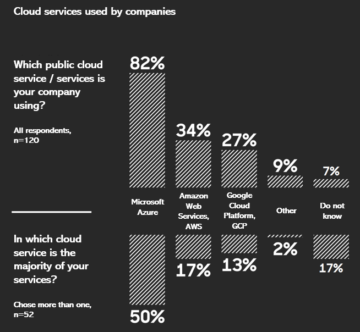



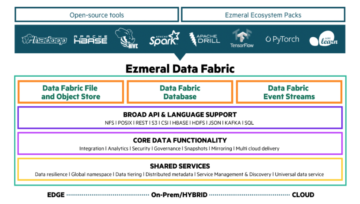
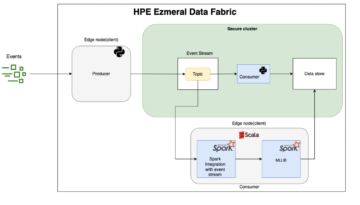













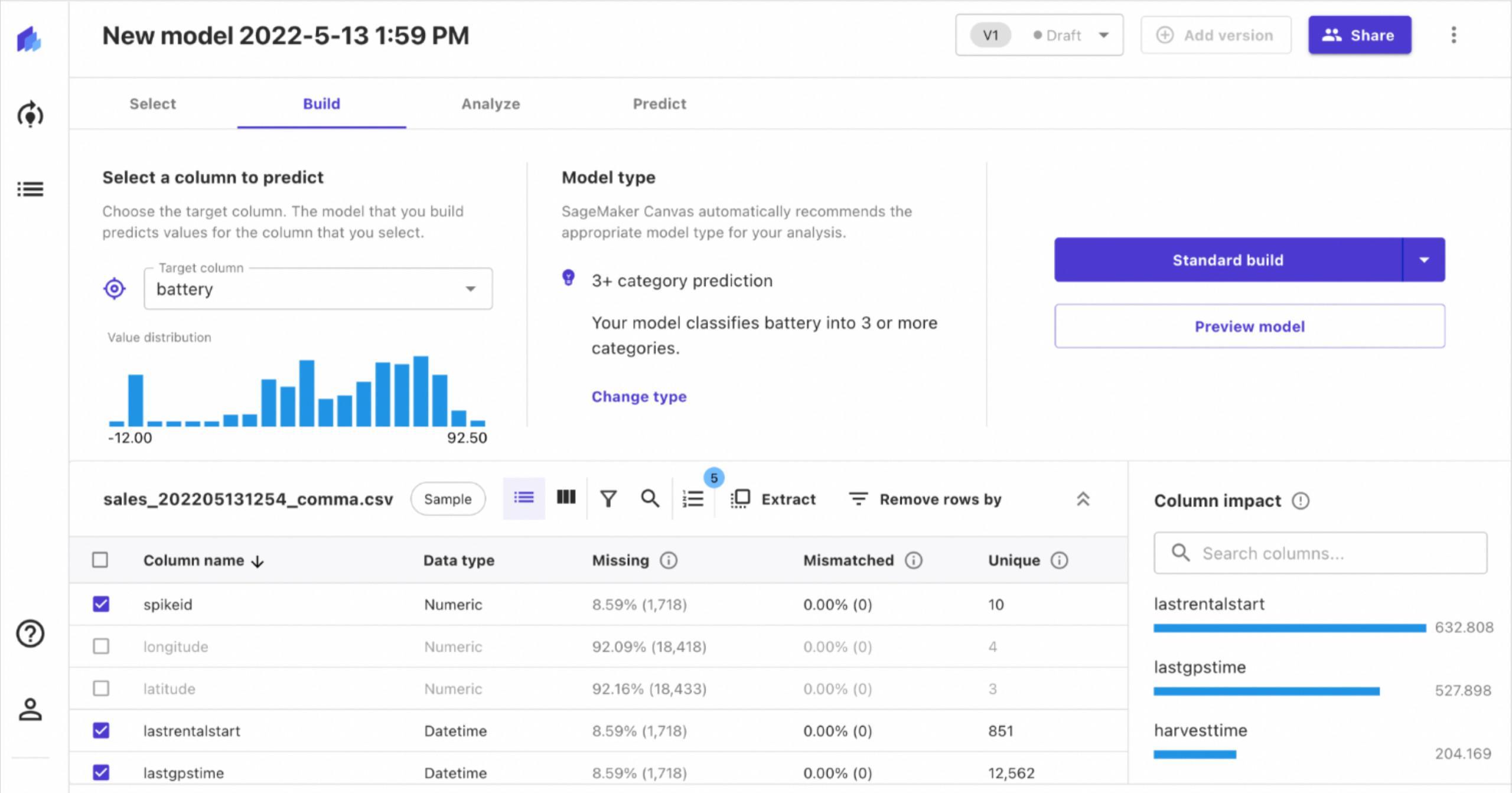
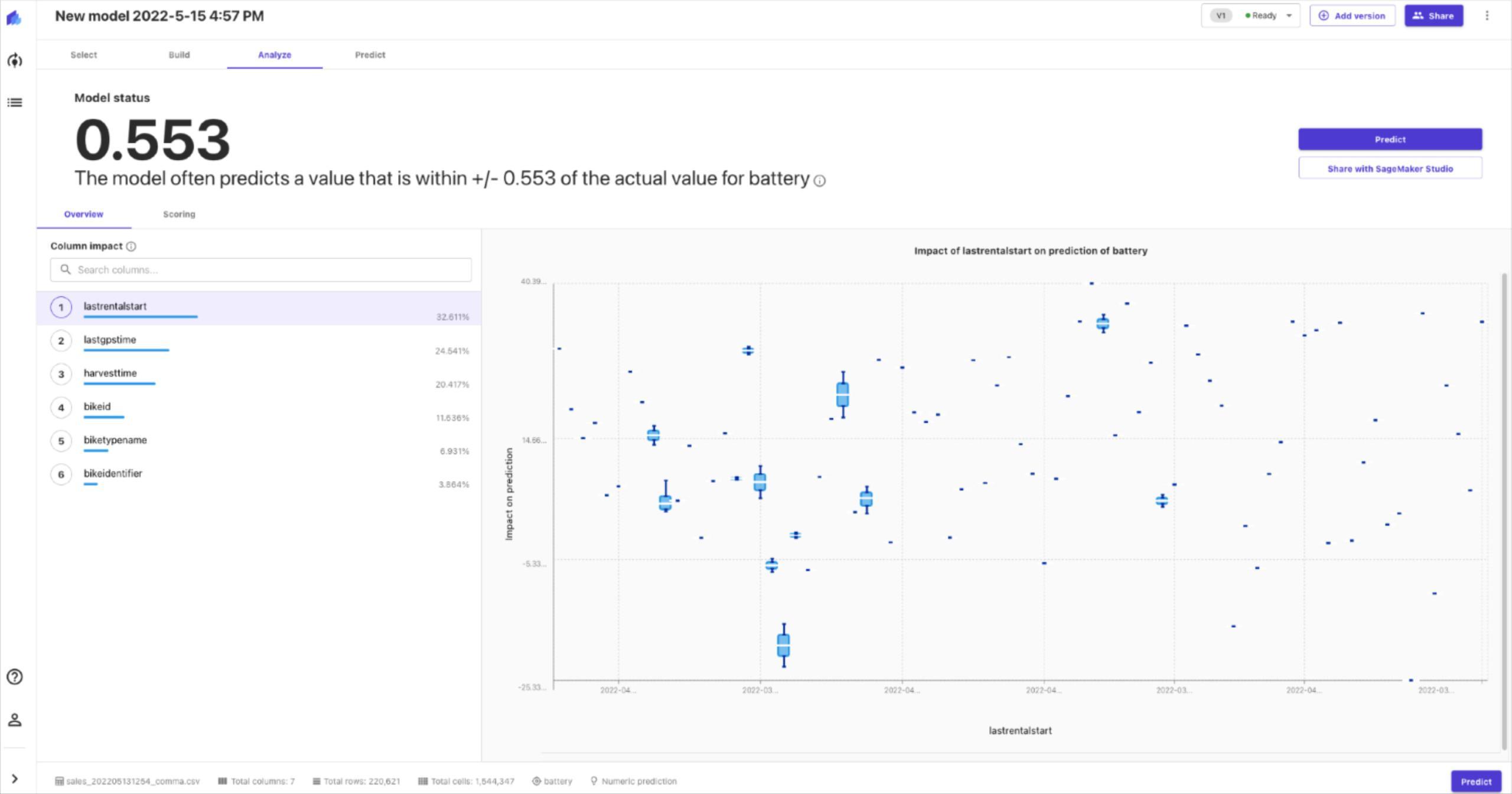
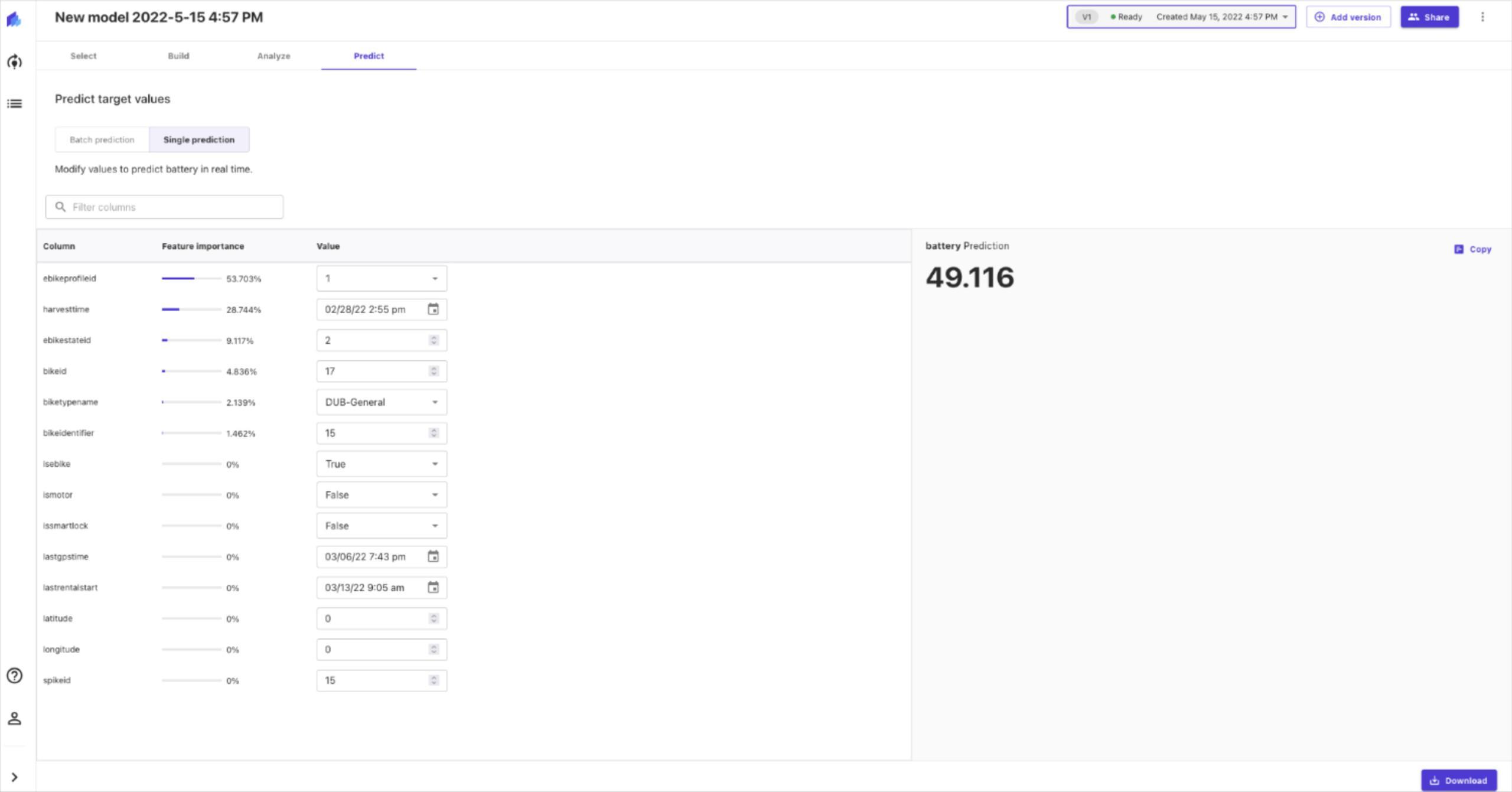















 radiator is in your digital model. Now you can see virtually that when the heater is malfunctioning, your radiator gets colder. Not only sensors are connected to your digital twin, but manuals and other documents are also. So you can view the heater’s manual right there in the dashboard.
radiator is in your digital model. Now you can see virtually that when the heater is malfunctioning, your radiator gets colder. Not only sensors are connected to your digital twin, but manuals and other documents are also. So you can view the heater’s manual right there in the dashboard.